本文主要是介绍论文解析——异构多芯粒神经网络加速器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者
朱郭益, 马胜,张春元, 王波(国防科技大学计算机学院)
摘要
随着神经网络技术的快速发展, 出于安全性等方面考虑, 大量边缘计算设备被应用于智能计算领域。首先,设计了可应用于边缘计算的异构多芯粒神经网络加速器其基本结构及部件组成. 其次, 通过预计算异构芯粒上的计算负载, 将计算任务在神经网络通道上进行划分, 不断加入新的任务, 逐芯粒测试并进行迭代, 选取异构芯粒组合以构建神经网络加速器. 最后, 分别在抽样构造的测试神经网络、MobileNet 以及 ShuffleNet 上使用这种粗粒度优化的方法构建了异构多芯粒神经网络加速器, 并测试了其能耗与性能表现. 实验结果表明, 这种异构的设计方法可以在控制能耗同时, 分别取得 7.43, 2.30 和 5.60 的加速比。
正文
现有神经网络加速器的弊端
部件耦合程度高导致设计制造成本高
使用单一的芯粒,未考虑多样性
芯粒技术在神经网络加速器中的应用优势
设计复用性强
制造不同计算性能需求的 CPU, 仅需设计一次计算芯粒; 因此在保持整体架构不变的条件下, 考虑通过在单个芯片上集成数量不同的计算芯粒, 实现多种性能的芯片制造。
加速器的硬件和数据流的关系
现有的神经网络加速器的主要层次结构为“DRAM-全局缓存-计算单元”,如图所示:
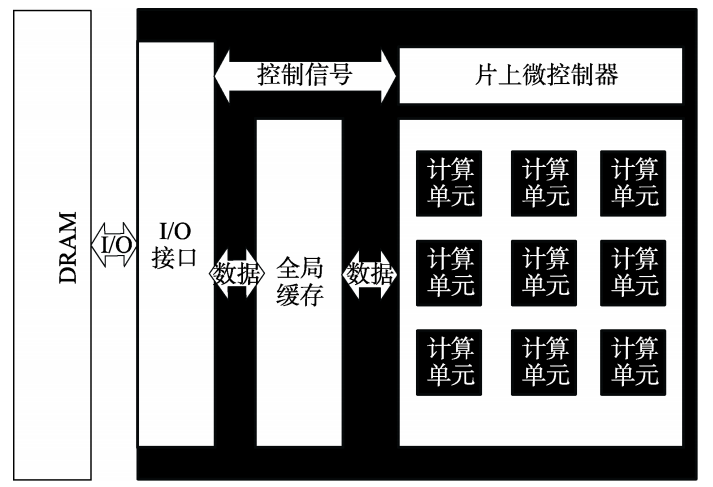
权重固定数据流
同一组权重会与多组输入的特征图进行计算, 权重在神经网络的计算过程中存在复用的机会。
该类型加速器在计算中先把权重放入计算单元的片上存储中进行存储, 再通过不断地更换输入特征图和输出的部分和完成神经网络的计算。例如NVIDIA的NVDLA。
输出固定数据流
输出固定数据流的神经网络加速器在片上寄存器中存放每个周期计算完成的部分和。 通过在计算过程中不断地更换计算时的输入数据与权重数据, 将结果累加到之前的部分和中, 最后完成输出数据的计算与数据的换入/换出操作。 例如Google 公司的 TPU。
行固定数据流
由于卷积运算中可以将高维的卷积操作拆分为一维的行卷积操作, 通过在依网格排布的计算单元中横向广播权重、斜向广播输入特征图, 在计算单元中实现输入特征图中一行与权重中一行的乘累加操作, 再在纵向进行一维卷积部分和的累加操作, 得到单层卷积计算的输出结果。例如 MIT 的 Eyeriss。
本文设计的神经网络加速器
异构多芯粒神经网络加速器的组成部分主要为 I/O 芯粒模块、控制单元以及计算芯粒阵列。
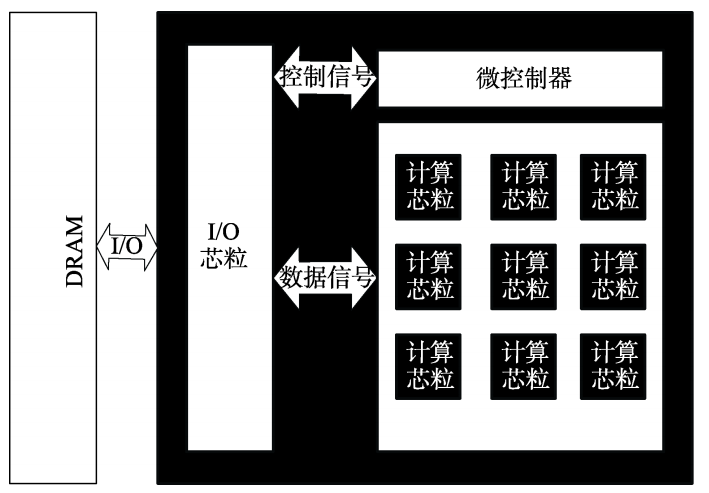
各类芯粒功能
IO芯粒
I/O 芯粒主要负责控制单元的信号传输以及计算芯粒阵列与 DRAM 间的数据交换。主要功能是传输数据信号至邻近的计算芯粒, 传输外部的控制信号至控制模块, 接收控制单元的控制信号, 并向外部设备传出计算完成的数据与设备中断信号。
计算芯粒
通过mesh网络互联。该阵列中的每一个芯粒单元均类似于传统的神经网络加速器, 每个芯粒拥有自己的片上缓存与片上计算单元, 可以异步执行分配的计算任务, 计算任务的数据包通过片上网络进行转发, 控制信号则由控制单元通过一对多的方式轮询与发送。
计算芯粒接口内联标准化
单个计算芯粒的外部连接接口均需要划分为接收块、发送块、时钟块与异步块, 并采用相同大小的接口设计。
每个计算芯粒通过异步块查询相邻的计算芯粒是否忙碌,从而判断是否接受数据
使用AIB作为芯粒间的接口
参考文献
[9] Shao Y S, Cemons J, Venkatesan R, et al. Simba: scaling deep-learning inference with chiplet-based architecture[J]. Communications of the ACM, 2021, 64(6): 107-116
[18] Wade M, Anderson E, Ardalan S, et al. TeraPHY: a chiplet technology for low-power, high-bandwidth in-package optical
I/O[J]. IEEE Micro, 2020, 40(2): 63-71
这篇关于论文解析——异构多芯粒神经网络加速器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





