本文主要是介绍fib系统分析(linux网络协议栈笔记),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FIB系统初始化
在Linux路由系统中主要保存了三种与路由相关的数据,第一种是在物理上和本机相连接的主机地址信息表——相邻表:neigh_table{ },第二种是保存了在网络访问中判断一个网络地址应该走什么路由的数据表——路由规则表:fib_table{ },第三种表是最新使用过的查询路由地址的缓存地址数据表——路由缓存:rtcache,由rtable{ }节点组成。它们三者之间的关系如下图:
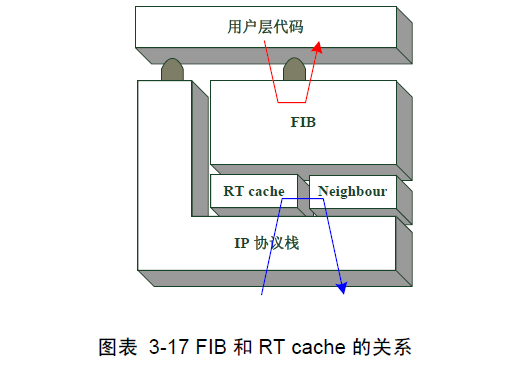
上图中FIB主要是和用户层打交道,而RT cache主要是和协议栈打交道,除非处于维护的目的,协议栈是不会去直接访问FIB系统。在一个基本稳定系统中,红线箭头表示用户操作流,蓝线箭头表示底层报文的路由查询过程。只有特殊情况,报文路由过程才会进入到FIB系统查询,这个原理和CPU访问Cache不命中然后才访问内存是一个道理。
现在回过来看ip_init,它一上来就调用ip_rt_init,为FIB搭好一个空架子:
// 路由缓存内存量指定办法:
// 1.通过启动参数rhash_entries指定hash表bucket个数
// 2.根据物理内存页数确定使用的内存量// 根据物理页数分配缓存内存:
// 1.goal目标内存页数=总页数/(2**(26-PAGE_SHIFT))
// 2.最接近goal内存页数的order,用于从伙伴系统中分配
// 3.rt_hash_mask=order页可容纳的bucket数
// 4.对齐rt_hash_mask到2的幂次
// 5.从伙伴系统中分配order页物理内存// 路由缓存阈值:
// 1.gc_thresh=bucket个数,当路由缓存数超过此阈值时,rt_garbage_collect同步回收内存
// 2.ip_rt_max_size=16*(bucket个数),当路由缓存超过此阈值时,dst_alloc会失败// 路由子系统初始化
// 调用路径:ip_init->ip_rt_init
// 函数主要任务:
// 1.分配dst缓存的slab缓存
// 2.分配路由缓存表
// 3.向netdev_chain注册监听块
// 4.初始化默认路由表
// 5.初始化路由缓存使用的定时器
// 5.1 垃圾回收定时器
// 5.2 缓存刷新定时器
// 5.3 缓存周期性刷新定时器
// 6.初始化IPSec与路由子系统交互的衔接点
int __init ip_rt_init(void)
{int i, order, goal, rc = 0;//rt_hash_rnd = (int) ((num_physpages ^ (num_physpages>>8)) ^(jiffies ^ (jiffies >> 7)));//dst缓存ipv4_dst_ops.kmem_cachep = kmem_cache_create("ip_dst_cache",sizeof(struct rtable),0, SLAB_HWCACHE_ALIGN,NULL, NULL);//根据物理内存数计算路由缓存使用的内存页数goal = num_physpages >> (26 - PAGE_SHIFT);if (rhash_entries)//rhash_entries为启动参数,goal = (rhash_entries * sizeof(struct rt_hash_bucket)) >> PAGE_SHIFT;//计算缓存使用内存页个数以2为底的orderfor (order = 0; (1UL << order) < goal; order++);//rt_hash_mask为bucket的个数do {rt_hash_mask = (1UL << order) * PAGE_SIZE /sizeof(struct rt_hash_bucket);//使rt_hash_mask 对齐到2的幂次while (rt_hash_mask & (rt_hash_mask - 1))rt_hash_mask--;//分配路由缓存rt_hash_table = (struct rt_hash_bucket *)__get_free_pages(GFP_ATOMIC, order);} while (rt_hash_table == NULL && --order > 0);for (rt_hash_log = 0; (1 << rt_hash_log) != rt_hash_mask; rt_hash_log++);//初始化每个bucket使用的自选锁rt_hash_mask--;for (i = 0; i <= rt_hash_mask; i++) {spin_lock_init(&rt_hash_table[i].lock);rt_hash_table[i].chain = NULL;}//垃圾回收的域值ipv4_dst_ops.gc_thresh = (rt_hash_mask + 1);//路由缓存最多保存的缓存个数ip_rt_max_size = (rt_hash_mask + 1) * 16;//per-cpu统计变量rt_cache_stat = alloc_percpu(struct rt_cache_stat);//向netdev_chain注册监听块,用netlink为地址和路由命令注册处理函数devinet_init();//初始化默认路由表ip_fib_init();//缓存刷新定时器init_timer(&rt_flush_timer);rt_flush_timer.function = rt_run_flush;//垃圾回收定时器init_timer(&rt_periodic_timer);rt_periodic_timer.function = rt_check_expire;//缓存刷新周期定时器init_timer(&rt_secret_timer);rt_secret_timer.function = rt_secret_rebuild;rt_periodic_timer.expires = jiffies + net_random() % ip_rt_gc_interval +ip_rt_gc_interval;add_timer(&rt_periodic_timer);rt_secret_timer.expires = jiffies + net_random() % ip_rt_secret_interval +ip_rt_secret_interval;add_timer(&rt_secret_timer);//处理路由子系统与IPSec的衔接
#ifdef CONFIG_XFRMxfrm_init();xfrm4_init();
#endifreturn rc;
}在这个函数中涉及到2个刚才提及的表的初始化:FIB表和路由表,但没有见到邻居表的初始化,那邻居表在哪初始化的呢?
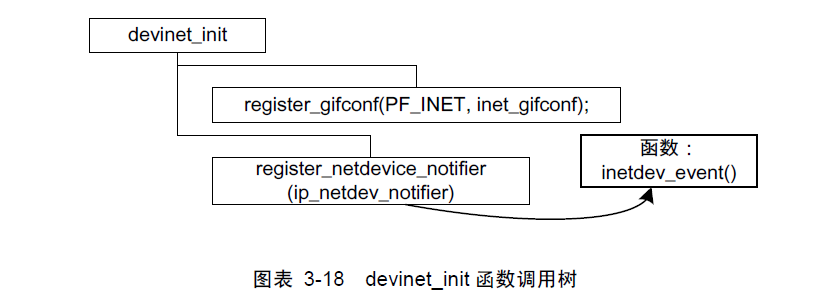
devinet_init( )的流程较简单,图示如下:
// 监听外部事件
// 调用路径:ip_rt_init->devinet_init
void __init devinet_init(void)
{//netdev_chian监听块register_netdevice_notifier(&ip_netdev_notifier);//通过netlink为路由命令注册处理程序rtnetlink_links[PF_INET] = inet_rtnetlink_table;
}此函数主要是注册两个事件通知回调函数,前面一个回调函数对于本书没有太多意义,所以不会介绍;而第二个函数注册的是一个叫做ip_netdev_notifier的通知块,其处理函数是inetdev_event,即产生某些事件的时候,会以通知的形式回调此函数。
回想一下在设备接口初始化例程中第3步和第4步我们有两次发送事件,一次是发送NETDEV_REGISTER,一次是NETDEV_UP事件,这两个事件都会引起inetdev_event的调用。
那下面要分析的fib相关的函数虽然重要,但内部操作并不复杂。
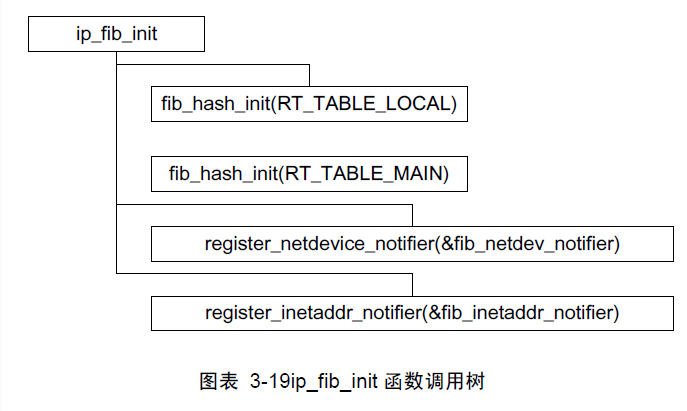
ip_fib_init注册了2个通知块,这里可要看清楚了(我当初就因为眼花而没有注意到这个差别),一个是挂到netdev_chain上,前面介绍的devinet_init函数也挂接了一个通知块在上面;另一个是挂到了inetaddr_chain上,也就是说,fib系统对设备相关的事件和ip地址相关事件都感兴趣。
回过去来看fib_hash_init,它的作用看似也简单,就是申请一块大内存,还指定这块内存的函树指针,代码如下:
/* 只在初始化的时候创建local和main路由表 */
struct fib_table * __init fib_hash_init(u32 id)
{struct fib_table *tb;if (fn_hash_kmem == NULL)fn_hash_kmem = kmem_cache_create("ip_fib_hash",sizeof(struct fib_node),0, SLAB_HWCACHE_ALIGN,NULL, NULL);if (fn_alias_kmem == NULL)fn_alias_kmem = kmem_cache_create("ip_fib_alias",sizeof(struct fib_alias),0, SLAB_HWCACHE_ALIGN,NULL, NULL);tb = kmalloc(sizeof(struct fib_table) + sizeof(struct fn_hash),GFP_KERNEL);if (tb == NULL)return NULL;tb->tb_id = id;tb->tb_lookup = fn_hash_lookup;tb->tb_insert = fn_hash_insert;tb->tb_delete = fn_hash_delete;tb->tb_flush = fn_hash_flush;tb->tb_select_default = fn_hash_select_default;tb->tb_dump = fn_hash_dump;memset(tb->tb_data, 0, sizeof(struct fn_hash));return tb;
}这块内存可不简单,它是我们之前提到的FIB表,就是所谓的路由数据库,系统的路由信息全部放在里面。ip_fib_init初始化了2个FIB表,一个是local的,一个是main的
深入FIB系统
首先从路由算法说起,因为老学究们一提起路由必谈算法,这里先满足这一部分人。目前的内核路由存在两种查找算法,一种为HASH算法,另一种为LC-trie算法,在配置内核网络选项的时候选择”IP: advanced router“,然后进入”Choose IP: FIB lookup algorithm (choose FIB_HASH if unsure)“,会看到这两种算法。如果不选择“advanced router”,那么还是使用hash算法。Hash算法是目前Linux内核使用的缺省算法,对于大多数应用足够了,而LC-trie使用最长前缀匹配算法,在超大路由表的情况下性能比Hash算法好,但它大大地增加了算法本身的复杂性和内存的消耗。只可惜这里不能提供更多的关于算法的知识,让老学究们失望了。不过这里要解释FIB表是如何被存取的,这才是现实情况下开发人员最关心的事。 我们注意到ip_fib_init函数是放在一个叫做fib_frontend.c的文件中,frontend,即前端的意思。也就是说,FIB系统分为前端和后端,前端部分包含处理一些和外部系统打交道的函数接口(比如rtnetlink socket),比如初始化、增删路由、接口地址改变等。而后端是FIB内部逻辑操作,选择是否支持路由策略及哪种算法由用户在编译内核的时候决定,但改变内核之后,上层/外部应用并不会感知这种变化。
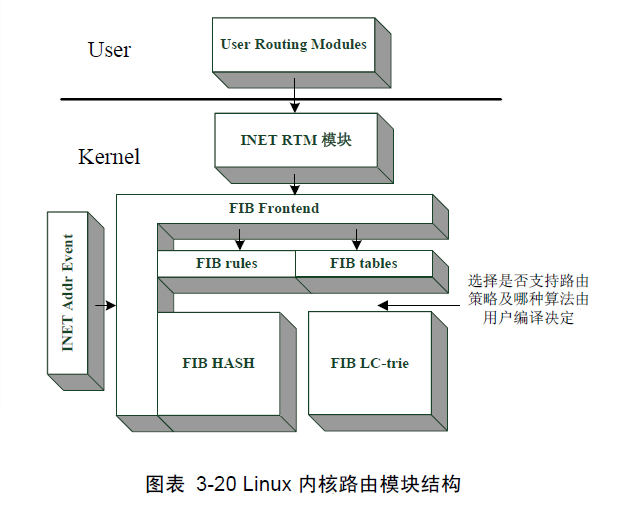
当选择高级路由后,你还可以选择是否支持策略路由(Policy routing),即Linux使用了多个路由表来应付有多种路由算法存在的情况,Linux使用多个路由表,使不同策略的路由存放在不同的表中,有效地被免了查找庞大的路由。即使不使用策略路由,出于性能的考虑,Linux也使用了两个路由表,一个用于上传给本地上层协议,另一个则用于转发。从效果上看,假设我们有多个路由算法(OSPF,RIP,BGP,静态配置等)同时存在于一台机器上,每个路由算法可以选择不同的FIB 表作为自己的内核数据库,那么当报文到达IP层时选择哪一个数据库作为如何处理(转发?送到本机?还是丢弃)的参考时,就依靠一种规则了。可以是一种算法存取一个FIB表,也可以多个算法存取一个FIB表。这就是Policy Route。比如说,对于本地接收的报文应该采用一种规则,那么可以为其单独创建一个FIB表;对于组播路由的报文应该采用不同的规则,也可以为其单独创建一个FIB表……
为了支持多种路由算法和多个路由表,Linux内核创造了一个名词:FIB规则。这个规则是指处理报文时选取FIB表的规则。规则是策略性的关键性的新的概念。
我们可以用自然语言这样描述规则,例如我门可以指定这样的规则:
规则一:“所有来自1.1.1.1的IP包,使用路由表253, 本规则的优先级别是100”
规则二:“所有的包,使用252号路由表,本规则的优先级别是200” 优先级别越高的规则越先匹配(数值越小优先级别越高)。
路由规则和FIB表之间的关系如下图所示:
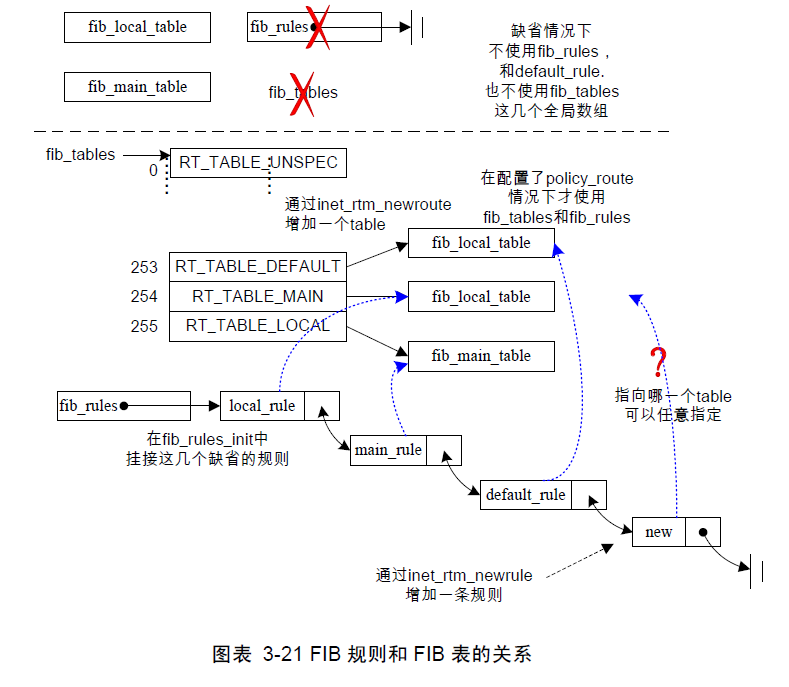
如果没有配置Policy Routing,我们也还是有路由规则的,但是,这种情况下的路由选择相对简单,就是本地和通向相邻主机的路由,于是在代码中就不需要fib_rules了(在2.6.14的代码中还是用到了这个变量),只是从概念上为这两种路由划分了“规则”,凡是本地路由,都使用fib_local_table这个数据库,而发往相邻主机的路由(目的地不一定是相邻主机),都使用fib_main_table这个数据库
struct fib_rule
{ struct list_head list;//策 略 规 则 链 表 atomic_t refcnt;//引 用 计 数 int ifindex;//接 口 index char ifname[IFNAMSIZ];//接 口 名 称 u32 mark;//mark 值 u32 mark_mask;//mark 掩 码 值 u32 pref;//优先级, 值越小优先级越大 u32 flags; u32 table;//路由表id u8 action;//规则 u32 target; struct fib_rule * ctarget; struct rcu_head rcu; struct net * fr_net;
};
/*-------*/
//以下3个默认ipv4 fib rule是没有设置匹配条件的,即只要遍历到下面3个ipv4 fib rule规则,即会匹配
static struct fib4_rule default_rule = {.common = {.refcnt = ATOMIC_INIT(2),.pref = 0x7FFF,.table = RT_TABLE_DEFAULT,.action = FR_ACT_TO_TBL,},
};static struct fib4_rule main_rule = {.common = {.refcnt = ATOMIC_INIT(2),.pref = 0x7FFE,.table = RT_TABLE_MAIN,.action = FR_ACT_TO_TBL,},
};static struct fib4_rule local_rule = {.common = {.refcnt = ATOMIC_INIT(2),.table = RT_TABLE_LOCAL,.action = FR_ACT_TO_TBL,.flags = FIB_RULE_PERMANENT,},
};3个fib_rule实体去选择“永久的”FIB表:main表,local表,如果没有指定的表,则选择缺省的表。当定义了一个新的FIB规则后,它会加到链表的末尾。缺省规则表的table号是253,指向fib_tables的第253号单元。依次类推,Main表规则的号码是254,Local表规则的号码是255,分别指向了fib_tables的相对单元。
如何进行进入、删除、查找规则呢?其实这是由应用程序使用rtnetlink接口来操作,首先通过从用户空间传递nlmsghdr消息到内核。nlmsghdr结构放在rtmsg结构前面,包括了用来确定使用什么规则的大部分信息。内核rtm模块对这些消息进行解析,然后对应到合适的函数,如图中,当要增加一条路由规则时,就调用inet_rtm_newrule,把新增的规则挂接到fib_rules链上,如果要增加一个FIB表,就调用inet_rtm_newroute,并且参数中要指定创建一个新表,如此就把新增FIB表放入fib_tables中。由于这些不是我们的研究重点,所以我们可以跨过
知道路由规则是干什么的了,那么我们可以下断言了:查找路由规则是查找路由的第一步! 是的,要查找路由则必须先搜索fib_rules以找到最匹配报文规则,必须同时满足4个条件:
1. 报文源地址与规则涵盖的源地址属于同一子网
2. 报文目的地址与规则涵盖的目的地址属于同一子网
3. 报文头设置的TOS(如果配置了tos路由的话)与规则设置的一致
4. 报文始终的网络接口设备(如果指定了接口的话)与规则设置的一致
如果满足这4个条件,即搜索到一条这样的规则,找到了规则才能找FIB表。然后检查规则中的r_action,如果我们为这样的action预备了一个FIB表,那么我们就得到正确的FIB表去搜索路由。对于缺省情况,r_action都是RTN_UNICAST,所以,local表和main表是可以被搜索的。
(注:上面所说是2.6.14之前的代码运行原理,而2.6.18之后的代码已经不这么折腾了。在缺省情况下,不搜索FIB规则链表,直接去搜索local表和main表。)
找到了FIB表,我们就可以调用FIB表的自身的lookup函数,这类似于C++中的概念:成员函数只能访问类本身的成员变量。现在搜索FIB表就是查找路由的第二步。
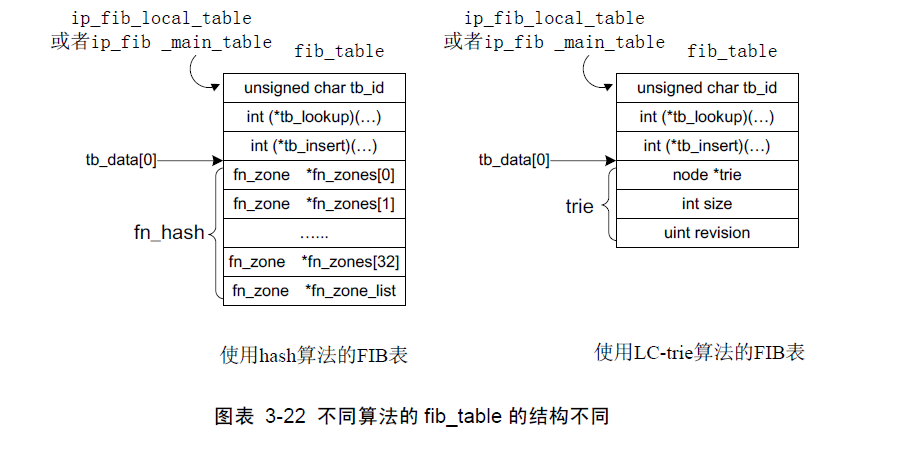
问题是FIB表本身不是由一个数据结构表示,而是由多个结构组合而成。前面说到我们缺省使用HASH算法进行查找,那么所谓的hash就在此刻出现了,而对于使用LC-trie算法的FIB表,我们不会看到hash这么一个数据结构。所以只能说,采用hash算法的FIB表系统是一个分层的结构组合。
下面看FIB内部数据结构定义。
struct fib_table{
/*tb_id字段是表的id,如果配置了多个表,它的值在1到255之间。如果没有配置多个表,则只会RT_TABLE_MAIN或RT_TABLE_LOCAL,tb_stamp目前没有使用。*/ uchar tb_id; uint tb_stamp; int (*tb_lookup)(struct fib_table *tb,const struct flowi *flp, struct fib_result *res);int (*tb_insert)(struct fib_table *table, struct rtmsg *r,struct kern_rta *rta, struct nlmsghdr *n,struct netlink_skb_parms *req);int (*tb_delete)(struct fib_table *table, struct rtmsg *r,struct kern_rta *rta, struct nlmsghdr *n,struct netlink_skb_parms *req);int (*tb_dump)(struct fib_table *table, struct sk_buff *skb,struct netlink_callback *cb);int (*tb_flush)(struct fib_table *table);void (*tb_select_default)(struct fib_table *table,const struct flowi *flp, struct fib_result *res);/*从表中获取所有的路由,这主要由rtnetlink使用inet_dump_fib调用它。int (*tb_dump)(...) 操作删除fib_table中所有的表项int (*tb_flash)(...) 选择缺省的路由void (*tb_select_default) tb_data是指向hash表项的一个不透明指针,此表中的其他函数操作此字段,它不能被直接访问。*/uchar tb_data[0];
}最后一个数据成员是tb_data[0],它利用了编译器的一些特点,专门用来存放未知大小的数据。当用hash算法时,这个数据成员就是一个fn_hash{}结构;而当使用LC-trie算法时,它却是一个trie{}结构,这样可以充分节省空间。为什么不用void*指针呢?因为在创建一个fib_table的同时,就已经为这些数据结构预留了空间,避免了再一次申请内存,操作起来也方便(请仔细观察上面的fib_hash_init)。如下图:
Linux的FIB表是分层的,从逻辑上来看可以分为5层:
第1层: 根据本地路由与否,分为local FIB库和main FIB库,这容易被大家忽略
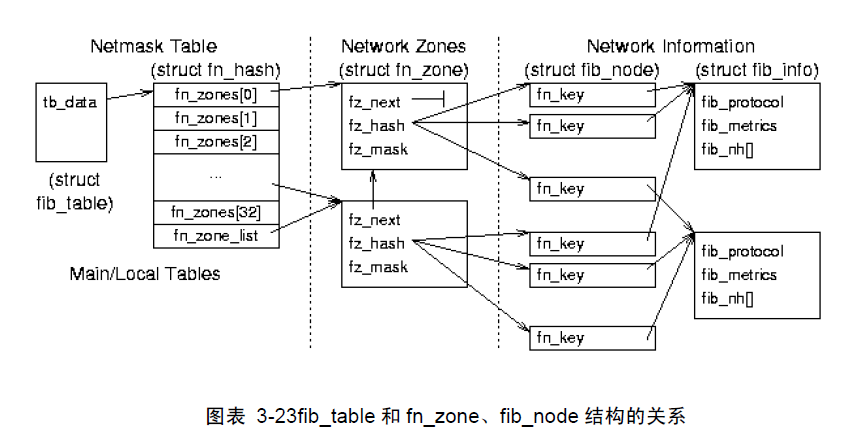
第2层: FIB表中的fn_hash数组由33个fn_zone{}结构的指针组成。它将所有的路由根据子网掩码(netmask)的长度(0~32)分成33个部分(struct fn_zone),每一个zones代表一个唯一确定的netmask。fn_hash{}最后一个成员指向掩码最长的zone区,这有什么用呢?以后探讨
第3层:fn_zone{}也有一个hash表,凡子网掩码长度都相同的路由都放在其中,hash表的节点叫fib_node{},比如10.1.1.0/24和10.1.2.0/24挂到了同一个fn_zone的链表上。
第4层: 在同一子网中,有可能由于TOS等属性的不同而使用不同的路由,那么每一个fib_node{}节点有一个链表存放以fib_alias{}结构为节点的路由表项,即使某fib_node上只有一条路由,也必须有一个fib_alias{}保存路由的tos、类型、范围等属性,不过但到此层还没有指出下一跳出口。
第5层: fib_alias{}只包含一个fib_info{}结构,此结构包括一些相应的参数,如协议,下一跳主机地址、外出的接口设备等等,这就是第5层。
分层的好处是显而易见的,它使路由表的更加优化,逻辑上也更加清淅,并且使数据可以共享(如struct fib_info),从而减少了数据的冗余。下面我们一级一级的列出这几个结构的定义。先上fn_zone{}的结构,包含所有同长度子网掩码的路由
struct fn_zone{struct fn_zone *fz_next; //指向下一个zone的指针,比如目前是fn_zone[24],如果fn_zone[16]有路由而16到24都没有路由,则指向fn_zone[16]struct hlist_head *fz_hash; //这个hash表结构才是体现这是HASH算法的地方。int fz_nent; //表示在此zone的入口(实际就是fib_node{})的个数int fz_divisor;//和此zone相关的fz_hash表的桶数,大多数zones都有16个,故此值为16,但0 zone除外,它的值为1u32 fz_hashmask; //进入fz_hash的mask,一般为fz_divisor - 1int fz_order; //表示该zone处于fn_hash表的什么位置u32 fz_mask; //该zone所表示的掩码区,例如16位子网则是0xFFFF,如果是24位,则是0xFFFFFFF};每个路由的节点fib_node{},这个结构非常小,但是却是所谓HASH算法的来源,请注意那个fn_key,它就是找到对应的hash节点的键值:
struct fib_node {struct hlist_node fn_hash;//链到fz_hash的节点,注意不是fn_alias{}的hash链struct list_head fn_alias;//这个才是挂接fn_alias{}的链表u32 fn_key;//下面这个成员是最重要的值,实际上就是路由查找的关键};如果有不同的tos,那么节点可能有多个fib_alias{},不过其路由节点的属性其实是放在这个结构中,这里又看见一个“alias”单词,它不是指别名的意思,而是指到达同一路由的不同路径的集合(我个人的意见:有必要为了tos而专门设置一条链表吗?),要匹配这样一个alias,要有唯一确定的3元组:<地址,tos,priority>,其中地址可以顺着fib_node找到,而后面两个是fib_alias{}独有的,以后的分析还会看到这三元组:
struct fib_alias {struct list_head fa_list; //链到fib_node->fn_alias链的节点struct rcu_head rcu;struct fib_info *fa_info; //关于此结点的更多的信息u8 fa_tos;u8 fa_type; //路由类型u8 fa_scope; //路由范围u8 fa_state; //此路由的状态,目前只有FA_S_ACCESSED和0两个值,缺省是0,如果被搜索过,则是前者。};在这个结构中我们接触到几个名词:
Scope:在Linux中,路由的scope表示到目的网络距离的一种分类。
Type:其实指得是主机如何处理路由,例如当发现此路由类型是local的,则应该上报,如果是unicast,很可能转发。
路由类型和路由范围有一定关系。回忆之前给设备分配设备的时候,都是设置为RTN_LOCAL,那么到达该IP地址的路由范围肯定是RT_HOST,如果应用层路由协议比如OSPF往内核中设置一条到远端主机的路由,那么类型可以是RTN_UNICAST,那么范围很可能是RT_SCOPE_ UNIVERSE。以后的分析将会给出明证。
在fib_semantics.c这个文件中有一个fib_props结构数组,对我们了解两者之间的关系有一定帮助:
const struct fib_prop fib_props[RTN_MAX + 1] = {[RTN_UNSPEC] = {.error = 0,.scope = RT_SCOPE_NOWHERE,/* RTN_UNSPEC类型的报文路由范围是NOWHERE */},[RTN_UNICAST] = {.error = 0,.scope = RT_SCOPE_UNIVERSE,/* RTN_UNICAST类型的报文路由范围是UNIVERSE*/},[RTN_LOCAL] = {.error = 0,.scope = RT_SCOPE_HOST,/* RTN_LOCAL类型的报文路由范围是HOST */},[RTN_BROADCAST] = {.error = 0,.scope = RT_SCOPE_LINK,/* RTN_BROADCAST 类型的报文路由范围是LINK*/},[RTN_ANYCAST] = {.error = 0,.scope = RT_SCOPE_LINK,/* RTN_ANYCAST 类型的报文路由范围是LINK*/},[RTN_MULTICAST] = {.error = 0,.scope = RT_SCOPE_UNIVERSE,/* RTN_MULTICAST 类型的报文路由范围是UNIVERSE*/},[RTN_BLACKHOLE] = {.error = -EINVAL,.scope = RT_SCOPE_UNIVERSE,},[RTN_UNREACHABLE] = {.error = -EHOSTUNREACH,.scope = RT_SCOPE_UNIVERSE,},[RTN_PROHIBIT] = {.error = -EACCES,.scope = RT_SCOPE_UNIVERSE,},[RTN_THROW] = {.error = -EAGAIN,.scope = RT_SCOPE_UNIVERSE,},[RTN_NAT] = {.error = -EINVAL,.scope = RT_SCOPE_NOWHERE,},[RTN_XRESOLVE] = {.error = -EINVAL,.scope = RT_SCOPE_NOWHERE,},
};fib_info{}包含关于一个接口的协议和特定的硬件信息,并且对于一些zones是公共信息,因为几个目的网络可以同时经过同一个接口出去。
struct fib_info {struct hlist_node fib_hash;struct hlist_node fib_lhash;int fib_treeref;atomic_t fib_clntref;int fib_dead;unsigned fib_flags;int fib_protocol;//指示本路由是哪个模块来创建的,其值就是rtmsg->rtm_protocolu32 fib_prefsrc;//fib_prefsrc是一个偏向使用的源地址,它作为一个“指定目的地址”,被UDP用作回应报文的源地址。u32 fib_priority;u32 fib_metrics[RTAX_MAX];
#define fib_mtu fib_metrics[RTAX_MTU-1]
#define fib_window fib_metrics[RTAX_WINDOW-1]
#define fib_rtt fib_metrics[RTAX_RTT-1]
#define fib_advmss fib_metrics[RTAX_ADVMSS-1]int fib_nhs;//fib_nhs是下一跳的数量,如果该路由有一个已定义的网关,则应该是1;否则它就是0。但是,如果 配置了多路径路由,则它有可能大于1。
#ifdef CONFIG_IP_ROUTE_MULTIPATHint fib_power;
#endif
#ifdef CONFIG_IP_ROUTE_MULTIPATH_CACHEDu32 fib_mp_alg;
#endifstruct fib_nh fib_nh[0]; //fib_nh包含关于下一跳或下一跳链表的信息,如果超过一个的话。fib_dev是特指到达下一跳主机的网络接口设备。
#define fib_dev fib_nh[0].nh_dev};顺便也介绍fib_nh数据结构,通过路由机制去抽取关于下一跳或网关的信息去修改它。
struct fib_nh {struct net_device *nh_dev;struct hlist_node nh_hash;struct fib_info *nh_parent;unsigned nh_flags;unsigned char nh_scope; //nh_scope和fib_alias结构里的scope字段相似,它并没有真正定义路由的范围,而是概念上到目的主机的距离,在这种情况下,是网关。
#ifdef CONFIG_IP_ROUTE_MULTIPATHint nh_weight;int nh_power;
#endif
#ifdef CONFIG_NET_CLS_ROUTE__u32 nh_tclassid;
#endifint nh_oif; //输出到网关机器接口的索引号u32 nh_gw;};本篇完整的讲述了FIB表的组成结构,以后的分析继续配置的例子,分析完FIB系统。
这篇关于fib系统分析(linux网络协议栈笔记)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








