本文主要是介绍解决matlab2018a配置官方LaSot toolkit报错问题:错误使用 legend>process_inputs (line 513),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近使用LaSOT toolkit来评估算法,生成漂亮的结果对比图。
toolkit使用matlab2018a遇到如题报错。
网上搜索都没有LaSOT toolkit类似解决问题,问题相对简单,下面给出解决方案:
报错如图所示:
报错原因为官方给的参数有问题,可能是以前老版本matlab的遗留问题,直接修改对应plot_draw_save.m 第63,64行位置参数即可,下面给出官方legend的location参数:

下面给出错误点,修改地方:
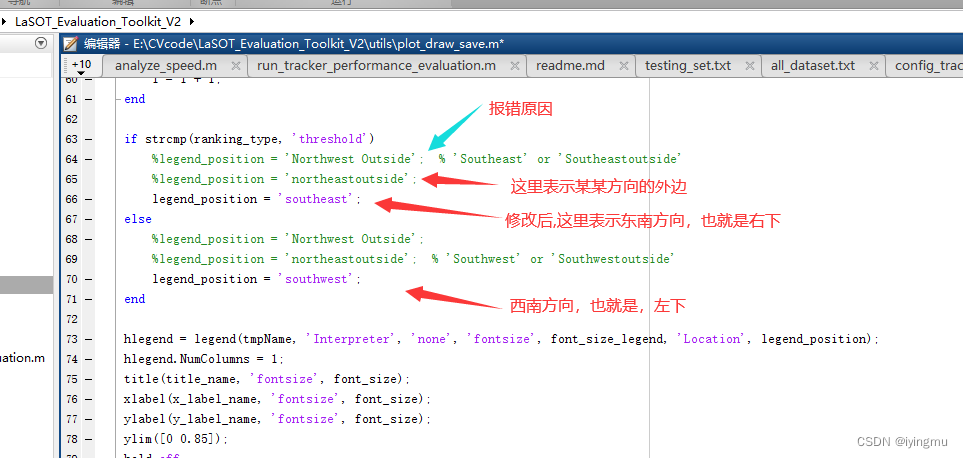
下面简单介绍toolkit使用:
官网链接:官网Lasot toolkit

下载解压,然后根据自己的运行数据集设置:

直接matlab 运行 run_tracker_performance_evaluation.m即可,出现上面报错直接解决。
评估自己算法,在utils/config_tracker.m中配置自己算法, publish 随便填一个,把不需要对比的算法注释掉。然后导入自己跟踪器运行的结果到/tracking_result下。运行即可

看自己需要设置需要的是Normalize精度图,还是成功率图等等设置:

运行即可,生成评估图。根据自己需要设置算法名称在图中的位置(上面已经提到):

根据自己需要,对应的评估对比图自己尝试即可,多尝试,多进步。
第一次记录,如有问题,多多指教。
有关长时数据集vot-lt评估,可以一起交流。
这篇关于解决matlab2018a配置官方LaSot toolkit报错问题:错误使用 legend>process_inputs (line 513)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





