本文主要是介绍H2O平台架构概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1.API 与 REST API
- 2.框架总体概述
- 3.Memory Management(存储管理)
- 4.CPU Management(CPU管理)
1.API 与 REST API
这里可以参考这篇文章什么是REST API
这里我做一个简单的总结:
- API:Application Programming Interface(应用程序接口)。在我们进行编程的时候我们经常会用到一些其他开发人员已经编写好的类库,也会有对应的“API文档”。从这个层面上来讲,API就是我们调用他们类库时使用的接口。
- 从本地API到网络API:一些厂商可能带有目的性地将类库开发为经过网络进行请求的API,举一个可能不那么贴切的例子:我们在使用Linux 的时候通常会使用yum或者其他的程序进行文件的下载或者应用的安装,一个如此庞大的“资源库”是不可能保存在本地的,因此我们的请求是通过网络进行发送并有对应的服务器返回我们所需要的资源的,这就是一个网络API的案例。可以认为REST是一种网络API的“格式”。
- REST API:Representational State Transfer(表示层状态转移)是一个用以描述HTTP API的标准方法。所有依据此方法定义的HTTP API都可以称之为REST API。构建REST API的好处在于:规范了人们进行网络API调用的方式。
注意:REST API并不一样是调用其他服务器的服务,同样可以是本机应用提供的服务。“网络”的概念很宽泛,谨记!!
2.框架总体概述
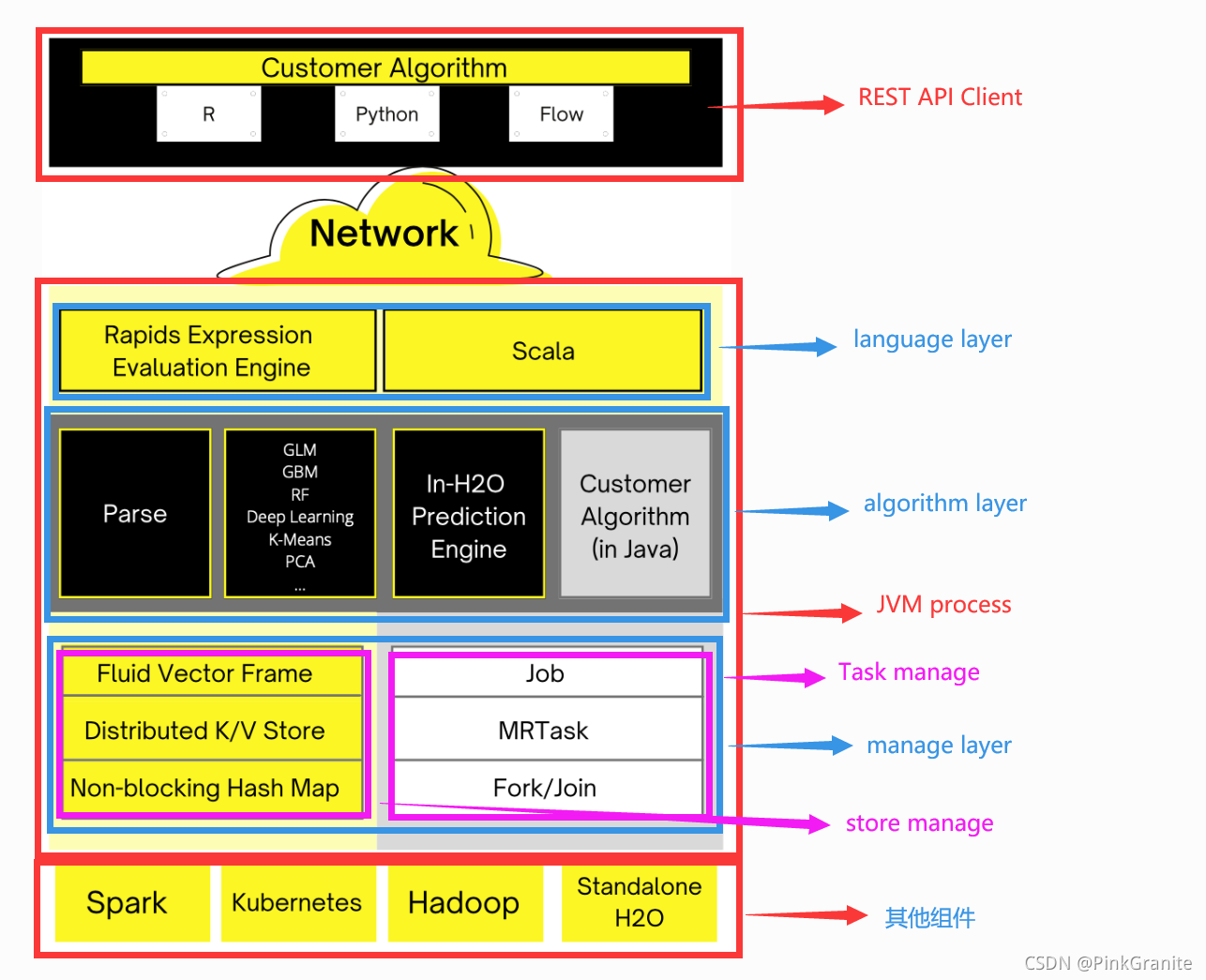
- REST API Client: REST API客户端层,即可以与H2O进行交互和调用的客户实体。包括WebUI Flow,Python,R语言程序等。
- JVM层: 是H2O的执行主体。
- language layer: 即语言支持层。该层包括一个R语言引擎以及一个Scale语言的支持模块。“The R evaluation layer is a slave to the R REST client front-end.”根据官方文档的表述,该组件服务于R语言 REST API Client;Scale层支持直接在H2O中编写简单的Scale脚本并执行。
- algorithm layer: 即H2O内置的算法层。其中包括Parse,用于数据解析;以及一系列的内置机器学习算法。
- manager layer: 调度与管理层。
- Task manager: 即CPU管理层。
- Storage(Memory)manager: 用于内存管理。
- 其他组件: 可以与H2O配合执行。
3.Memory Management(存储管理)
- Fluid Vector Frame:
"Frame"是H2O对用户可见的最基本的存储单元。“Fluid Vector(流动向量)”是一个概述性词,H2O能够轻易地对Frame进行增删改操作,相对于一些更为严格存储系统(如HDFS)是“Fluid”。Frame->Vector->Chunk->Element。
- Distributed K/V store
以K-V键值对方式实现的,原子性的,分布式的基于内存的存储模式。“Atomic and distributed in-memory storage spread across the cluster.”
- Non-blocking Hash Map
是实现Distributed K/V store的具体方式
4.CPU Management(CPU管理)
- Job
Job是具有进度条的,可以通过WebUI进行管理大型工作。例如:机器学习模型构建。
- MRTask
基于MapReduced的任务实现。注意,这里的MapReduce并不是Hadoop中的MapReduce。
- Fork/Join
任务执行框架。可以简单地理解为:Fork阶段进行任务分配,各节点分别执行对应任务;Join阶段收束工作结束的节点。
这篇关于H2O平台架构概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







