本文主要是介绍借助“湖仓一体”打造金融行业分布式数据库的领头羊,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

“【报告下载】后台回复关键词“数据智能报告”可免费下载数据猿最新发布的完整高清版《2021中国数据智能产业发展报告》

大数据产业创新服务媒体
——聚焦数据 · 改变商业
近日,领先的金融级分布式数据库厂商SequoiaDB巨杉数据库举行了2021年春季发布会。在本次发布会中,巨杉数据库重点推出基于“湖仓一体”架构,针对不同的业务需求场景细分出全新的产品线。
什么是“湖仓一体”
我们回想一下大学课堂学过的基础数据库,当时我们使用的表结构,处理的数据大都属于结构化数据,对结构化数据分析通常就会用到数据仓库。而如今一方面数据量在加大;另一方面,数据的类型早已突破了结构化,现在有大量非结构化、半结构化数据,包括图片、音频、视频数据,这些数据呈现出多样性、高速度、大容量等特征。很显然,传统的数据仓库并不适合这样的场景,而且就成本而言,一定不是最具优势的方案。
大约十年前,数据湖出现了,它被定义为一种可以存储各类格式的原始数据存储。我们的那些各类数据可以存储在数据湖里,但数据湖缺少一些关键功能,比如不支持事务、缺乏一致性、隔离性、不保证执行数据质量等,这些短板决定了,让数据湖来承载过去数据仓库比较顺畅的读写访问、批处理、流作业是不现实的,过去在数据仓库比较容易实现的BI数据分析由数据湖完成是很费劲的。
随着企业从多种数据来源中大规模地收集数据,此时架构师也开始考虑,如何构建一个单一的系统,来实现数据的仓库化存储,还能比较轻松地完成多样化的数据分析。另外,人工智能的需求,也让统一的架构变得必要,需要数据访问的灵活性、高性能并举。
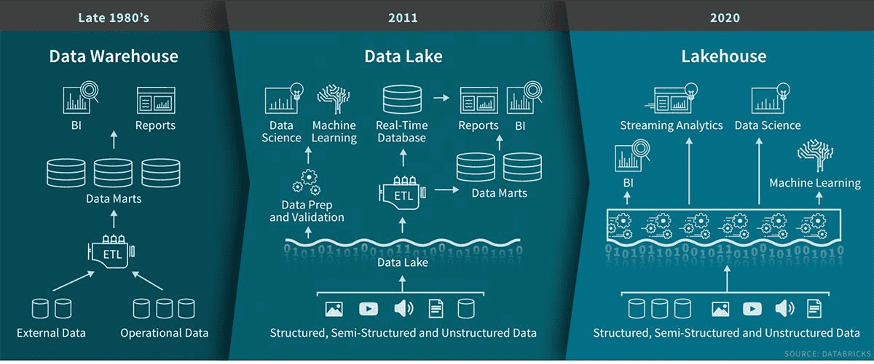
来源:Databricks官网
此时,“湖仓一体”应运而生,它是一种新型开放式架构,将数据湖和数据仓库的优势充分结合,它构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理和管理功能。湖仓一体的英文名叫“Lakehouse”,有人把“湖仓一体”做了形象的比喻,就好像湖边搭建了很多小房子,有的可以负责数据分析,有的来运转机器学习,有的来检索音视频等等,而这些数据源流,都可以从数据湖里轻松取得。
巨杉数据库联合创始人兼CTO王涛表示,“湖仓一体”是一类技术架构的统称,而不是某个产品。实际上,巨杉数据库对这类技术架构的布局并不是现在,最早可追溯到2015年,在业界形成统一认知的概念之前,提前5年利用其特点协助客户落地如今称为“湖仓一体”的数据架构。

巨杉数据库联合创始人兼CTO王涛
巨杉数据库与全球技术同期起步,自2011年起投入研发,这个时间点甚至早于Google Spanner论文的发表,是国内最早起步研发分布式数据库的厂商之一。如今,巨杉数据库已经在超过100家金融银行客户生产环境稳定运行,当中更有多家客户数据量超过100亿行记录,客户生产环境下最大数据量的集群更是达到1万2000亿行。
比如我们耳熟能详的民生银行、广发银行、恒丰银行、渤海银行等股份制银行;广东省农信、吉林省农信、四川省农信等省级农信行;上海银行、长沙银行、广州银行等城商农商行;以及PICC人保、中国结算等各类金融机构,都已经在生产业务系统规模化上线巨杉数据库产品。
我们来看看巨杉的Lakehouse可以为企业带来哪些能力:
• 事务支持:对事务的ACID支持,可确保数据并发访问的一致性、正确性,尤其是在SQL的访问模式下。
• 数据的模型化和数据治理:支持各类数据模型的实现和转变,支持DW模式架构,例如星型模型、雪花模型等。该系统应当保证数据完整性,并且具有健全的治理和审计机制。
• BI支持:支持直接在源数据上使用BI工具,这样可以加快分析效率,降低数据延时。另外相比于在数据湖和数据仓库中分别操作两个副本的方式,更具成本优势。
• 存算分离:存算分离的架构使得系统能够扩展到更大规模的并发能力和数据容量。(一些新型的数据仓库已经采用了这种架构)
• 开放性:采用开放、标准化的存储格式(例如Parquet等),提供丰富的API支持,因此,各种工具和引擎(包括机器学习和Python / R库)可以高效地对数据进行直接访问。
• 支持多种数据类型(结构化、非结构化和半结构化):可为许多应用程序提供数据的入库、转换、分析和访问。数据类型包括图像、视频、音频和文本等。
• 支持各种工作负载:支持包括数据科学、机器学习、SQL查询、分析等多种负载类型。这些工作负载可能需要多种工具来支持,但它们都由同一个数据库来支撑。
• 端到端流:实时报表已经成为企业中的常态化需求,实现了对流的支持后,不再像以往一样,为实时数据服务构建专用的系统。
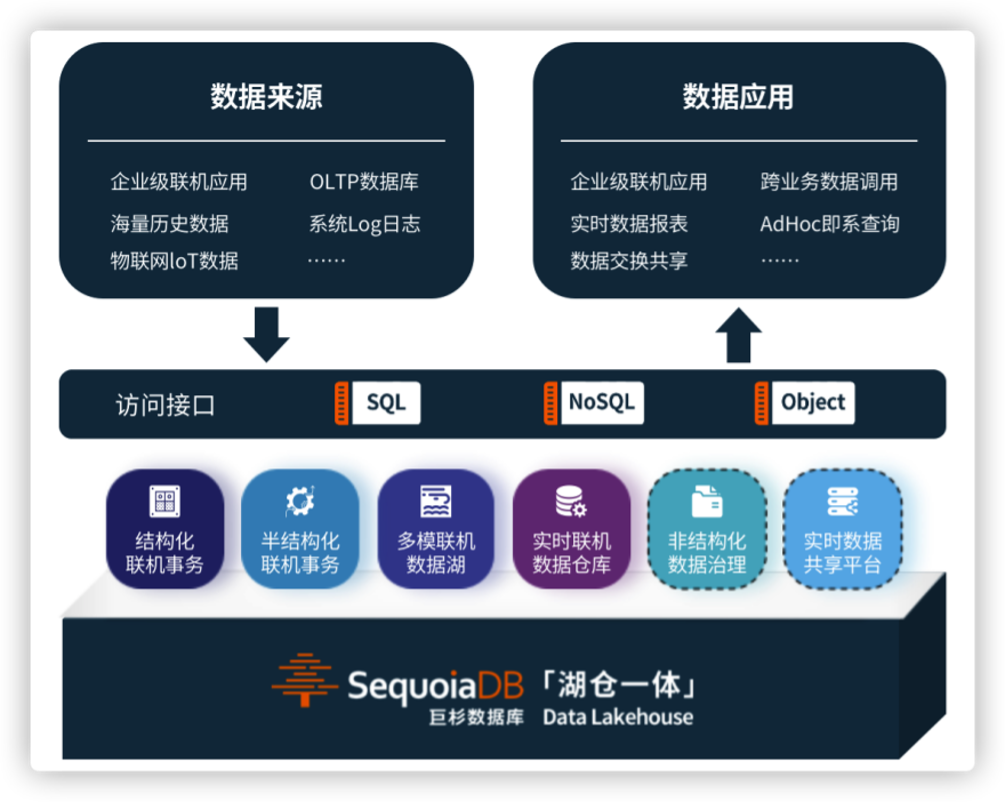
来源:巨杉数据库公司官网
可以拓展的功能还有很多,在“湖仓一体”架构下,这些企业级的需求功能,都可以在“湖仓一体”平台中部署、测试和管理。更重要的一点,巨杉数据库认为,“湖仓一体”平台作为数据基础设施,其真正的价值在于打通不同业务类型、不同数据类型之间的技术壁垒,实现交易分析一体化、流批一体化、多模数据一体化,最终降低数据流动带来的开发成本及计算存储开销,提升企业的运作的“人效”和“能效”。
分布式数据库不仅仅是传统的替换
企业需求的变化除了自身需要、解决业务发展瓶颈以外,更多源自计算载体的变化、计算架构的变化以及计算环境的变化。过去是2G、3G产生的数据量,现在要考虑到5G产生的数据量;过去的信息主要是数字和文字,现在图片、声音、视频等非结构化数据成为增量数据的主要类型;过去是单机架构,现在逐步过渡到云架构,数据库也要随时变化;还有正在兴起的万物互联和人工智能,都会产生海量级数据。
根据IDC的报告,在2020年全球数据量大约有55ZB,而到2025年将达到175ZB。数据量上升,整体市场容量扩大,必定带来新的机遇,所以从数据库行业市场规模来看,将从2020年561亿美元达到2024年的1021亿美元。
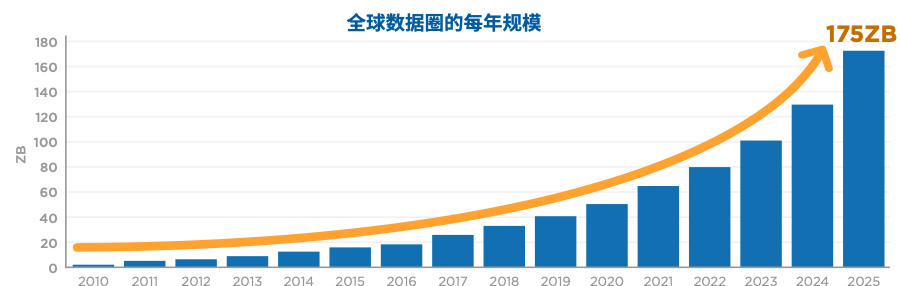
来源:IDC
我们同时看到,分布式数据库的未来并不意味着替换传统关系型数据库,而更注重增量市场。数据量增长的空间是无法估量的。过去很长一段时间业界所主张的“去IOE”,现在数据库行业内部已很少提起。在巨杉看来,更关注的是与客户一同发展高速增长的全新业务市场,从而形成与上一代集中式产品的迭代,而不是迁移替代。所以巨杉数据库的目标是与客户共同挖掘数字化转型中的全新数据价值,建立全新的分布式技术赛道,超越传统的架构边界。
因此,相对Oracle、IBM DB2等传统数据库厂商,巨杉数据库更加关注Snowflake、Databricks等一些新兴数据库国际领导者的脚步。而Databricks作为Lakehouse概念的提出者,旨在兼容数据仓库和数据湖的优势。为客户提供统一分析平台提升效率。
不仅如此,相比商业智能(BI),人工智能(AI)发展的需求更能推动数据库的演变。在Wikibon公司研究AI、数据科学和应用软件开发的首席分析师James Kobielus看来,“数据湖”正在迅速发展成为下一代数据仓库。新一代数据仓库的首要任务是用来治理用于构建和训练机器学习模型的清理、整合和认可。底层数据平台将继续演进,为基于云的AI管道提供核心的数据治理基础。
跨多云部署,“中立”的数据库厂商
Snowflake 创造性地提出DaaS(Data warehouse as a Service)概念,将存储和计算彻底分离,从本质上解决了以往架构的痛点,最大化体现出了云原生架构的特点。它打破数据仓库、数据湖、数据集市等孤岛,极大地改变了数据格局,并消除了为每个工作负载配备独立系统的需求。其数据库可在三大公有云 AWS、Azure 和 Google Cloud Platform 上部署,对于企业多云异构的复杂环境有适用性、中立性,同时亦提供数据交换功能,解决了过去用户面临着投入高、灵活度低等问题。
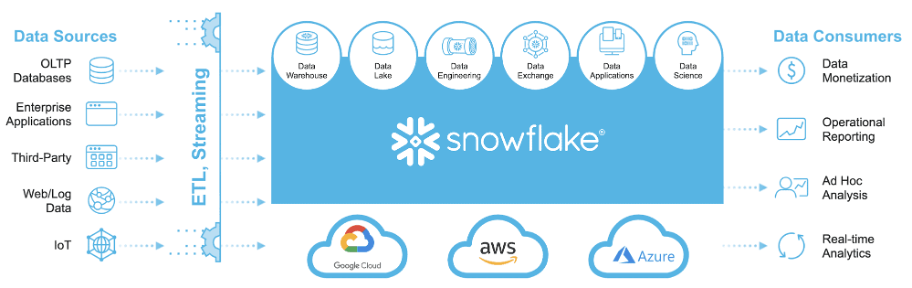
数据来源:snowflake官网
巨杉数据库在这次发布会隆重推出的SequoiaDB Cloud,就是按照这种理念。我们知道,企业的云计算落地,往往会按自身的需求,选择使用不同能力的云厂商。一些企业甚至会选择多家云厂商的IaaS平台作为基础设施,这就好比以往我们选择多家服务器厂商构建基础设施一样。
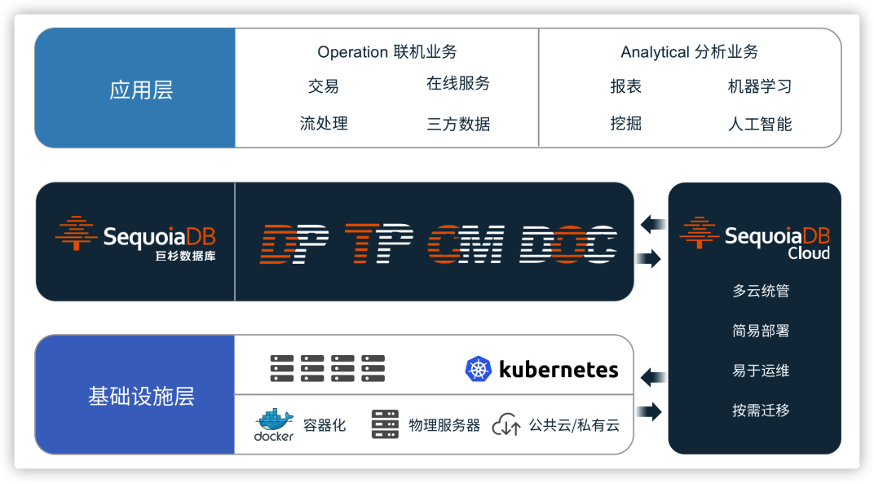
巨杉数据库SequoiaDB Cloud因应企业的实际需求,它所提供的云的能力不是一个纯粹在云上面去进行运维部署的能力,而是支持跨云的方式,面向不同的云厂商,提供跨公有云及私有云“跨多云”的部署能力。
聚焦金融行业,构建行业通用数据库产品
我国金融行业的监管机构在“分布式数据库”行业技术标准跟进速度也很快,为产业的发展指明了方向。2020年11月26日,中国人民银行正式发布了《分布式数据库技术金融应用规范技术架构》(JR/T 0203-2020)等3项金融行业标准,从技术方面、安全稳定以及灾备方面提出了具体技术要求,巨杉数据库均参与了制定的工作。
作为面向金融级企业客户的商业化产品,巨杉数据库从设计之初就是面向企业级整体需求,也因此更能满足行业技术顶层设计的需求。基于湖仓一体的分布式技术架构,巨杉数据库提供多模数据类型的技术能力,及跨引擎事务一致性,为客户的联机交易及实时数据中台构建了坚实的数据基础设施,获得了客户众多好评。

未来面对金融企业进一步的数据化转型需求,数据量要求会更大,不同数据链条之间会有更多细节数据的沟通,对数字安全性要求也更高。面对未来数据量、算法与机器的交互、AI对数据使用的需求和变化,还有前面提到的从T+1到T+0的实时数据处理需求,都需要数据库扩展、计算、一致性等诸多能力的进一步提升,这些需求将给未来巨杉数据库团队提出更高的要求。
打造业内一流的分布式数据库团队
王涛表示,巨杉数据库能有今天的成就与市场地位,离不开整个团队10年来的艰苦奋斗。我们长期持续坚持以客户为中心、以技术为底蕴、以市场为导向,打造出全球顶尖的新一代分布式数据库产品。
巨杉数据库的两位创始人都从海外大厂归来。其中,巨杉数据库的联合创始人,CTO与总架构师王涛曾是北美 IBM DB2 Lab核心研发成员,全球最高顾问小组成员之一(全球仅15人),是最早接触分布式数据库的先行者之一。2011年,两位创始人回国正式创立了巨杉数据库。随着团队的扩张,吸引大量来自IBM DB2北美研发团队、华为分布式储存团队以及Oracle的人才,天生具备企业级基因。同时引入包括阿里在内的国内创新型企业人才,可以说,如今的巨杉数据库拥有业界最顶尖的企业级分布式数据库团队。

此外,巨杉数据库在多伦多建立前沿实验室,并在今年以最高级别钻石级赞助全球数据库领域顶级学术会议ACM SIGMOD,旨在与数据库前沿领域建立更密切的联系,跟顶级的研究团队有更多的碰撞机会,吸引更多优秀人才加入巨杉团队。
技术生态方面,巨杉数据库构建了被称为“巨杉学”的认证与学习体系。目前,已有超180家金融机构,30余家知名技术服务开发商加入巨杉学计划。截至2020年底,“巨杉学”已认证工程师超过1.8万人,网站用户注册数量超过5万人,为分布式技术业界发展提供坚实的人才积淀。
正如中国人民银行副行长范一飞发表在《中国金融》上题为《谱写新时代金融信息化发展新篇章》的文章中写到,“建立健全与金融市场相适应、有利于吸引和留住人才、激励和发展人才的薪酬和考核制度,激发人才创新创造活力,造就既懂金融又懂科技的新型复合型人才队伍。”像巨杉数据库这样,与行业密切结合的领域,复合人才的吸引和培养至关重要,期待中国数据库产业蓬勃发展,推动信创产业砥砺前行。
文:陆易斯 / 数据猿
●上一篇精彩好文:
华为“风云变”背后:不断开疆拓土,余承东挑起“汽车局”大梁



❷ 创新服务企业榜
❸ 创新服务产品榜
❹ 最具投资价值榜
❺ 创新技术突破榜

☆条漫:《看过大佬们发的朋友圈之后,我相信:明天会更好!》
联系数据猿
北京区负责人:Summer
电话:18500447861(微信)
邮箱:summer@datayuan.cn
全国区总负责人:Yaphet
电话:18600591561(微信)
邮箱:yaphet@datayuan.cn
这篇关于借助“湖仓一体”打造金融行业分布式数据库的领头羊的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







