本文主要是介绍redis中高并发问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高并发问题
Redis 做缓存虽减轻了 DBMS 的压力,减小了 RT,但在高并发情况下也是可能会出现各
种问题的。
1 缓存穿透
当用户访问的数据既不在缓存也不在数据库中时,就会导致每个用户查询都会“穿透”
缓存“直抵”数据库。这种情况就称为缓存穿透。当高度发的访问请求到达时,缓存穿透不
仅增加了响应时间,而且还会引发对 DBMS 的高并发查询,这种高并发查询很可能会导致
DBMS 的崩溃。
缓存穿透产生的主要原因有两个:一是在数据库中没有相应的查询结果,二是查询结果
为空时,不对查询结果进行缓存。所以,针对以上两点,解决方案也有两个:
对非法请求进行限制
对结果为空的查询给出默认值
2 缓存击穿
对于某一个缓存,在高并发情况下若其访问量特别巨大,当该缓存的有效时限到达时,
可能会出现大量的访问都要重建该缓存,即这些访问请求发现缓存中没有该数据,则立即到
DBMS 中进行查询,那么这就有可能会引发对 DBMS 的高并发查询,从而接导致 DBMS 的崩
溃。这种情况称为缓存击穿,而该缓存数据称为热点数据。
对于缓存击穿的解决方案,较典型的是使用“双重检测锁”机制。
3 缓存雪崩
对于缓存中的数据,很多都是有过期时间的。若大量缓存的过期时间在同一很短的时间
段内几乎同时到达,那么在高并发访问场景下就可能会引发对 DBMS 的高并发查询,而这将
可能直接导致 DBMS 的崩溃。这种情况称为缓存雪崩。
对于缓存雪崩没有很直接的解决方案,最好的解决方案就是预防,即提前规划好缓存的
过期时间。要么就是让缓存永久有效,当 DB 中数据发生变化时清除相应的缓存。如果 DBMS
采用的是分布式部署,则将热点数据均匀分布在不同数据库节点中,将可能到来的访问负载均衡开来
数据库缓存双写不一致(难点)
以上三种情况都是针对高并发读场景中可能会出现的问题,而数据库缓存双写不一致问
题,则是在高并发写场景下可能会出现的问题。
对于数据库缓存双写不一致问题,以下两种场景下均有可能会发生:
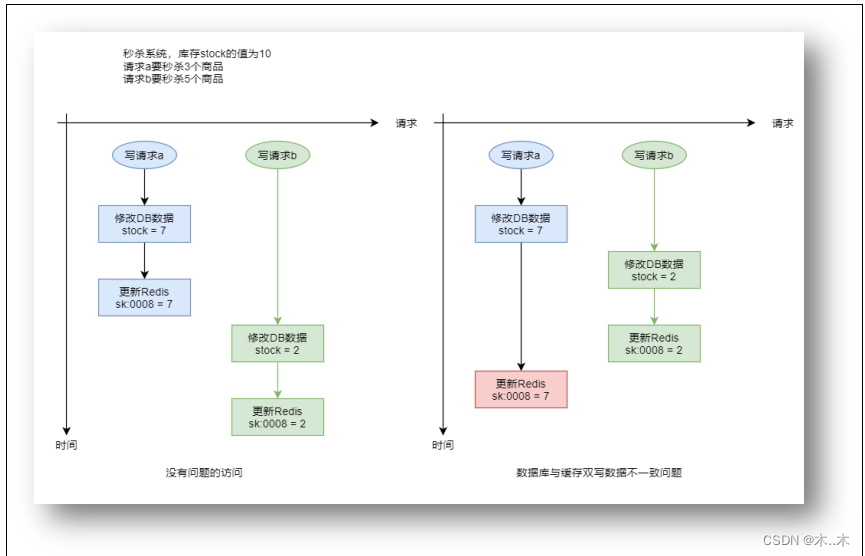
(1) “修改 DB 更新缓存”场景
对于具有缓存 warmup 功能的系统,DBMS 中常用数据的变更,都会引发缓存中相关数
据的更新。在高并发写请求场景下,若多个请求要对 DBMS 中同一个数据进行修改,修改后
还需要更新缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。
(2) “修改 DB 删除缓存”场景
在很多系统中是没有缓存 warmup 功能的,为了保持缓存与数据库数据的一致性,一般
都是在对数据库执行了写操作后,就会删除相应缓存。
在高并发读写请求场景下,若这些请求对 DBMS 中同一个数据的操作既包含写也包含读,
且修改后还要删除缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。

(3) 解决方案:延迟双删
延迟双删方案是专门针对于“修改 DB 删除缓存”场景的解决方案。但该方案并不能彻
底解决数据不一致的状况,其只可能降低发生数据不一致的概率。
延迟双删方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停上一段
时间(一般为几秒)后再进行一次删除。而两次删除中间的间隔时长,要大于一次缓存写操
作的时长。

(4) 解决方案:队列
以上两种场景中,只所以会出现数据库与缓存中数据不一致,主要是因为对请求的处理
出现了并行。只要将请求写入到一个统一的队列,只有处理完一个请求后才可处理下一个请
求,即使系统对用户请求的处理串行化,就可以完全解决数据不一致的问题。
(5) 解决方案:分布式锁
使用队列的串行化虽然可以解决数据库与缓存中数据不一致,但系统失去了并发性,降
低了性能。使用分布式锁可以在不影响并发性的前提下,协调各处理线程间的关系,使数据
库与缓存中的数据达成一致性。
只需要对数据库中的这个共享数据的访问通过分布式锁来协调对其的操作访问即可。
这篇关于redis中高并发问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








