本文主要是介绍cachelab实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
计算机系统原理实验日志
一、实验内容
1、编写一个C程序(csim.c,大约200-300行),用于模拟Cache的行为。
2、已提供一个参考的cache模拟器(可执行文件csim-ref),目标是自己写的
csim和参考的csim-ref行为一致,即两者模拟同一个访存过程得到的
cache 命中次数(hits)、不命中次数(misses)、替换次数(evicts)都相同。
二、相关知识
1.高速缓存存储器结构:
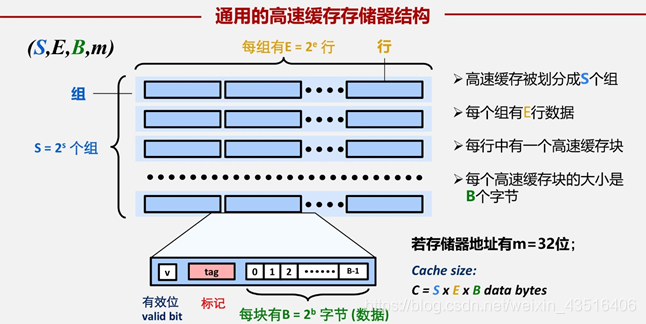
内存地址划分如下:

t=m-(s+b)
要访问高速缓存存储空间中的字节:
根据内存地址进行 组选择,行匹配,字抽取;
存储层次主要有四个问题
(1)映射规则:
直接映射:E=1

全相联映射:S=1—>s=0

E-路组相联映射:
 (图中E=2)
(图中E=2)
(2)查找算法
(3)替换算法
a. FIFO算法 -- 先进先出,易理解也易实现
b. OPT算法 — 基本不可能实现、一般用LRU算法替代
c. LRU算法
本次实验要用到的是LRU算法,所以主要介绍LRU—最近最少使用替换策略:
cache的容量有限,当满的时候需要牺牲行(驱逐某行),先遍历当前组,判断它是否容量已满,如果未满:将有效位不为1的一行更新有效位为1,同时更新标记位和LRU计数值,如果满了,找出最小LRU所在的行作为牺牲行。
(4)写策略:
a.直写+非写分配
b.写回+写分配(适用于较低层次的缓存)
2. Linux下getopt()函数的简单使用
由于本实验中需要获取命令行,所以需要用到unistd.h头文件中的getopt:int getopt(int argc,char * const argv[ ],const char * optstring);
它用来分析命令行参数;
参数argc和argv分别代表参数个数和内容,跟main的命令行参数相同。
参数optstring为选项字符串,告知getopt()可以处理哪个选项以及哪个选项需要参数,如果选项字符串里的字母后接着冒号“:”,则表示还有相关的参数,全域变量optarg 即会指向此额外参数;
它可以返回选项字符(以整型值的形式),返回-1时即代表解析完成。
/*
关于选项字符串的详细解释如下:
"a:b:cd::e"即一个选项字符串。它对应到命令行就是-a ,-b ,-c ,-d, -e 。其中 冒号表示参数,一个冒号就表示这个选项后面必须带有参数,没有带参数就会报错,但是这个参数可以和选项连在一起写,也可以用空格隔开,比如
-a123 和-a 123(中间有空格)都表示123是-a的参数;
两个冒号的就表示这个选项的参数是可选的,即可以有参数,也可以没有参数,但要注意有参数时,参数与选项之间不能有空格(有空格会报错的哦),这一点和一个冒号时是有区别的,
选项后面为两个冒号,且没有跟参数,则optarg = NULL,
有些选项是不用带参数的,而这样不带参数的选项可以写在一起。。
*/
3.fopen函数
因为本次实验中需要读取trace文件,所以需要用到fopen函数来打开文件:
FILE * fopen(const char * path, const char * mode);
参数path字符串包含欲打开的文件路径及文件名;
参数mode字符串则代表着打开文件的方式,包括 ’r’, ’w’, ’a’, ’r+’, ’rb+’ 等等;
文件顺利打开后,指向该流的文件指针就会被返回。
如果文件打开失败则返回NULL,并把错误代码存在errno 中。
调用它的一般形式为:
文件指针名 = fopen(文件名,使用文件方式);
其中,文件指针名 -- 被说明为FILE 类型的指针变量;
文件名 -- 被打开文件的文件名,为字符串常量或字符串数组;
使用文件方式 -- 指文件的类型和操作要求。
4.C库函数 -- fscanf函数
int fscanf(FILE *stream, const char *format, ...)
它从流 stream 读取格式化输入,
第一个参数stream 是指向 FILE 对象的指针,该 FILE 对象标识了流;
第二个参数format 是字符串,
format 说明符形式为 [=%[*][width][modifiers]type=]
附加参数---根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了format参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同。
如果成功,该函数返回成功匹配和赋值的个数。
如果到达文件末尾或发生读错误,则返回 EOF。
总而言之,它按照你定义的格式读取输入并赋值到你对应的附加参数中,然后返回读取输入的个数。
5.动态分配函数malloc与calloc
malloc()和calloc()的功能:
在内存的动态存储区中分配n个长度为size的连续空间,
函数返回一个指向分配起始地址的指针。
区别:
calloc在动态分配完内存后,自动初始化该内存空间为零,
而malloc不初始化,里边数据是随机的垃圾数据。
三、实验原理
注意事项:
a.由于模拟器必须适应不同的s, E, b,所以数据结构必须动态申请,
注意初始化。
b.测试数据中以“I”开头的行是对指令缓存(i-cache)进行读写,我们编写
的是数据缓存(d-cache),这些行直接忽略。
c.这次实验假设内存全部对齐,即数据不会跨越block,所以测试数据里面的
数据大小也可以忽略。
可以根据老师所给提示逐步分析:
1、如何从命令行中解析s、E、b、t(trace)参数?(getopt函数)
根据相关知识中所介绍关于getopt函数的知识,我们能很快的解决这个问题。用法如下:
![]()

在switch语句中具体实现相应选项及参数对应的功能即可。
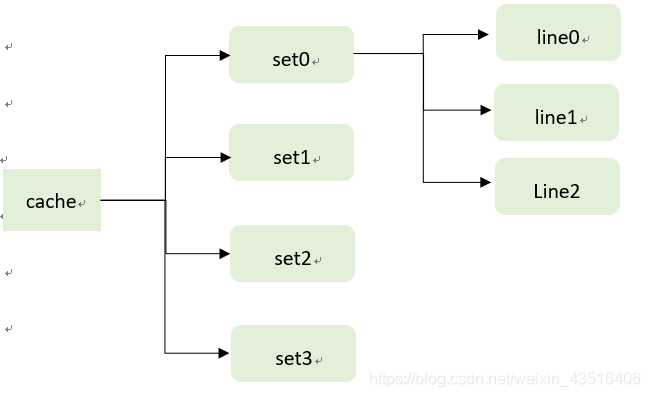
2、如何构建一个cache?
实验只要求我们测试hit/miss/eviction的次数,并没有实际的数据存储,
所以我们不用实现line中的block部分,只需关注是否命中和替换,不关注
数据从内存加载到cache block的哪个位置,
所以cache只需要是一个二维数组cache[S][E]的形式(与b无关),
由于S、E的值是不确定的,所以我们可以考虑采用指针去实现此二维数组:
3、如何从访存trace文件中读取每条访存操作?
自然是灵活运用相关知识中介绍的fscanf函数啦~
访存操作的格式如下:

忽略以i开头的指令缓存操作及每条访存操作的访问字节数:

4、如何从访存操作中的起始地址参数中提取标记位t、组索引s、块偏移b?
已给提示是移位。
我们不需要知道块大小,需要块偏移是为了求t,t = m-b-s,实际上将地址
作为二进制串时,只需要将实际地址右移(b+s)即可得到t的值;
而s,将实际地址右移b位后,低s位即它的值,为了获取这低s位,我们
将1左移s位再减1,可得到2^s-1,将它与右移b位后的实际地址相与即可
得到其低s位,如下:

5、cache模拟器采用哪种放置策略和替换策略?
放置策略:组内放哪儿 -- 放置于组内第一个空闲行;
替换策略:LRU,与csim-ref保持一致;
整体思想是为每一行设置一个计数器,将空闲行的计数器值置为0,
其余行每使用一次加一,新放置的行的计数器值则设为其余行的最大值+1,
每次需要替换时就找到组内计数器值最小的(如果值相同,则是按行序最小的)
一行进行替换。
根据以上分析,其实实现Cache模拟的大致设计思路已经出来了,
之后就是考虑具体实现啦~
四、实验步骤
1. 准备过程
(1)把cachelab-handout.tar拷贝到linux下再解压缩
(不要在windows下解压)
可直接将压缩包从windows桌面下拖到ubuntu中,
也可通过邮箱发送在ubuntu中下载;
命令即 tar xvf cachelab-handout.tar
(2)安装valgrind工具
>sudo su
>apt-get install valgrind
安装完成后输入如下命令可查看每次访存操作(可选):
> valgrind--log-fd=1 --tool=lackey -v --trace-mem=yes ls -l
至此,工具准备已经完成,具体要怎么进行实验,我们可以看到压缩包中有readme,其中 ,所以我们去查看这两个文件,发现
而cachelab.c中即这四个函数的实现,
在partA中,我们只需要printSummary这个打印结果的函数即可。
那么partA部分其他的函数就全部自由发挥了。
2.具体设计
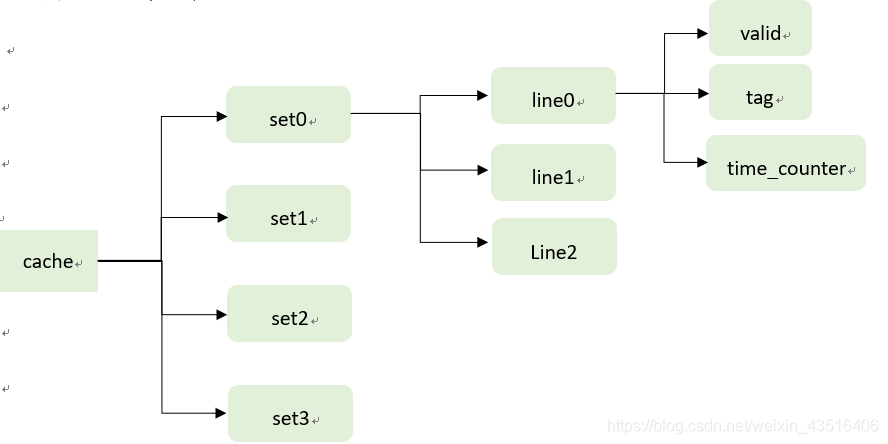
(1)数据结构的设计
对于每一行,我们需要一个有效位,一个标记位,一个计数器(用于LRU算法),
所以可以设计一个结构体:

对于cache的构建,前面已经提到过了,cache可当作二维数组cache[S][E],
采用指针去实现:
![]()
然后在解析命令行得到参数S、E的值后再动态分配并初始化内存,因为
每一行都应该初始化为0,所以可以采用calloc函数:
根据S(set的数目)申请一个数组,该数组元素是lines的入口的指针;
接着循环S次,每次申请E个line,让刚申请的指针数组的元素指向它们。
总体数据结构如下:
内存的分配及初始化如下:

(2)解析命令行的逻辑设计
通过getopt函数获取命令行,逐个获取每个选项并作出相应操作:
当选项为h或输入不符合要求时,我们中断并打印详细命令用法以提示;
当选项为v时,我们设置verbose标识为true,即说明需要输出每条访问
操作的详细信息,在之后分析每条访存操作的过程中就可以通过此标识
去判断是否输出对应信息;
当选项为s,E,b时,我们要判断其输入参数的值是否在1-64之间(s可为0),
如果不是,我们进行中断并打印详细命令用法以提示,
如果是,记录其值(不输入)。
(3)LRU算法的具体实现
其设计思路在实验原理的第5个问题中已经说明,就不再罗嗦了,实现如下:
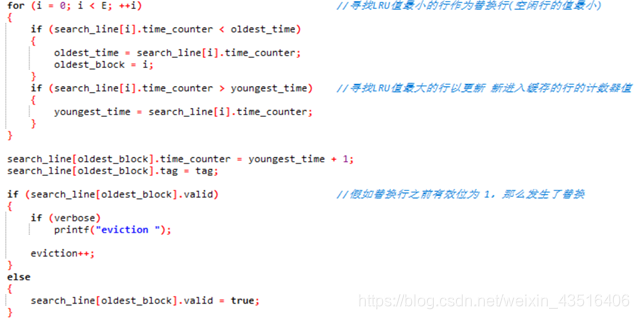
(4) 判断每条访存操作的结果的过程
从访存地址获取其所在组,在此组中逐行对比有效位与标志位,
如果有标志位相同且有效位为1的行,则命中,设置hit_flag为true,
并更新此行的LRU计数器值,hit++;
如果没有,miss++,寻找LRU值最小的行作为替换行,更新其LRU计数器值,
如果此行有效位为1,代表此行不为空闲行,发生了替换,evication++,
否则要对此空闲行有效位置1;
(5)读取tracefile并统计其中访存操作得到的命中、不命中、替换次数
在实验原理中已经详述了如何从访存trace文件中读取每条访存操作及
如何从访存操作中的起始地址参数中提取标记位t、组索引s、块偏移b,
并且已经实现了如何判断每条具体访存操作的结果,
还需要考虑的是从tracefile中获取每条访存操作后如何实现其相应逻辑,
如果访存操作为load/store,只需要进行一次对此访问操作的判断即可;
如果访存操作为Modify,相当于进行一次load再对此地址进行一次store,
所以会引起两次访存操作,需要进行两次判断,
其结果可以为两次缓存命中, 或 一次未命中(可能包含替换)、一次命中;
(6)打印命令详细用法
这个就没什么好介绍的了,只是为了减少代码重复所以单独做了一个函数:

(7)释放内存
在c中如果进行了内存分配,必然要释放内存,所以不要忘了free:

3.操作步骤
完成csim.c代码设计与编写后,即可进行测试
(1)输入make clean后输入make命令编译csim.c,生成可执行文件csim
(2)输入./csim –v –s <num> –E <num> –b <num> -t <tracesfile>
查看每次访存cache是否命中和替换的详细信息(可选)
(3)输入./test-csim运行cache模拟器的评价程序,查看得分是否为27分,
27分(满分)则csim.c正确,低于27分则需修改csim.c。
(修改时可用相同的sEbt参数分别运行csim和csim-ref,查看每次访存的
详细信息是否一致)
五、实验结果
实验结果如下:
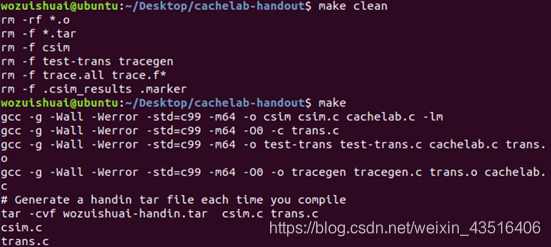
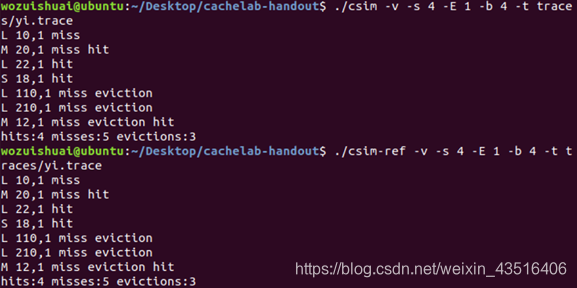
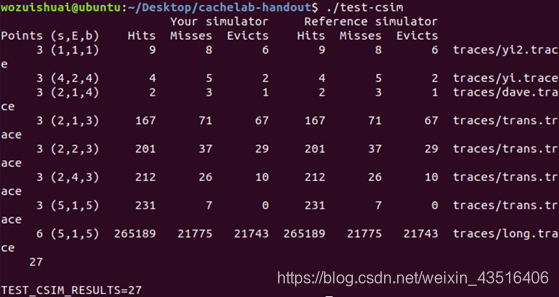
六、遇到的问题
问题1:一个不算问题的问题:
我实现的时候考虑了s为0即全相联的情况,但是.csim-ref中好像是不能
出现s为0的输入的:
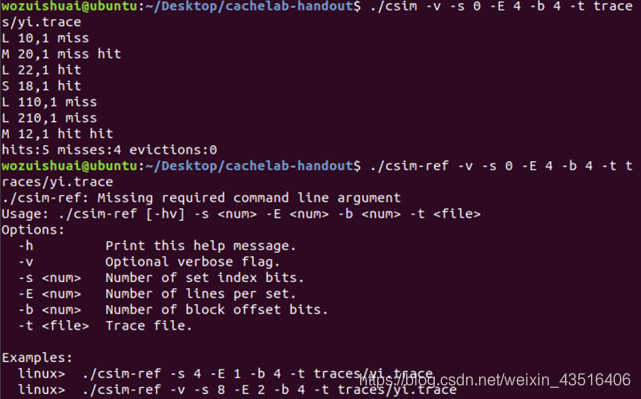
这个其实就把这的小于0改为<=0即可:

问题2:我想让s,b,E三个选项作为可选选项,也就是说不输入这三个选项及参数时默认其为0,1,1

但是会出现如下错误:
![]()
但是如果直接输入这些参数又是正确的:

想到参数可输入可不输入时选项字符串应该为
![]()
又尝试了一下:
![]()
而且这次连直接输入这些参数也是错误的:
![]()
所以感觉问题应该出在getopt函数上,但是还没找到解决办法。
七、实验心得体会
略
在最后把整个代码贴一下:
#include "cachelab.h"
#include <stdio.h> /* fopen freopen perror */
#include <stdint.h> /* uintN_t */
#include <unistd.h> /* getopt */
#include <getopt.h> /* getopt -std=c99 POSIX macros defined in <features.h> prevents <unistd.h> from including <getopt.h>*/
#include <stdlib.h> /* atol exit*/
#include <errno.h> /* errno */#define false 0
#define true 1typedef struct
{_Bool valid; // 有效位 uint64_t tag; // 标记位 uint64_t time_counter; // LRU计数器,替换此值最小的行
}line;
typedef line *entry_of_lines;
typedef entry_of_lines *entry_of_sets;typedef struct
{int hit; // 记录命中次数 int miss; // 记录未命中次数int eviction; // 记录替换次数
}result;entry_of_sets InitializeCache(uint64_t S, uint64_t E);result HitMissEviction(entry_of_lines search_line, result Result, uint64_t E, uint64_t tag, _Bool verbose);result ReadAndTest(FILE *tracefile, entry_of_sets cache, uint64_t S, uint64_t E, uint64_t s, uint64_t b, _Bool verbose);void RealseMemory(entry_of_sets cache, uint64_t S, uint64_t E);/* 当选项为 h,或输入错误的命令(格式错误或用法错误)时,打印命令详细用法 */
void printHelpMessage()
{//这些提示信息是按照.csim-ref的提示信息编写的printf("Usage: ./csim [-hv] -s <num> -E <num> -b <num> -t <file>\n");printf("Options:\n"); printf("-h Print this help message.\n"); printf("-v Optional verbose flag.\n"); printf("-s <num> Number of set index bits.\n"); printf("-E <num> Number of lines per set.\n"); printf("-t <file> Trace file.\n"); printf("\n"); printf("Examples:\n"); printf("linux> ./csim -s 4 -E 1 -b 4 -t traces/yi.trace\n"); printf("linux> ./csim -v -s 8 -E 2 -b 4 -t traces/yi.trace\n");
}int main(int argc, char * const argv[])
{result Result = {0, 0, 0};const char *command_options = "hvs:E:b:t:";FILE* tracefile = NULL;entry_of_sets cache = NULL;_Bool verbose = false; /* flag whether switch to verbose mode, zero for default */uint64_t s = 0; /* number of sets ndex's bits */uint64_t b = 0; /* number of blocks index's bits */uint64_t S = 0; /* number of sets */uint64_t E = 0; /* number of lines */char ch; /* command options */while((ch = getopt(argc, argv, command_options)) != -1){switch(ch){case 'h':{printHelpMessage(); exit(EXIT_SUCCESS);}case 'v':{verbose = true;break;}case 's':{if (atol(optarg) <= 0) /* We assume that there are at least two sets */{printHelpMessage(); exit(EXIT_FAILURE);}s = atol(optarg);S = 1 << s;break;}case 'E':{if (atol(optarg) <= 0){printHelpMessage(); exit(EXIT_FAILURE);}E = atol(optarg);break;}case 'b':{if (atol(optarg) <= 0) /* We assume that there are at least two sets */{printHelpMessage(); exit(EXIT_FAILURE);}b = atol(optarg);break;}case 't':{if ((tracefile = fopen(optarg, "r")) == NULL){perror("Failed to open tracefile");exit(EXIT_FAILURE);}break;}default:{printHelpMessage(); exit(EXIT_FAILURE);}}}if (s == 0 || b ==0 || E == 0 || tracefile == NULL){printHelpMessage(); exit(EXIT_FAILURE);}cache = InitializeCache(S, E);Result = ReadAndTest(tracefile, cache, S, E, s, b, verbose);RealseMemory(cache, S, E); /* Don't forget this in C/C++, and do not double release which causes security problem *///printf("hits:%d misses:%d evictions:%d\n", Result.hit, Result.miss, Result.eviction);printSummary(Result.hit, Result.miss, Result.eviction);return 0;
}/* 初始化缓存 */
entry_of_sets InitializeCache(uint64_t S, uint64_t E)
{entry_of_sets cache;//使用 calloc而非 malloc,因为我们需要初始化为0 if ((cache = calloc(S, sizeof(entry_of_lines))) == NULL) {perror("Failed to calloc entry_of_sets");exit(EXIT_FAILURE);}for(int i = 0; i < S; ++i) {if ((cache[i] = calloc(E, sizeof(line))) == NULL){perror("Failed to calloc line in sets");}}return cache;
}/* 判断每条访存操作是 hit or miss or miss+evication */
result HitMissEviction(entry_of_lines search_line, result Result, uint64_t E, uint64_t tag, _Bool verbose)
{uint64_t oldest_time = UINT64_MAX; //用于寻找 LRU计数器值最小的行 uint64_t youngest_time = 0; //用于寻找 LRU计数器值最大的行 以 更新替换进入缓存的行的LRU值 uint64_t oldest_block = UINT64_MAX; //记录 LRU计数器值最小的行号 _Bool hit_flag = false;for (uint64_t i = 0; i < E; ++ i){if (search_line[i].tag == tag && search_line[i].valid) //命中 {if (verbose) printf("hit\n");hit_flag = true;++Result.hit;++search_line[i].time_counter; //更新计数器值 break;}}if (!hit_flag) //未命中{if (verbose) printf("miss");++Result.miss;uint64_t i;for (i = 0; i < E; ++i) //寻找LRU值最小的行作为替换行(空闲行的值最小){if (search_line[i].time_counter < oldest_time){oldest_time = search_line[i].time_counter;oldest_block = i;}if (search_line[i].time_counter > youngest_time) //寻找LRU值最大的行以更新 新进入缓存的行的计数器值 {youngest_time = search_line[i].time_counter;}}search_line[oldest_block].time_counter = youngest_time + 1;search_line[oldest_block].tag = tag;if (search_line[oldest_block].valid) //假如替换行之前有效位为 1,那么发生了替换 {if (verbose) printf(" and eviction\n");++Result.eviction;}else{if (verbose) printf("\n");search_line[oldest_block].valid = true;}}return Result;
}/* 计算结果 (若verbose为真,打印每条访存操作详细结果) */
result ReadAndTest(FILE *tracefile, entry_of_sets cache, uint64_t S, uint64_t E, uint64_t s, uint64_t b, _Bool verbose)
{result Result = {0, 0, 0};char ch;uint64_t address;//读取tracefile中每条访存操作,获取指令及地址,本来可直接忽略读取字节数,但为了打印访存操作,需要记录 //地址是十六进制数,所以采用 %lx 而非 %luwhile((fscanf(tracefile, " %c %lx%*[^\n]", &ch, &address)) == 2) {if (ch == 'I'){continue;}else{uint64_t set_index_mask = (1 << s) - 1;uint64_t set_index = (address >> b) & set_index_mask;uint64_t tag = (address >> b) >> s;entry_of_lines search_line = cache[set_index];// load / store 操作只会引起一次访存操作if (ch == 'L' || ch == 'S'){if (verbose) printf("%c %lx ", ch, address);Result = HitMissEviction(search_line, Result, E, tag, verbose);}/* data modify操作会进行一次 load再对此地址进行一次 store,所以会引起两次访存操作 结果可以为 两次缓存命中, 或 一次未命中(可能包含替换)、一次命中. */else if (ch == 'M'){if (verbose) printf("%c %lx ", ch, address);Result = HitMissEviction(search_line, Result, E, tag, verbose);Result = HitMissEviction(search_line, Result, E, tag, verbose);}else{continue;}}}return Result;
}/* 释放内存 */
void RealseMemory(entry_of_sets cache, uint64_t S, uint64_t E)
{for (uint64_t i = 0; i < S; ++i){free(cache[i]);}free(cache);
}
这篇关于cachelab实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








