本文主要是介绍Redis之旁路缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Redis之旁路缓存
Redis作为缓存中间件早已深入人心,但我们有没有想过Redis为什么能作为缓存呢?Redis到底怎样使用缓存呢?本篇文章详细聊聊。
Redis为什么能作为缓存
聊Redis为什么能作为缓存前先需要清楚缓存的作用,我们在很多场景都有接触过缓存就如Redis本身的输入输出缓存、复制缓冲区、复制积压缓存区等等,又如操作系统本身的LLC,page cache缓存等等,这些缓存的主要作用是什么呢?是在一个多层次系统中平衡上下级系统的速度差异。
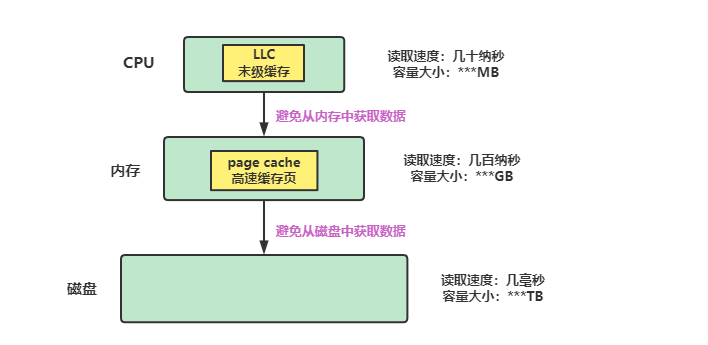
这里以操作系统为例说明,操作系统的存储结构一般为CPU、内存、磁盘三大块,其中CPU读取速度最快只有几十纳秒,内存读取需要100多纳秒,而磁盘的读取速度是毫秒,这样看可能没有什么对比效果,我们看下下面的单位换算,内存和磁盘的速度差异可是差了数量级的。
1秒 = 1000 毫秒 = 1000000 微秒 = 1000000 纳秒根据木桶定理,一个木桶装多少水是由木桶的最短板决定,所以在操作系统上如果处理数据,磁盘的读取过慢,CPU将空闲大量的时间,这显然是不合理的,所以引入了缓存的概念。
-
CPU中的末级缓存即LLC用于平衡CPU和内存间的速度差异,避免每次从内存中取数据。
-
内存中高速缓存页即page cache,用于平衡内存和磁盘中的速度差异,避免每次都从磁盘中取数据。
看到这里就可以得到缓存的一些特征如下
-
第一在一个多层次系统上缓存一定是一个快速的系统,这样才能平衡层次系统的速度差异。
-
第二CPU、内存中包含的缓存比它需要平衡的系统小,如LLC就不可能存下内存中的所有数据,所以我们需要有内存淘汰的思想。
到这里缓存的特性就聊完了,那么Redis是否符合呢?显然是可以的
-
Redis运行在内存中而且存在丰富的数据结构以及应用了多路复用IO模型,速度上远超其它数据库,符合第一点速度快的要求。
-
Redis本身自带内存淘汰机制,能根据淘汰规则自动淘汰键值,符合内存淘汰要求。
旁路缓存使用
使用缓存一般的操作都是
-
读取数据前先从Redis中读取。
-
如果读取数据在缓存中不存在就需要在数据库中读取。
-
更新缓存。
那么这些操作是怎么进行的呢?这就和旁路缓存有关,下面详细聊聊。
什么叫旁路缓存
Redis应用于生产上一般是一个独立的程序和业务程序分开,只能被动等待客户端的调用,我们如果在程序中使用还要加入Redis的调用代码,所以我们也将Redis称为旁路缓存,读取缓存和更新缓存都是在业务系统中完成。这和上面提到的操作系统的CPU缓存LLC,内存缓存page cache有本质区别,LLC和page cache从系统初始化就存在系统调用的主路径上,不需要其它业务系统主动调用。
缓存类型
Redis根据请求的类型分为只读缓存和读写缓存,这是针对客户端发送的写请求是否在Redis中修改进行区分。
只读缓存
只读缓存只提升缓存的读性能,当客户端发送一个读请求时Redis从缓存中查找是否存在,如果存在直接返回,不存在就从数据库获取,写入缓存中同时返回客户端,如果是写请求,直接修改数据库数据然后将缓存中的对应键值删除。
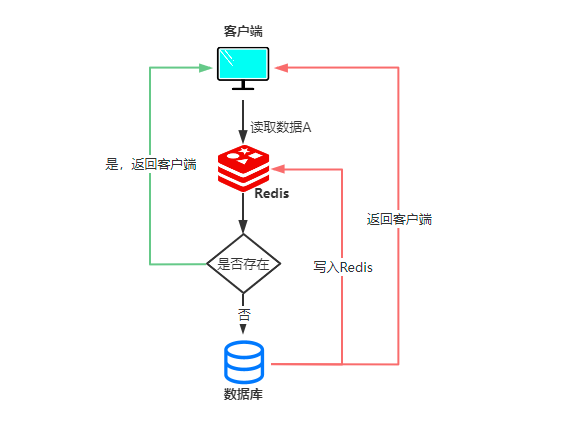
这样可以保证数据库中的数据都是最新的,而且数据不会丢失。
读写缓存
读写缓存可以提升读写效率,这与只读缓存不同的是,读写缓存会在Redis中做增删改的操作,Redis中的数据将是最新的一份,这样就能快速的响应客户端,但是数据一直放在内存中显然是不可靠的,如果出现Redis宕机将丢失数据,所以这里又提供了两种写回数据库的策略,同步写回和异步写回。
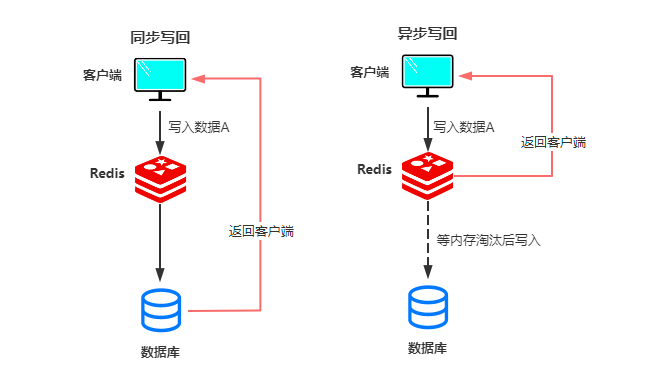
同步写回表示,当客户端发送一个写请求过来会同时更新缓存和数据库,两者全部更新完毕才会返回,这样会降低处理性能,但能提升可靠性。
异步写回表示,当客户端发送一个写请求过来会先更新缓存,更新完后直接返回客户端,仅当写入后的数据淘汰出内存后才会写入数据库,这样保证了性能,但是可靠性降低了。
如何选择缓存类型
需要根据业务出发,如果是读多写少的场景,那么使用只读缓存就可以解决,而需要给写加速的场景肯定选择读写缓存但使用读写缓存需要注意数据写回策略,需要在数据可靠性和性能两个方面做取舍。
这篇关于Redis之旁路缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





