本文主要是介绍【66页PPT】部委、集团级数据治理项目经验分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
昨天受邀参加机工社和DAMA中国主办的DAMA中国数据大讲堂系列活动,分享内容为《部委级数据治理项目建设经验分享》。
很多人错过了,想要听回放,也有很多人想要PPT。我跟DAMA中国沟通了一下,决定全部放出来,供各位参考。实力有限,如有谬误,还请多多海涵![]() 。
。
文末有完整版PPT下载,以及视频版连接,不想看文字可以直接拖到最底下。
本文多图,请在wifi环境查阅。土豪随意。点击阅读原文,即可观看直播回放。
前言


绝大多数互联网公司没时间建模、治理,直接拖宽表。业务变更频繁、建模缺位、指标爆炸,是导致互联网大数据环境中数据质量的低下的根本原因。
而在部委、集团中,时间相对充裕一些,标准更规范一些,但是同样面临部委和省级之间、各系统之间数据交换、对齐的问题。
因此,在不同的环境中,数据治理的重点和偏向都是完全不一样的。

今天分享的内容从实战出发,到落地结束。数据治理最难的不是系统建设,而是落地困难。所以今天先跟大家分享一下部委、集团类数据治理遇到的困境,以及各种问题的具体解决方案,还有如何进行经验复制。
你以为的数据治理

提到数据治理,第一反应就是数据部门一定要定标准、做执行、强监督啊,搞一个PDCA戴明环,一点一点慢慢的做起来。
然后呢?给下属单位、子公司和其他部门下文件、搞培训,做排名,轰轰烈烈做起来,各种办法都得上啊。
这样行么?这样有效果。但是肯定会非常非常的困难。因为很多事情跟你想象的不一样。

比如,你以为在部委、集团里办事是不是开个会,发个文件就好了?嘿嘿,那你简直太天真了。

实际上,各部委、集团的甲方,在执行项目的时候,电话根本放不下来,下面的各个厅局级的疯狂打电话过来各种确认问题。
乙方呢?那就更惨了!即便是做了万全之策,也会有无数的未知问题等着你。所以乙方基本都是处于疯狂加班的状态。

你以为部委、集团就是发发标准,数据质量自然就提高了?是,数据质量的确要制定好标准,但是你听说过“形同虚设”吗?
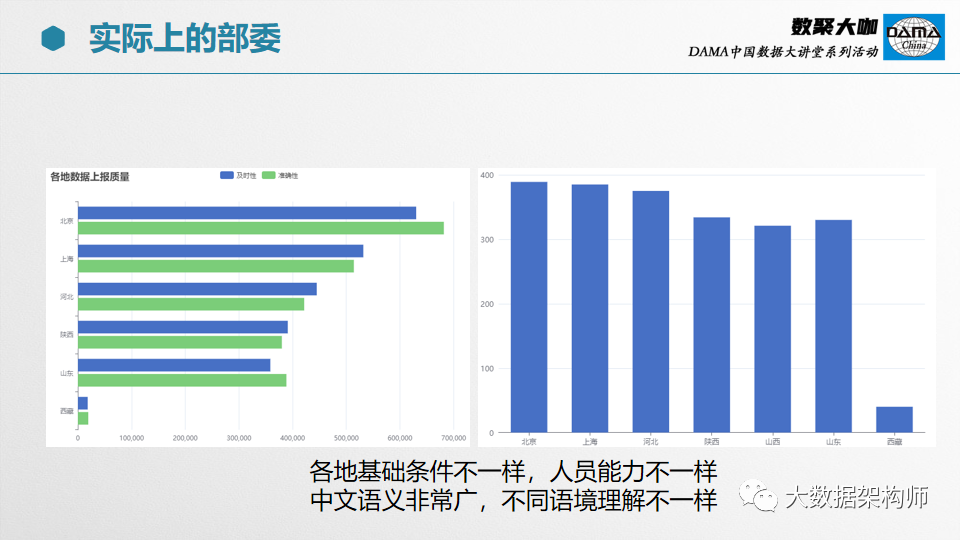
即便是通过行政命令强压下去,但是各地的基础条件不一,人员素质不一,经济实力不一,系统建设的好坏也就不一样。
还有,中文语义非常广,不同语境理解不一样,非常容易产生很多歧义。所以很多时候公务员真的都是在抠字眼,因为要力求精准。
经常是你想要他们填A,结果有很多人填A'、B、C。

你是不是以为在部委、集团里做事情,都是一声令下,然后就有山呼海啸,应者无数,事情推进的非常顺利?

实际上,基层工作人员手上的事情都非常非常的多,根本没办法及时响应,通常都是拖到最后一刻才交作业,晚交也是非常正常的事情。
如果你抱着以上的认知去做项目,拿着部委、集团的命令当尚方宝剑的话,我不敢确定你是否能成功,但是你肯定会吃尽苦头,撞一头的包。
核心原因

一般来说,你可能会遇到这三种情况:
耽误工夫,不想治!
数据治理太难了,不会治!
治好了没政绩,没啥用!

为什么会这样呢?我们需要追寻到问题的底层逻辑。
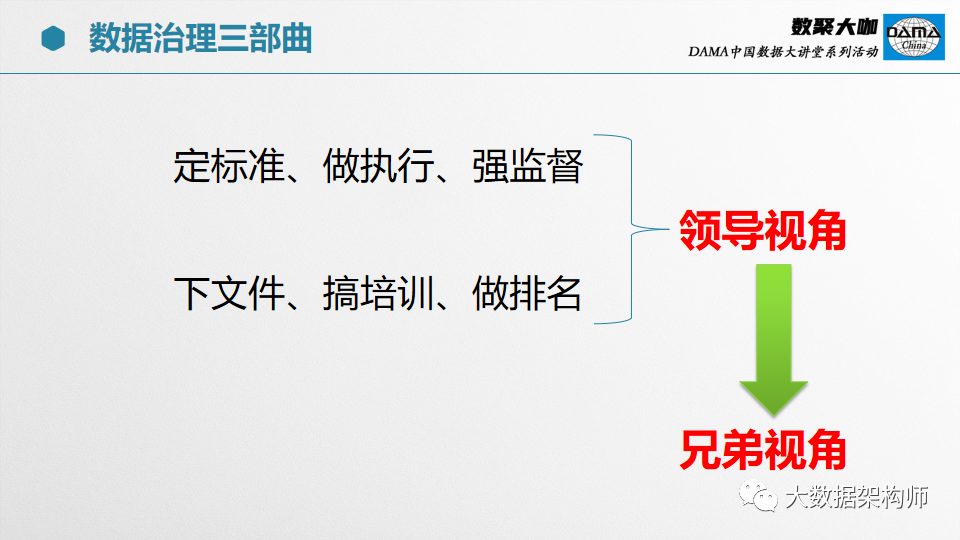
我们回到最开始的策略,先定标准、做执行、强监督,向下则是下文件、搞培训、做排名。
这是典型的领导视角,是带着一些强权的意思在下达任务。大家都是打工人,何必为难打工人?再说了,打工人手上的活也很多啊,谁愿意多一点活?
领导视角推动事情,最喜欢用的就是强权,但是最坏事的也是强权,很容易引起反感,没人听你的。
他们没有任何动力去做这种事情啊!这就像小时候的我,总是被爸爸妈妈逼着学习。晚上回家还站在我后面看着我写作业,谁心里舒服啊?
上面说到的“不想治、不会治、没啥用”只是三个典型而已,信不信给你找出100个理由?你想想小时候为了逃避写作业,你编过多少理由?
所以我们需要转换一个视角去办事,强权是靠不住的。根据我的经验,转换成兄弟视角是最合适的。
峰会内容

对付不想治,简单!病根找到了,那就让他自己想治就好了。
态度一定要明确:兄弟不是给你派活的!兄弟是给你助攻的!
再给你三个小妙招:举例子、挂欲望、给希望。

挂欲望的时候,一定要注意,这个欲望不是人性阴暗面的欲望,而是激发他的正能量。所以奖励钱是不好的,因为你在诱惑他。
而是从他的工作入手,告诉他能实现价值,比如节省时间。
我们最终的目标是转变他们的观念,将“要我治”变成“我要治”。化他们的被动成为主动。

对于数据治理太难的问题,我们必须帮助他们。因为很可能他们根本没有那个能力去做这些事情。
更何况,你要是放开让他们自己干,一人一个理解,全乱套了,最后没办法收场了。

所以我们得根据各种实际问题,帮助兄弟提供针对性的解决方案,最重要的是降低执行的难度,最好一键搞定。

对于感觉没啥用的观点,好处必须要落到实处。

怎么落?一定要设计好动力系统,让大家看到实实在在的好处,才能有动力一起推动这件事情。
该给的荣誉要给到位,标杆树起来,比学赶帮超,带动一大批。
虽然是数据治理,但是应用也得规划到位,否则业务部门无感,数据部门也觉得没啥用。
还得给下面干活的同学提供相应的工作管理和向上汇报的素材,好歹也能发一个内部的小通知不是么?
方法论复用
我这个方法论可不仅仅是在部委能用,在集团、普通公司都能用的。比如,在微信群里,就有想推动数据治理的朋友提一个问题:怎么反驳IT同时不恰当的言辞呢?
群里也有人给了非常专业的回答,这么说肯定是有理有据的。

不过在这里,也可以用我之前的那个套路套一下,也挺管用的。
比如,原来是要反驳,这明显是对立视角啊,想找他的问题很简单,随便能找一堆啊。但是对立就意味着失去了一个朋友。数据治理这么难,我们应该尽可能的团结一切可以团结的力量。他说错了就让他错呗。我们只要他合作就行了。
所以,转变一下视角,从对立变成合作。
一样,把“要我做”变成“我要做”:举例子、挂欲望、给希望。谁家的数据治理做的好,他们的IT部门都不用操心数据部门的事。SAP属于业务系统,数据分析数据分析系统,我们以前有问题都找你人工解决,以后我们自己解决。
提供全套解决方案,降低执行难度。数据治理很专业,有专门的系统,也有方法,我这里还有高手,不会给你添麻烦。
规划先行,设计动力系统。做好了,你也省心啊。每次有进展的时候,向领导汇报,都感谢一下他。
你看,这样做,阻力变成助力,推进起来是不是就容易多了?
数据治理目标

接下来,给大家分享一下比较枯燥的数据治理建设方法论。

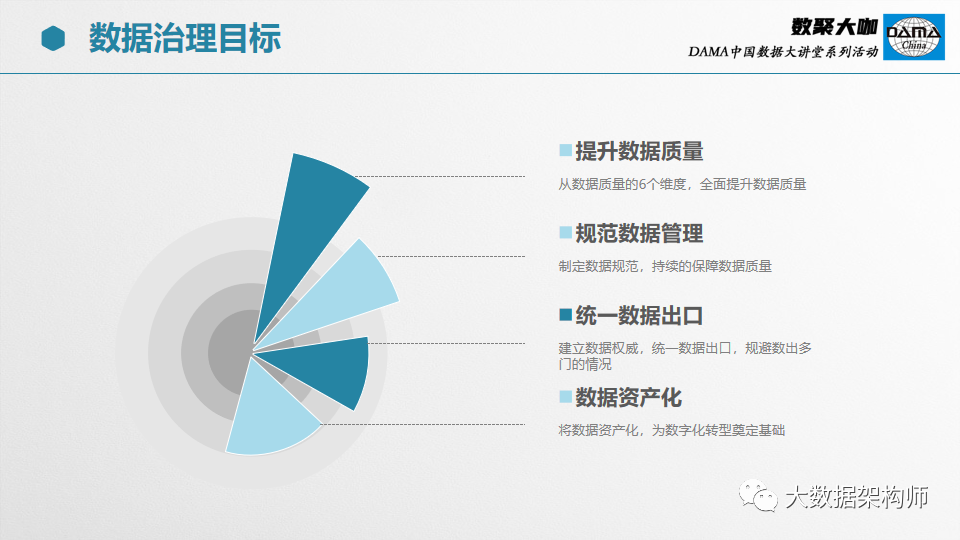
不同场景、不同项目对数据治理的需求是不一样的。个人认为核心的就这几个:
1、提升数据质量;
2、规范数据管理;
3、统一数据出口;
4、数据资产化。
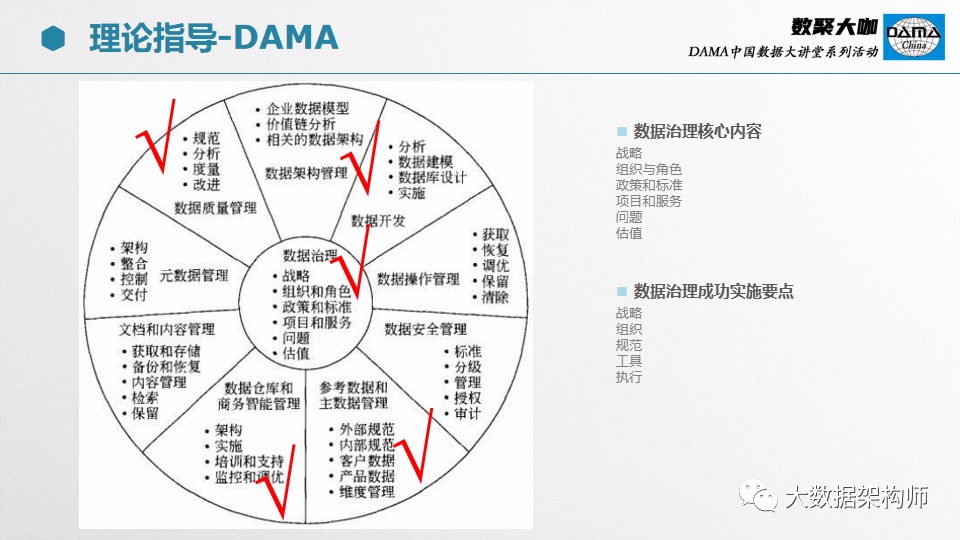
理论指导采用DAMA,这是DAMA的车轮图,我们在具体落地的时候,一般都会从中进行裁剪,选择合适的内容进一步搞建设。
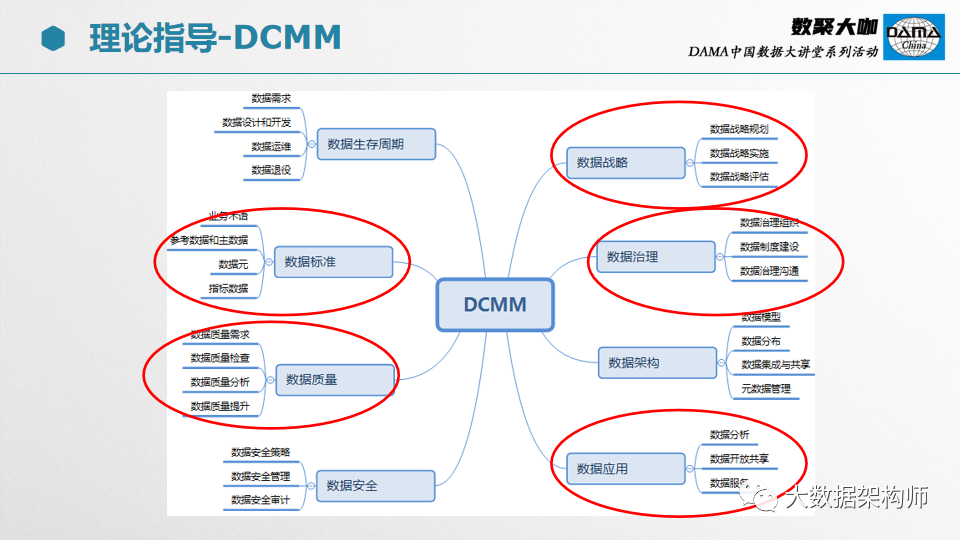
另外一个是DCMM,也是一体两面,同样需要裁剪。

我们需要进行常规的现状问题分析,找到问题背后的根本原因,然后再制定相应的策略,从根上解决。
比如每个人都能定义指标,数据部门沦为提数工具。这个现象的根本原因是缺乏归口管理,也就是数据部门没啥权利。这是组织问题,需要从组织层面解决,制定指标定义流程,确定数据权威。

部委、集团层遇到的问题就更多了。信息化做的早,不一定是好事。
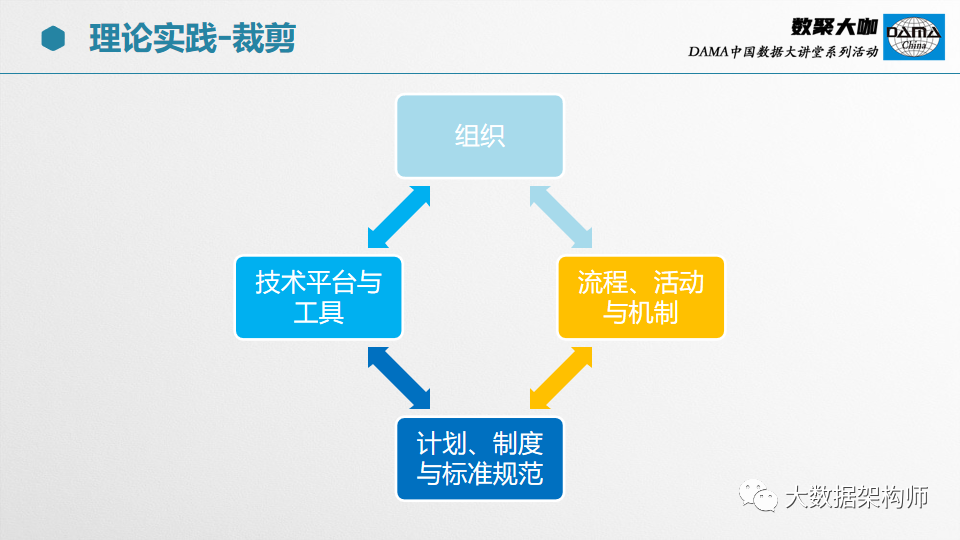
一般来说,裁剪完之后,就会剩下几个重点要做的事情。
峰会内容


组织一定要先行!数据治理犹如河道清理,不仅仅是清理工的工作。上游、河道两旁的垃圾、废水排放不制止,把河道清理工累死也无用。
所以数据治理应该向政府治理城市河道学习,要联合各个部门,做宣讲,改变大家随意排放的观点。做污水管道,引导河道两边的社区、企业合理排放。最后加上一些河道清理,这样大家一起努力才能有效。
组织先行的第一步是设立数据治理委员会,主要目的是把老板拉进来,把业务部门负责人拉进来,一起进行治理。这一步时间最小,但是重要性最强。
其次是制定各种管理规范,让大家有法可依。
然后才是建立数据治理团队,不仅仅是数据团队要加入,其他团队也要加入。
最后才是责任到人,落实到位。

这是组织架构简要示意。

部委级的组织架构简要示意。

这是各种政策的简单示意。包括数据安全、质量管理、各种校验方案、管理办法等。
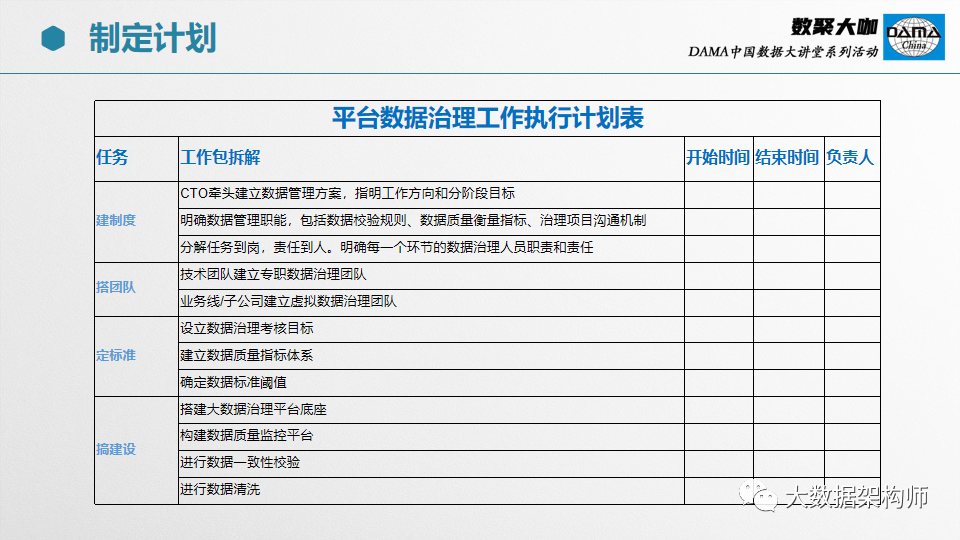
这是各种计划示意,具体的工作肯定不止这么少。但是逻辑是一样的。
管理方案

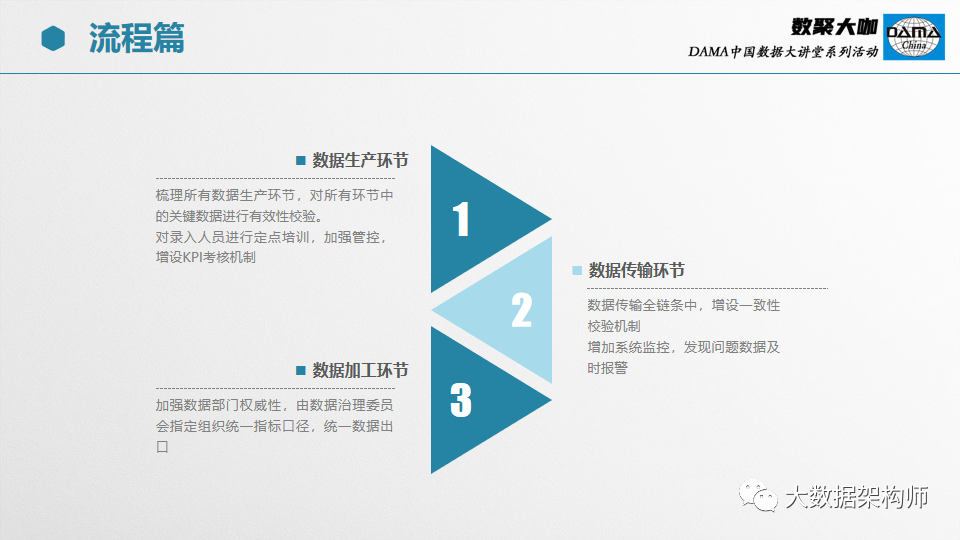
数据治理应该覆盖所有环节。但是项目建设范围有限,不建议超出项目建设范围。
一般主要有三个环节:生产、传输、加工。再往后是使用环节,那边主要是发现问题的地方,而且往往在系统之外,所以不太好管理。
这三个环节管好基本就差不多了。
在生产环节,我们需要跟业务部门多多沟通,有些时候需要看看数据,反应的都是那些环节出问题了。也许是人的问题,也许是培训不到位,也许是系统不友好。我们根据实际情况进行调整,不断优化即可。

在数据清洗的过程中,重要是成本和质量之间的平衡。这时候我们应该让业务参与进来,尽量做到用最小的成本覆盖最多的数据质量监控。
对于已知的异常数据,我们可以根据数据的重要性和其他特征,做相应的处理,能填补的就填补,不能填补的就原路返回,改好了再重新发过来。

在数据治理的环节,一般要分成存量和增量场景。存量场景基本上一次性操作,人工突击搞一下就行了。增量场景则需要进行全面监控,而且还要持续治理,人工处理效率太低,成本较高,建议用系统承担。特殊情况再由人工介入。

数据治理是一个综合、复杂、困难的工作,需要多方协调。建议由信息中心、IT部门牵头,定标准、做规范,拉上业务部门和厂商一起进行。期间一定要做好宣贯、协调工作。
招术尽出,最后还是要加一根大棒。因为没有考核就没有结果。我遇到过什么事情都做了,但是结果就是不好的情况。
你想想身边是不是有这种“天天加班,但就是干不好活”的人?
治理平台建设

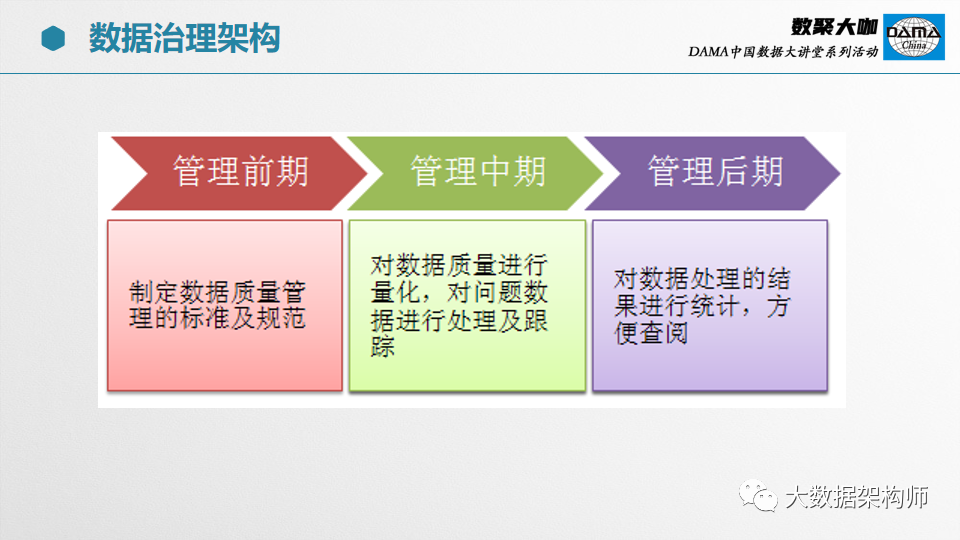

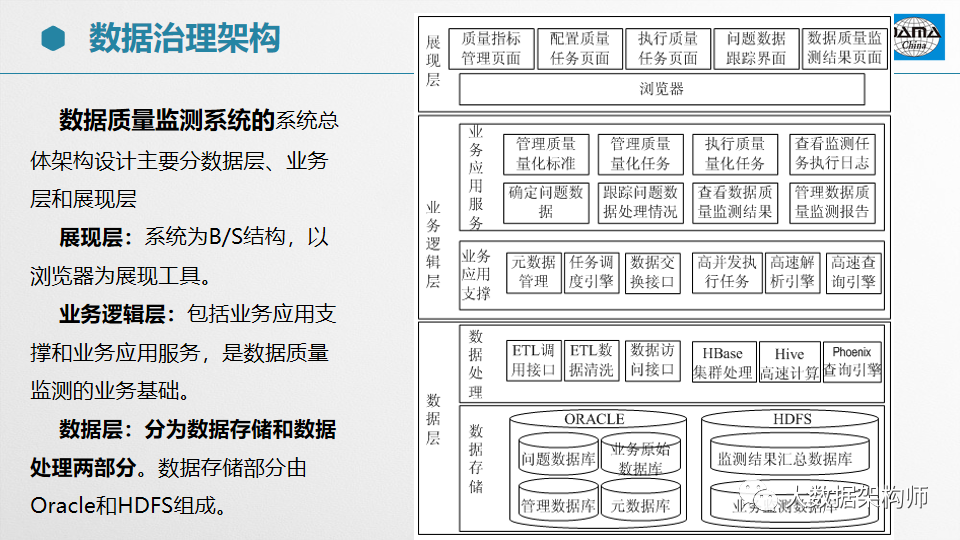
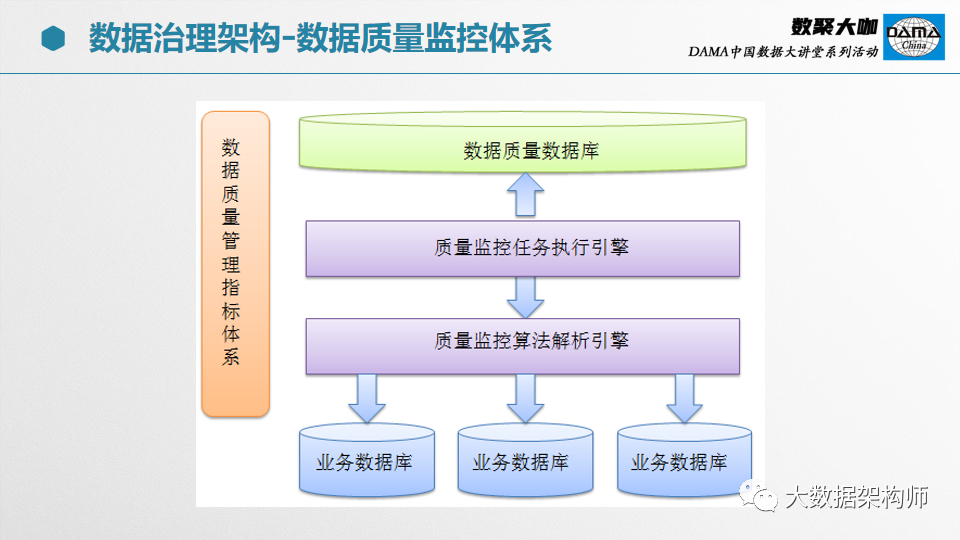

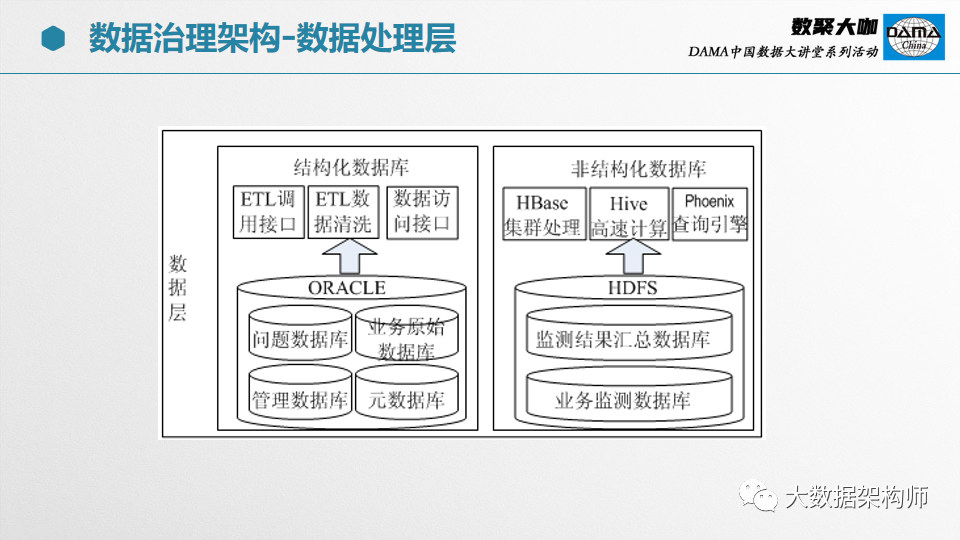
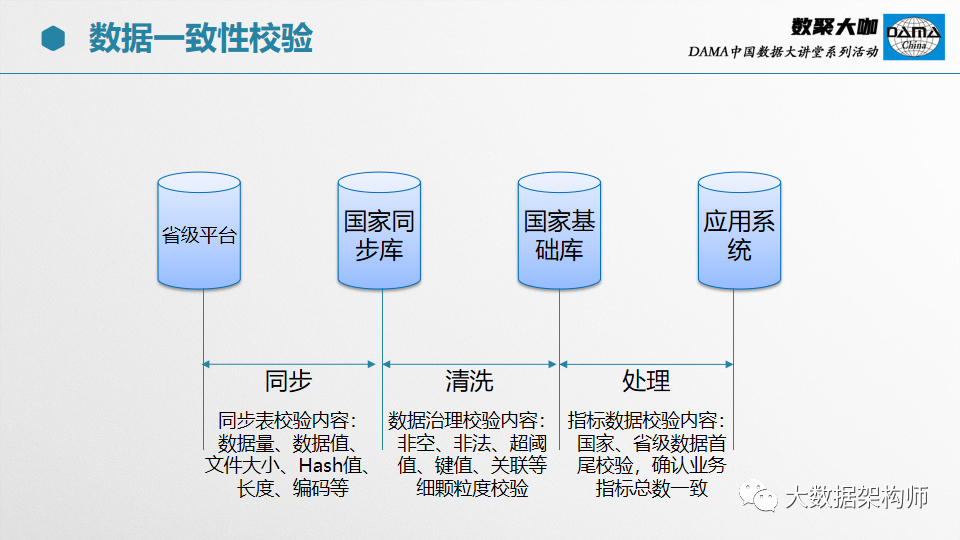
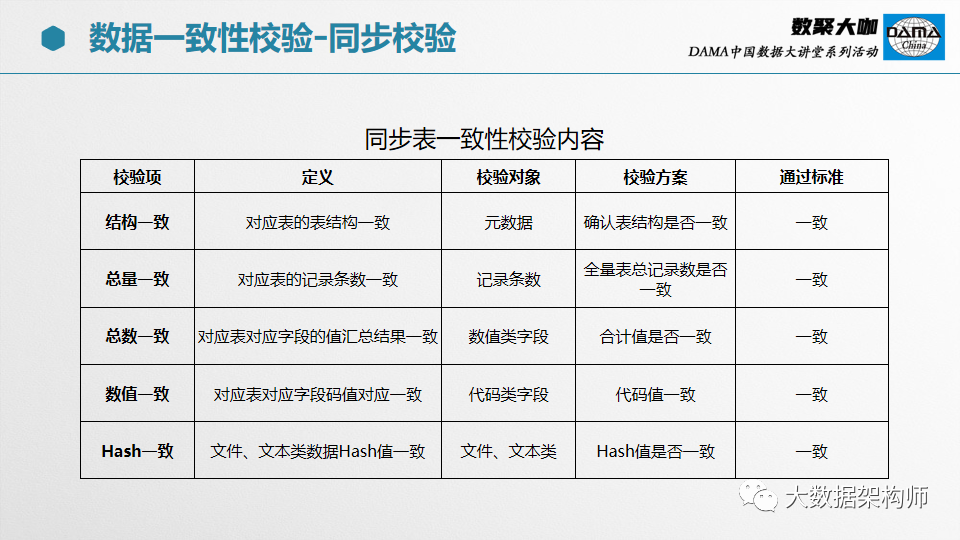
在不同的阶段,数据一致性校验的内容是不一样的。以部委为例,先要从省级平台同步数据到国家同步库,然后再入到基础库,最后到应用系统。期间会经过同步、清洗、处理三个阶段。
同步的时候,校验的目标是数据源和接收结果是否一致;
清洗的时候,校验的目标是数据是否干净;
处理的时候,校验的目标是数据是否准确。

系统截图:略
组织建设

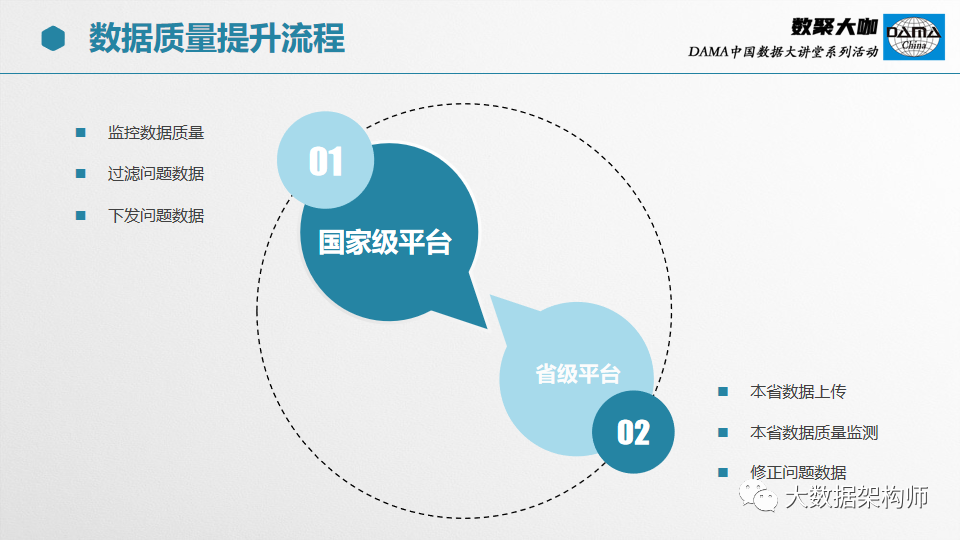
在数据治理环节上,要做到闭环。在组织建设流程上,也要形成闭环,这样才能把每一件事情做到位,每一条数据治理干净。




最后帮DAMA做一个广告:我是DAMA中国会员,DMBOK是国际数据管理的标准知识体系。
现在DAMA2.0已经发布,感兴趣可以直接点击链接购买。
结语
完整版PPT下载:公众号“大数据架构师”后台回复“0415”即可下载。
感谢阅读,本次分享的内容就结束了。
欢迎大家加我微信好友,尽个点赞之交,一起进化吧!

推荐阅读:
CRM、DMP、CDP到底都是些啥啊?
如何打造数据治理闭环?以金融行业为例
快⼿数据质量保障体系及在直播场景的实践
数据资产化的前提-浅谈数据治理体系的建设
主数据又是啥东东?应该怎么建?
什么是数据、元数据、主数据和参考数据?
近期数据治理案例合集
更多精彩:
这篇关于【66页PPT】部委、集团级数据治理项目经验分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






