本文主要是介绍根本:详解receiver based Dstream,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用注意事项
1. receiver 会像正常task一样,由driver调度到executor,并占用一个cpu,与正常task不同,receiver是常驻线程
2. receiver个数 KafkaUtils.createStream调用次数决定,调用一次产生一个receiver
3. al topicMap = Map("page_visits" -> 1) map的value对应的数值实际上是消费的线程个数。
前情:基于reciver kafka java客户端消费者高阶API
4. receiver 默认 200ms 生成一个block,spark.streaming.blockInterval默认值是200ms。最小建议是50ms,小于该值,性能不好,比如task加载比重就比较大了。每秒钟大于50个任务,那么将任务加载分发执行就会成为一种负担。
根据数据量来调整block的生成周期。
5. receiver接收的block会放入blockmananger,每个executor都会有一个blockmanager实例,由于数据的本地性,那么存在recever的executor会被调度执行更多的task,就会导致某些executor比较空闲。
a). 增加executor
b). repartition增加分区
c). 调整数据本地性 spark.locality.wait 假如任务都是3s以内执行结束,就会导致越来越多的任务调度到数据存在的executor上执行,最终导致executor执行的任务失衡。
6. kafka 082 高阶消费者api,有分组的概念。当然就会产生一个问题,消费者组内的线程数,和kafka分区数的对应关系。
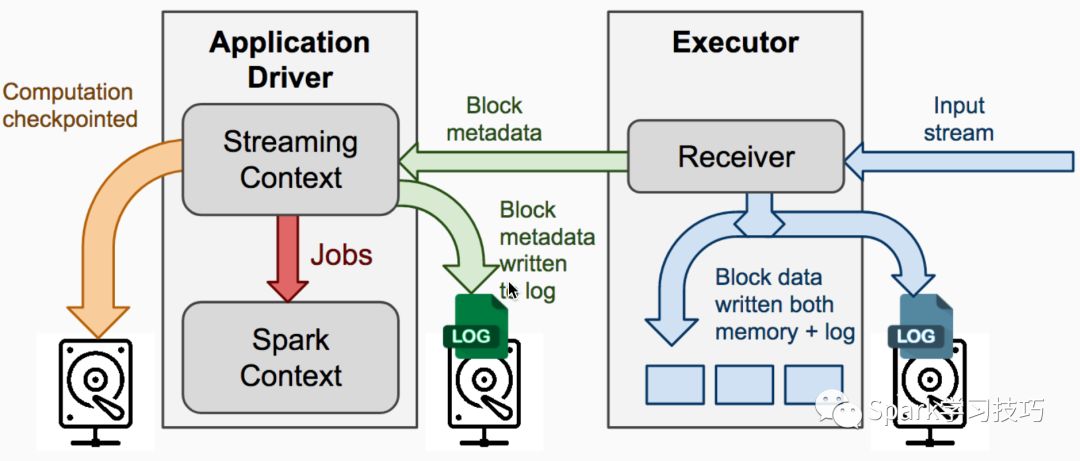
7. checkpoint 目的是从driver故障恢复或者恢复upstatebykey等状态
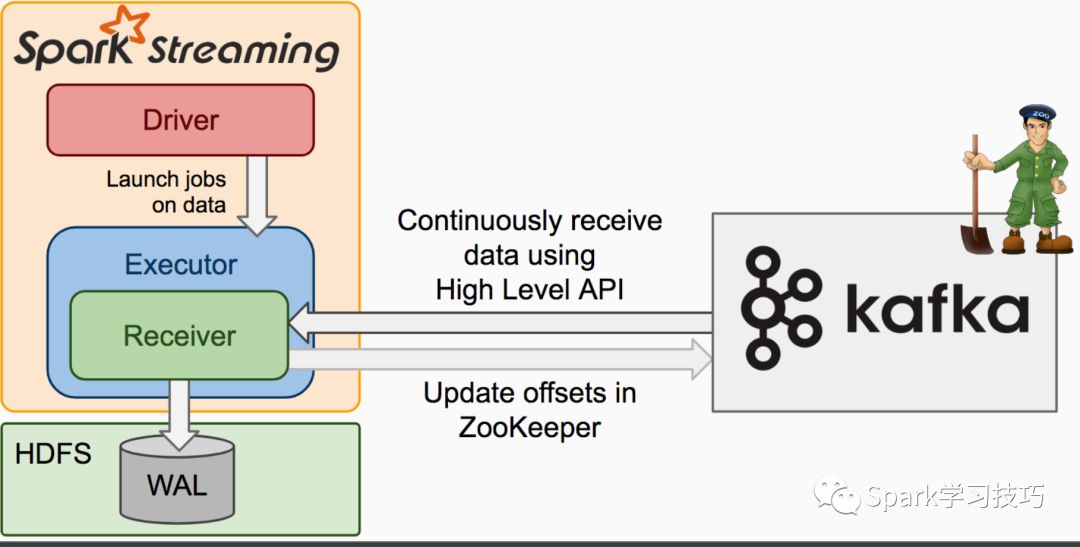
8. wal,预写日志,为了故障恢复,实现了最少一次消费。一是没必要多副本,尤其是基于hdfs的存储。然后为了效率,可以关闭wal。使能wal只需要将spark.streaming.receiver.writeAheadLog.enable配置为true,默认值是false
9 限制消费者最大速率
1. spark.streaming.backpressure.enabled
默认是false,设置为true,就开启了背压机制。
2. spark.streaming.backpressure.initialRate
默认没设置,初始速率。第一次启动的时候每个receiver接受数据的最大值。
3. spark.streaming.receiver.maxRate
默认值没设置。每个接收器将接收数据的最大速率(每秒记录数)。
实际上,每个流每秒最多将消费此数量的记录。 将此配置设置为0或负数将不会对速率进行限制。
10。 spark.streaming.stopGracefullyOnShutdown
on yarn 模式kill的时候是立即终止程序的,无效。
11. 在产生job的时候会将当前job有效范围的所有block组装成一个blockrdd,一个block对应一个分区。
图解
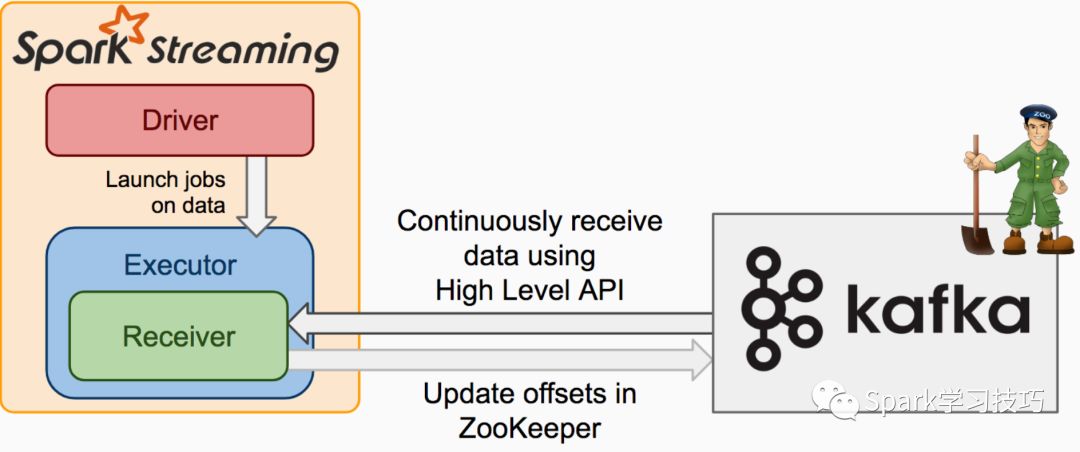
未加入wal的基于recevier的dstream
加入wal的Dstream
存checkpoint和wal的过程
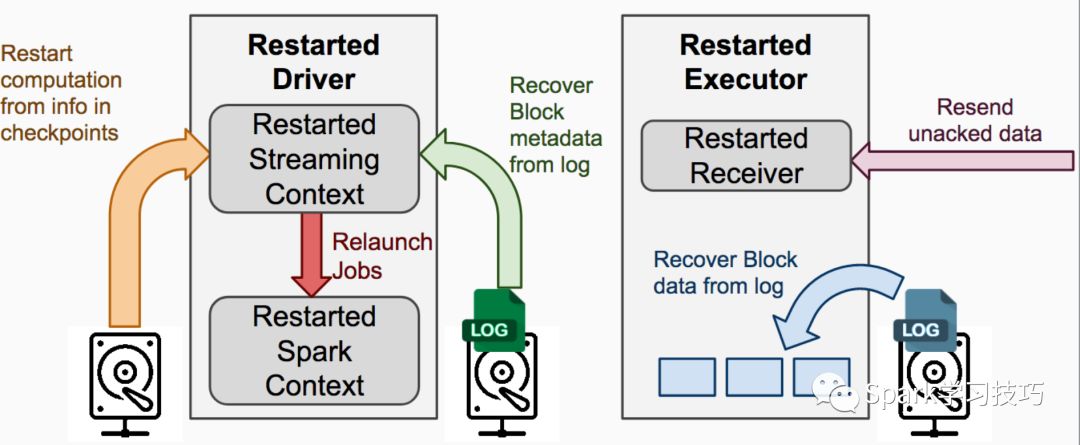
故障恢复图解
视频
推荐阅读:
不可不知的spark shuffle
必读|spark的重分区及排序
flink超越Spark的Checkpoint机制
更多视频,加入浪尖知识星球,一起学习进步。
这篇关于根本:详解receiver based Dstream的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






