本文主要是介绍【论文分享CVPR2020】Multiple Object Tracking by Flowing and Fusing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flowing and Fusing 论文分享
题目:Multiple Object Tracking by Flowing and Fusing
(CVPR2020)
论文连接
1. 要解决的问题:
大多数的MOT的方法都是两个步骤:
1)在输入帧上分别运行一个运动模型和一个外观模型,分别生成运动和外观特征;
2)根据运动和外观特征在帧之间进行目标关联。
然而,这两个步骤在端到端框架中没有得到优化,因此通常需要一个较大的DNN来学习高度区分的动作和外观特征。由于没有近乎完美的特征,在目标关联步骤中需要处理大量的候选目标和启发式技巧。因此,本文设计了一种端到端的DNN跟踪方法–Flow-Fuse-Tracker。
运动模型试图描述每个目标如何从一帧移动到另一帧,这是为下一帧中的每个目标选择最佳搜索区域的关键。现有的运动模型大致可以分为两类:一类是单目标模型,例如LSTM模型;另一类是多目标模型,例如光流。
外观模型的目的是学习目标的鉴别特征,使相同目标的跨帧特征比不同目标的特征更相似。如siamese网络、triplet网络和four plet网络,被广泛用于学习从检测到的对象边界盒中裁剪出的鉴别特征。
2. 贡献:
- 提出了一种端到端的DNN跟踪方法,可以联合学习目标运动和关联;
- 设计了一个FlowTracker DNN模块,从像素级的光流中联合学习无限个目标方向的运动。
- 设计了一个FuseTracker DNN模块,可以从跟踪和检测两个方面直接关联不确定的目标数目;
3. 方法:
1)目标流动。我们的FlowTracker不是从图像中提取目标方向的特征,而是首先通过光流估计所有像素的运动,然后细化每个目标的运动。该技术具有光流在所有目标上的像素级外观匹配。
2)目标融合。我们的FuseTracker不是比较目标之间的特征,而是通过细化它们的边界框和合并细化的目标来融合目标。这些操作是由一个单独的DNN模块FuseTracker执行的,这样来自不同来源(跟踪和检测)的目标就可以基于改进的边界框和可信度评分进行关联。与标准目标检测器的后处理类似,FuseTracker使用高效的非NMS算法来生成融合的目标。
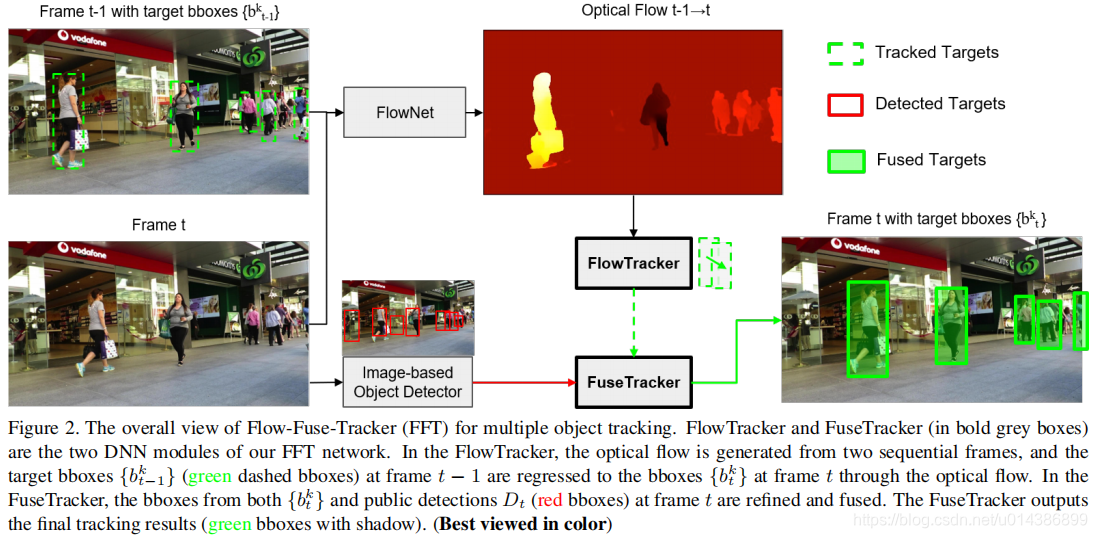
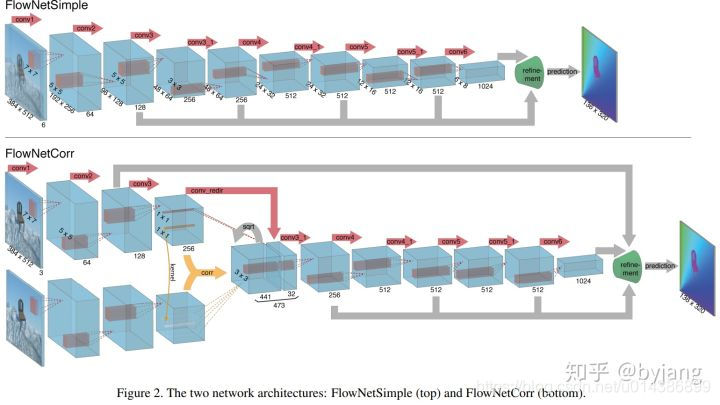
注flownet:FlowNet和它的升级版
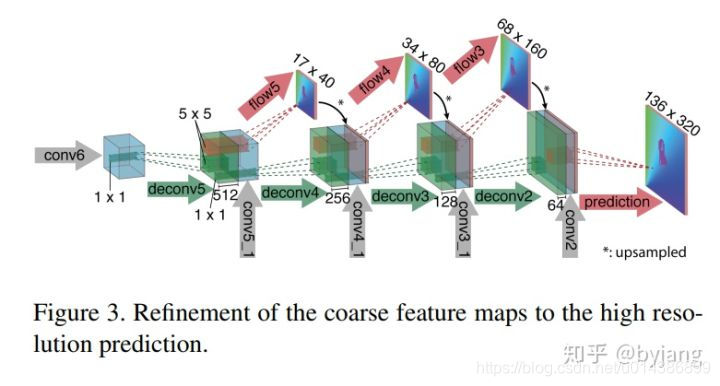
3.1 FlowTracker 模块
FlowTracker DNN模块的目标是通过像素级特征联合估计目标方向运动的不确定数量,即光流。我们的FlowTracker的网络架构如图3所示,其中我们只使用了几个卷积层和一个全连接(FC)层来估计从上一帧到当前帧的目标运动。一旦我们的FlowTracker被训练好了,它就会以两帧作为输入,并在两帧之间输出多个目标运动。

前一帧表示为 I t − 1 ∈ R 3 x ( w ) x ( h ) I_{t-1}\in R^{3x \mathcal(w) x \mathcal(h)} It−1∈R3x(w)x(h),当前帧表示为 I t ∈ R 3 x ( w ) x ( h ) I_t\in R^{3x \mathcal(w) x \mathcal(h)} It∈R3x(w)x(h),其中t > 1表示时间的 index。首先,我们将两帧图像输入到FlowNet中,在输出层得到一个像素级的光流 F t ∈ R 2 x ( w ) x ( h ) F_t \in R^{2x(w)x(h)} Ft∈R2x(w)x(h)。其次,我们将得到的光流输入到我们的流跟踪器中,并使用地面真值运动矢量对其进行训练。在实践中,前一帧通常有多个目标要在当前帧中跟踪。为简单起见,我们将前一帧中的目标表示为 B t − 1 = { b t − 1 k 1 , b t − 1 k 2 , . . . , b t − 1 k n ∣ 1 ≤ k 1 , k 2 , . . . , k n ≤ N } B_{t-1} = \{ b_{t-1}^{k1},b_{t-1}^{k2},...,b_{t-1}^{kn} | 1 \leq k_1,k_2,...,k_n \leq N \} Bt−1={bt−1k1,bt−1k2,...,bt−1kn∣1≤k1,k2,...,kn≤N},其中 b t − 1 k = ( x t − 1 k , y t − 1 k , w t − 1 k , h t − 1 k ) b_{t-1}^k = (x_{t-1}^k,y_{t-1}^k,w_{t-1}^k, h_{t-1}^k) bt−1k=(xt−1k,yt−1k,wt−1k,ht−1k)表示 k ∈ { k 1 , k 2 , . . , k n } k \in \lbrace k_1,k_2,..,k_n \rbrace k∈{k1,k2,..,kn}目标在 I t − 1 I_{t-1} It−1帧中的位置。当前帧中对应的目标用 B t = { b t k 1 , b t k 2 , . . . , b t k n ∣ 1 ≤ k 1 , k 2 , . . . , k n ≤ N } B_t = \lbrace b_t^{k1}, b_t^{k2},...,b_t^{kn} | 1 \leq k_1,k_2,...,k_n \leq N \rbrace Bt={btk1,btk2,...,btkn∣1≤k1,k2,...,kn≤N},其中 b t k = ( x t k , y t k , w t k , h t k ) b_t^k = (x_t^k,y_t^k,w_t^k,h_t^k) btk=(xtk,ytk,wtk,htk)表示 k ∈ { k 1 , k 2 , . . . , k n } k \in \lbrace k_1,k_2,...,k_n \rbrace k∈{k1,k2,...,kn}目标在 I t I_t It帧中的位置。因此,通过测量 B t − 1 B_{t-1} Bt−1和 B t B_t Bt之间的差异,可以很容易地学习目标运动。
损失函数
目标运动的损失函数为:
L 1 ( Δ B t , Δ B t ∗ ) = ∣ ∣ Δ B t − Δ B t ∗ ∣ ∣ F 2 L_1(\Delta B_t, \Delta B_t^*) = \vert\vert \Delta B_t - \Delta B_t^* \vert\vert_F^2 L1(ΔBt,ΔBt∗)=∣∣ΔBt−ΔBt∗∣∣F2 (1)
这里 Δ B t ∗ = B t − B t − 1 \Delta B_t^* = B_t - B_{t-1} ΔBt∗=Bt−Bt−1表示在 I t − 1 I_{t-1} It−1和 I t I_t It帧之间所有目标的 ground truth 运动向量, Δ B t \Delta B_t ΔBt表示我们FlowTracker DNN模块输出的运动向量。在训练过程中通过优化这个目标函数来更新FlowTracker DNN模块的参数,我们的Flow Tracker从 I t − 1 I_{t-1} It−1帧到 I t I_t It帧获得预测目标运动 Δ B t = { [ Δ x t k , Δ y t k , Δ w t k , Δ h t k ] } \Delta B_t = \lbrace [\Delta x_t^k, \Delta y_t^k, \Delta w_t^k, \Delta h_t^k] \rbrace ΔBt={[Δxtk,Δytk,Δwtk,Δhtk]}的能力。因此,我们可以很容易地估计出当前帧中的目标位置, B t = B t − 1 + Δ B t B_t = B_{t-1}+\Delta B_t Bt=Bt−1+ΔBt。当训练过程中不断学习到越来越多的目标运动时,我们的FlowTracker变得更加强大,可以将目标关联到相邻帧中。
3.2 FuseTracker 模块
FuseTracker DNN模块的作用是对FlowTracker B t = { b t k 1 , b t k 2 , . . . , b t k n ∣ 1 ≤ k 1 , k 2 , . . . , k n ≤ N } B_t = \lbrace b_t^{k_1},b_t^{k_2},...,b_t^{k_n} | 1\leq k_1,k_2,...,k_n \leq N \rbrace Bt={btk1,btk2,...,btkn∣1≤k1,k2,...,kn≤N},检测 D t = { d t i } ∣ i = 1 , . . . , m D_t = \lbrace d_t^i \rbrace |_{i=1,...,m} Dt={dti}∣i=1,...,m 进行细化和融合。FuseTracker的网络架构如图4所示。FuseTracker是修改自Fater-RCNN[48]。具体地,我们加入了特征金字塔网络(FPN)[37]来提取不同尺度的特征。在测试中,我们去掉了区域建议网络(RPN),使用FlowTracker目标和公共检测box作为建议。

无论是来自FlowTracker的目标还是来自基于图像的检测器的目标都不能直接作为目标传递到下一帧。一方面,来自我们的FlowTracker的目标包含标识(ID)索引 { k 1 , k 2 , . . . , k n ∣ 1 ≤ k 1 , k 2 , . . . , k n ≤ N } \lbrace k_1,k_2,...,k_n | 1 \leq k_1, k_2, ..., k_n \leq N\rbrace {k1,k2,...,kn∣1≤k1,k2,...,kn≤N}继承自 I t − 1 I_{t-1} It−1,但在帧t中可能存在不准确的bbox。另一方面,基于图像的检测器中的对象需要分配ID,要么获取FlowTracker目标的ID,要么生成新的ID。此外,即使一些FlowTracker目标和被检测到的目标可以匹配,在帧t中哪些bboxes应该被用于目标仍然是不清楚的。
FuseTracker解决了这一问题,处理两个FlowTracker目标Bt和检测对象Dt同等作为建议。形式上,FuseTracker接受来自Bt和Dt的bbox提案,并将其当前帧 I t I_t It作为输入。对于每一个提案,FuseTracker都会估计它的偏移量(cx, cy, w, h)和置信度(confidence score) c。给定两个细化的bbox集合 B t r e f B_t^{ref} Btref和 D t r e f D_t^{ref} Dtref, FuseTracker首先通过杀死置信度较低的bbox来处理消失的对象。然后应用两个级别的NMS(如图4中的“NMS*”所示)来合并bboxes。特别地,在细化的FlowTracker目标和检测到的对象中应用第一层NMS来处理对象的相互遮挡。第二级NMS采用基于IoU的bbox匹配和最大分数选择。此级别的NMS将从FlowTracker目标分配id给检测到的对象,并为融合的目标生成更精确的bbox。所有检测到的不继承目标id的对象都被视为新目标。
在训练FuseTracker时,与faster - rcnn[48]类似,RPN生成多个尺度的边界框建议,并根据每个建议裁剪特征图。然后将感兴趣区域(RoI)池应用于裁剪后的特征图,并将其分别传递给bbox分类头和回归头,得到目标分类分数和bbox位置偏移量。根据预测的分类分数、位置偏移量和地面真实边界框,我们最小化了多任务loss[24]的目标函数。检测头的损失函数定义为:
L 2 ( c , c ∗ , b , b ∗ ) = L c l s ( c , c ∗ ) + λ [ c ∗ ≥ 1 ] L r e g ( b , b ∗ ) L_2(c,c^*,b,b^*) = L_{cls}(c,c^*)+\lambda [c^* \geq 1]L_{reg}(b,b^*) L2(c,c∗,b,b∗)=Lcls(c,c∗)+λ[c∗≥1]Lreg(b,b∗), (2)
这里c和b=(x, y, w, h)分别是预测的分类分数和边界框的位置。 c ∗ c^* c∗和 b ∗ b^* b∗是对应的地面真值。分类损失 L c l s L_{cls} Lcls为对数损失,回归损失 L r e g L_{reg} Lreg为平滑L1损失。特别地,RPN部分的权值在训练期间是固定的,因为我们只是想用RPN产生模仿FlowTracker输出和公共检测结果的bbox提案。
在测试阶段,我们去掉了RPN,使用FlowTracker的目标Bt和来自公共探测器的边界框Dt作为建议。
3.3 推断算法
FFT推理算法联合运行FlowTracker和FuseTracker产生MOT输出(详见算法1)。综上所述,FFT推理算法共有7个步骤:
- 步骤1。第一帧D0的检测由 Fuse Tracker 进行细化。检测到的bboxes作为提案传递给FuseTracker。在这些 Fuse Tracker 的输出的bboxes中,那些置信分数小于阈值分数的框被杀死,并应用帧化(frame-wised)的NMS。微调的检测 D 0 r e f D_0^{ref} D0ref备用来初始化跟踪集合T。(Line 2-7)
- 步骤2。当前帧的检测 D t D_t Dt被 Fuse Tracker 使用与步骤1中相同的方法进行微调。
- 步骤3。前一帧 I t − 1 I_{t-1} It−1中所有被跟踪到的bboxes B t − 1 B_{t-1} Bt−1(带有轨迹id的bboxes)都在T中被找到。Flow Tracker 把图像对 { I t − 1 , I t } \{ I_{t-1}, I_t \} {It−1,It}和 B t − 1 B_{t-1} Bt−1作为输入,并在当前帧中产生相应的跟踪到的bboxes B t B_t Bt。
- 步骤4。Fuse Tracker 融合 B t B_t Bt和 D t r e f D_t^{ref} Dtref中的bboxes。我们首先像步骤1中那样微调 B t B_t Bt,然后,对于每个在 B t r e f B_t^{ref} Btref中的跟踪到的bbox b t k b_t^k btk,我们找出与 D t r e f D_t^{ref} Dtref有着最大IoU的bbox。如果这个IoU比阈值iou大,我们认为这个被检测到的bbox是与 b t k b_t^k btk匹配的。如果这个匹配的检测到的bbox的置信分数比 b t k b_t^k btk的分数高,那么我们用检测到的bbox来代替 b t k b_t^k btk。另外,NMS被应用到融合的bbox集合中来得到跟踪结果 B t t r k B_t^{trk} Bttrk。Fuse Tracker 返回NMS的输出 B t t r k B_t^{trk} Bttrk和不匹配的检测 D t u m t D_t^{umt} Dtumt。(Line 12)
- 步骤5。 B t t r k B_t^{trk} Bttrk中的bboxes被添加到集合T中相应的轨迹中。
- 步骤6。对于不匹配的检测 D t u m t D_t^{umt} Dtumt,我们进行回溯(更多细节看下面)到和它们匹配的轨迹 T n a s T_{nas} Tnas(在当前帧中没有被步骤2-5成功关联的轨迹)。(Line 14-19)
- 步骤7。回溯也不能被匹配的检测 D t u m t ′ D_t^{umt^\prime} Dtumt′被初始化为新轨迹。
回溯。在跟踪过程中,一些目标在前一帧中被遮挡或脱离场景,在当前帧中重新出现。为了处理这些情况,需要在当前帧和之前的几个帧之间重复跟踪。我们称这个过程为回溯(BT)。具体来说,对于轨迹 T n a s T_{nas} Tnas,我们试图找到这些轨迹 B n a s B_{nas} Bnas的盒子为较早的帧。我们使用FlowTracker将 B n a s B_{nas} Bnas中的bbox从之前的帧移动到当前帧的 B t ′ B_t^\prime Bt′。然后,使用Fuse Tracker 融合未匹配的 D t u m t D_t^{umt} Dtumt和 B t ′ B_t^\prime Bt′。这里,我们仅仅考虑能被匹配的轨迹。最后,我们将跟踪到的bboxes B t t r k ′ B_t^{trk^\prime} Bttrk′添加到相应的轨迹中。在BT中使用的帧数越多,就越有可能在遮挡的情况下跟踪到所有目标。我们在下面的消融研究部分研究BT帧数的影响。但是,随着BT帧数的增加,推理开销也随之增加。为了有效地实现,我们在不同的帧上自适应地应用不同数量的BTs,并在一个批处理中处理多个BTs。

4. 实验
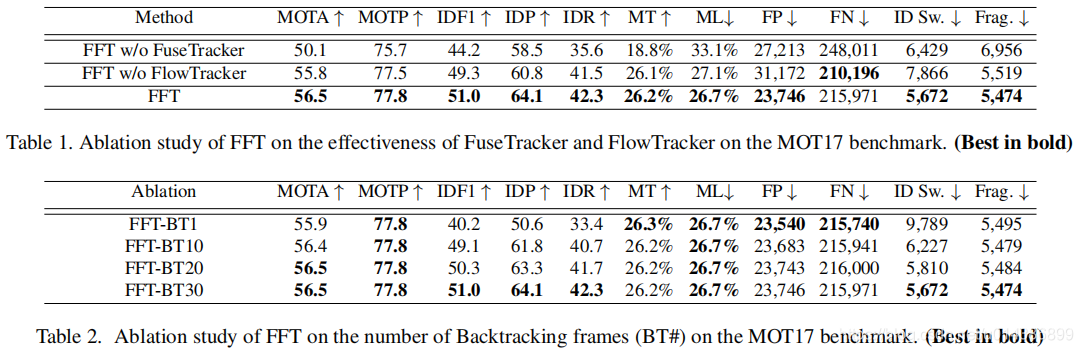
FuseTracker 是从 Faster-RCNN 改过来的,其中,我们把ResNet101+FPN 作为 backbone。
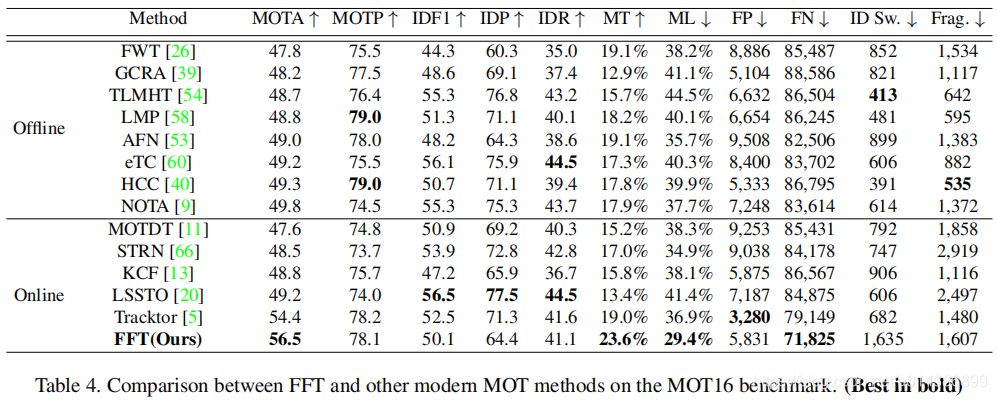
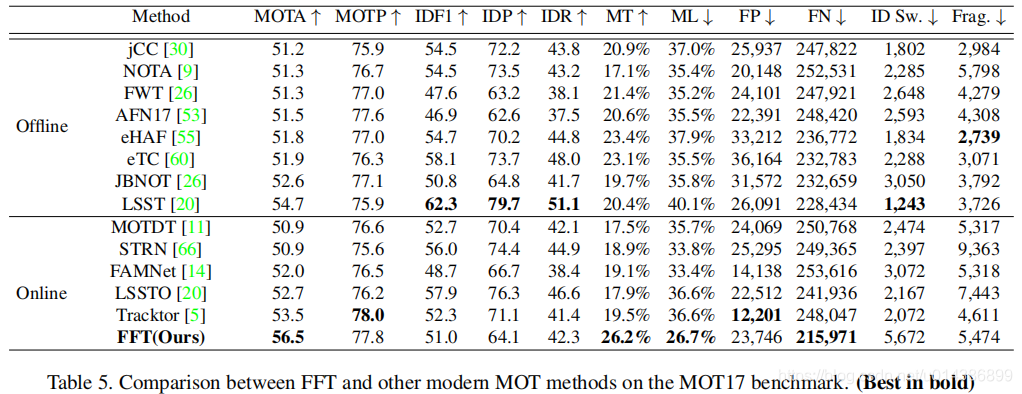
5. 疑问:
- 光流法对于移动的摄像头的图像怎么处理?
这篇关于【论文分享CVPR2020】Multiple Object Tracking by Flowing and Fusing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




