本文主要是介绍数据解读:中国高校招生如何不平等?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注「实验楼」,每天分享一个项目教程
根据清华大学校内论坛的信息,我抓取了2006到2013年间各省(即各考区)就读清华的人数。由于清华在中国高等教育中占据特殊地位,这份数据不失为探索中国高校招生地域不平等问题的起点。
正文共:3360 字
预计阅读时间:9 分钟
中国高校招生的地域性不平等已不是新闻。我们以清华大学的就读人数为例,探索问题的症结。

中国高校招生的地域性不平等,早已不是新闻。每年在各大论坛和高考讨论群里,都有学生和家长愤愤地指出自己心仪的学校在本省的招生数量远少于其他省份。由于学生必须在户籍所在地参加高考,所以高校给各省分配不同的“招生名额”,相当于给每位考生出生时就设下了高矮不一的门槛。
过往的媒体或网络讨论,对高校在各省招生情况的分析往往存在缺陷。有的文章比较了高校在各省的分数线,但由于各省考卷不同,比较分数线高低没有意义。另一些分析则参考了大学高考前公布的招生计划,但由于实际入学人数与计划招生人数通常有很大出入,所以单纯比较计划招生人数远远不够。例如,清华大学2013年计划在北京招203人,但实际有368名北京考生入学,是计划的1.8倍。实际招生人数超出计划并不是“黑幕”——计划外的考生都是通过保送、自主招生等公开渠道被录取的,且各省都有。
由于实际入学人数和计划差异较大,且我们有理由猜测在发达地区差异更大,所以做一个对实际入学人数的分析就显得尤为重要。
根据清华大学校内论坛的信息,我抓取了2006到2013年间各省(即各考区)就读清华的人数。由于清华在中国高等教育中占据特殊地位,这份数据不失为探索中国高校招生地域不平等问题的起点。
谁的清华?
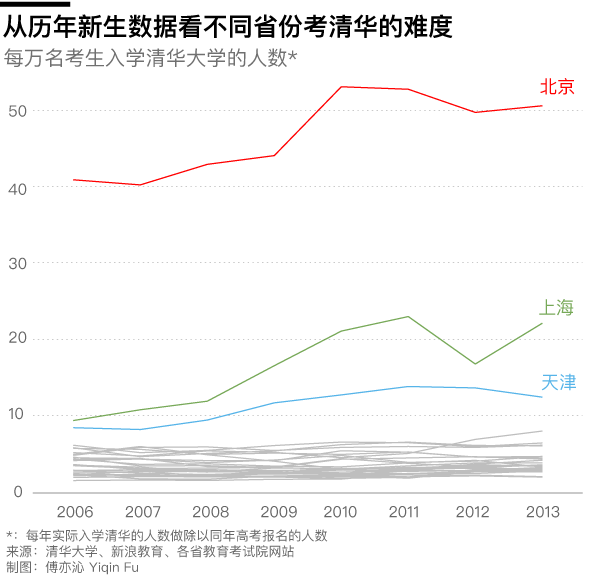
下图中,我们把每年实际入学清华的人数做为分子,同年高考报名的人数做为分母,计算了各省每万名考生中入学清华的人数,后文简称“清华率”。很明显,北京、上海、天津的学生上清华相对容易。
取各省2006到2013这八年间“清华率”的中位数,我们可以画出这样的地图:

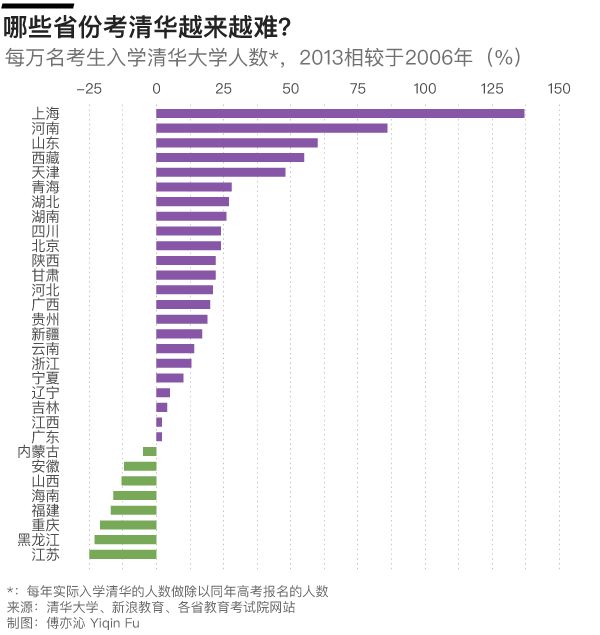
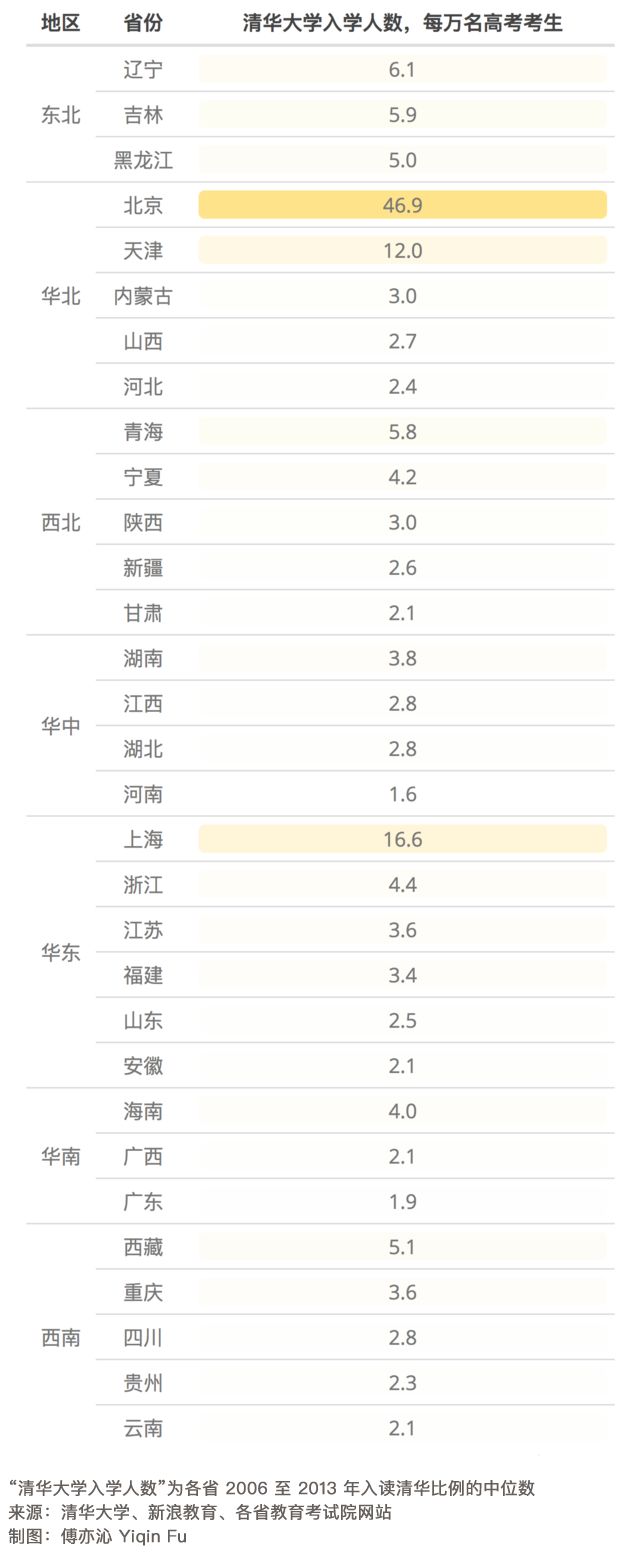
上清华最容易的北京,每万名考生有47人就读清华;而最难的河南,每万名考生仅有不到2人。数据虽然只到五年前,但不妨碍我们了解招生政策的地域不平等。
地域不平等问题为什么亟待解决
可能有人会问,地方财政也对高校发展做出了巨大贡献,高校多招一些本地学生,难道不是理所应当吗?
北京大学法学院的张千帆教授在2012年在接受媒体采访时,很好地回答了这个问题:“北大清华……公认第一的地位很大程度上是行政部门赋予的。国家部门对北大、清华,985、211院校,部属院校的投入都是不一样的。”
中国现有“985院校”39所,“211院校”112所,教育部直属院校75所,都是举全国之力发展的大学。国家财政对它们的投入,在以下几个数据中可以体现。
仅对1998年开始的“985工程”这一项,中央财政就累计投入了554亿元人民币,是地方投入的1.6倍。
具体到清华大学,虽然在其公开的财政预算、决算中,目前看不到中央和地方财政拨款的比例或具体数额,但我们可以参考同为“985高校”的复旦大学。在复旦公布的2011年收入决算中,教育部和上海市拨款的比例为4:1。我们可以推测,像清华这样的超级大学,教育部拨款占其总收入的比例应该和复旦相当,甚至更高。
此外,教育部、财政部、发改委于2017年公布了新的“双一流”计划,重点支持42所“一流高校“的建设。清华大学也毫无悬念地名列其中。官方没有公布对各高校拨款的数额,但从清华大学公开的预算可以看出,其2017年的“一般公共预算拨款收入”达到50亿元人民币,相比2016年上升了67%。
可能还有人会问,既然国家重点支持几十、上百所院校,那么各省都有像清华这样的好学校——复旦大学多招上海考生、南京大学多招江苏考生、武汉大学多招湖北考生,不是很公平吗?
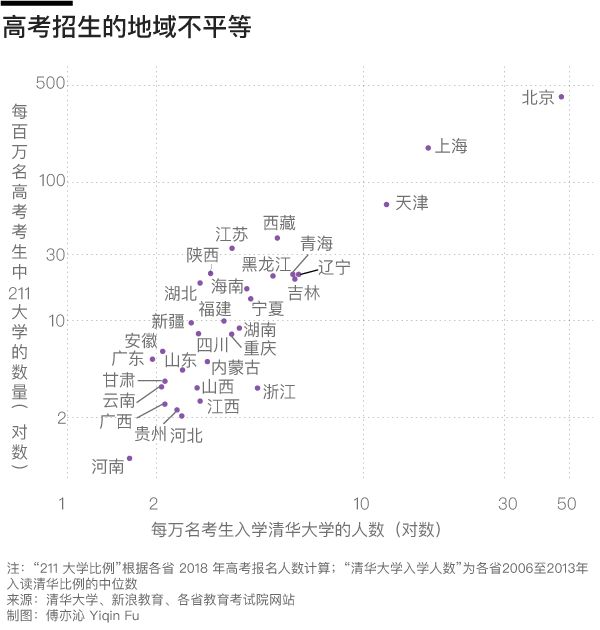
问题在于,不是每个省都有像清华、复旦、南大、武大这样的学校,不是每个省都有那么多“985”、“211”、“双一流”。我们把每万名考生中清华大学的入学人数作为横轴,每百万名考生中“211大学”的数量作为纵轴,从下图可以看出北京、上海、天津考生的幸运(上清华容易、本地好学校多),江苏考生的福气(上清华难,但本省好学校多),以及河南考生的压力(上清华难、本省好学校少)。
此外,也有人会认为,清华给广东这样的南方省份名额少,是不是因为广东的优秀学生都不愿意去北京上大学?
从数据来看,显然不是。广东媒体每年都会报道该省高考前几名学生的去向。查阅可知,每年几乎都是清华、北大瓜分了所有高分学生。例如,2014年,广东文科与理科的前10名共有18人去了清华、北大;2016年,文科前30名有26人去了北大,理科前20名一半去了清华、一半去了北大。清华、北大历年在广东的分数线都远高于其他学校。
此外,“考生意愿不够”这个说法,也不能解释为什么邻近北京的河南、河北省,“清华率”那么低。2006到2013年间,河南的“清华率”是北京的三十分之一,河北是二十分之一。
如何分配有限的教育资源
像清华这样优质的高等教育资源,短期来看一定是有限的,那么如何分配就成了棘手的问题。其实世界各国都没有所谓的完美分配方案,哪怕像英美这样教育资源发达的国家,顶尖学校的招生也是每年公众和媒体讨论的热点。
以英国大学来说,它们招生主要通过每年一次的全国统一高考。这样的选拔体系,好处是较为公平,所有学生都用一把尺衡量。但由此带来的问题是,欠发达地区和公立高中的学生很难进入名校。2016至2017学年,90%的英国高中生都就读于公立学校,但牛津、剑桥仅有一半左右的学生来自公立高中,该比例为英国所有大学中最低。
美国私立大学的录取标准则完全不同。它们综合考虑高中平时成绩、标准化考试成绩、课外活动、申请文书、面试等多个因素,由几十人组成的录取委员会自主审阅材料,没有公开或统一的打分标准。这样的综合考评,好处是可以照顾欠发达地区学生、少数族裔等弱势群体,但由于录取人数有限,所以照顾弱势群体就意味着要牺牲其他人群的利益。以哈佛大学为例,尽管其不承认歧视亚裔学生,但被录取的亚裔学生通常在成绩方面都远远好于其他族裔。目前已有民权组织就此起诉哈佛。另外,不透明的招生程序也更方便大学考虑学生本人能力以外的因素。例如,许多私立大学都公开表示会优先考虑校友及捐款人子女。哈佛大学2017年近30%的新生都有亲属在哈佛读过本科。
美国绝大多数公立大学招生也是“综合考评”,不看某次具体考试的分数。不过很多公立学校,例如德克萨斯州的公立大学系统,自动录取州内学校平时成绩优秀的学生。美国学生比中国学生幸运的地方在于,美国各地都有优秀的公立大学——西部有加州大学,中部有密歇根大学、威斯康星大学,东部有弗吉尼亚大学,南部有德州大学。不过由于公立大学主要依赖地方拨款,所以近年来多数都预算紧张,录取时开始偏向需要缴纳更高学费的州外学生。以加州大学为例,伯克利和洛杉矶分校近几年的州外录取率都高于州内录取率,戴维斯分校的州外录取率更是州内的两倍。加州民众抗议多年后,加州大学系统决定从2018年开始把州外学生比例控制在18%以下。
可以看出,在优质教育资源有限的情况下应该如何分配,是每个国家、不同教育体系都面临的问题。这其中不仅有大学、地方、中央之间的博弈,也有政策制定者对于绝对公平和弱势群体保护这两种考量的权衡。中国高校招生的地域不平等只是众多分配难题中的一个。在不能一夜间找到完美分配方案的情况下,主动与公众沟通名额制定的考虑依据,可能是迈向公平的第一步。

作者:傅亦沁
出处:raincent
链接:http://www.raincent.com/content-10-11690-1.html
推荐阅读:
利用Python预测NBA比赛结果
逃课、辍学,他自学编程,创办的公司卖了480亿
我们整理了20个Python项目,送给正在求职的你
运维 从月薪 5K 和 50K ,中间都经历了什么?

这篇关于数据解读:中国高校招生如何不平等?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







