本文主要是介绍是时候展示一波花里胡哨了——以图搜图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前段时间分享一个小视频,今天来详细讲解一波如何实现以图搜图,这篇写了好几天,自身能力有限可能没办法写的非常完美,也没有办法把所有点都讲的非常的仔细,但是我都会附上详细的链接,大家有什么不懂的都可以去查一哈,我觉得这个项目还是挺有趣的,最后我还附上了一个视频操作,第一次录视频意外多多,不足之处请大家见谅,如果尝试过后觉得不错的可以帮忙点一波“在看”或者分享朋友圈和群,小编会万分感谢的!!!
一、什么是以图搜图
广义上,图像搜索的分类可以分为两种,
(1)基于上下文本的图片搜索
例如:百度,在搜索框中输入“搜索文字”,点击“图片搜索”,即可获得图片搜索结果;
(2)基于图片内容的搜索
基于图片中特征进行搜索
详细内容可以查看:
《当SIFT邂逅CNN:图像检索任务跨越十年的探索历程》https://www.jianshu.com/p/80159860d4e0
图像搜索在现在应用的非常普遍,是一个非常有趣和实用的工具。相对于关键字搜索,以图搜图的方式更加的方便,特别对于特征难以用文字描述的,这个时候图像搜索就能展示出它的强大了。
当然还有很多应用场景:
你需要的图片有水印,想要找到无水印的版本。
二、常见的以图搜图的网站
百度识图:https://www.baidu.com/
拍立淘:http://www.pailitao.com/
360图片:http://image.so.com/
更多的可以查考:https://www.runningcheese.com/cbir
例如百度的以图搜图步骤如下:
(1)打开百度(www.baidu.com)

(2)基于文本的图片搜索:
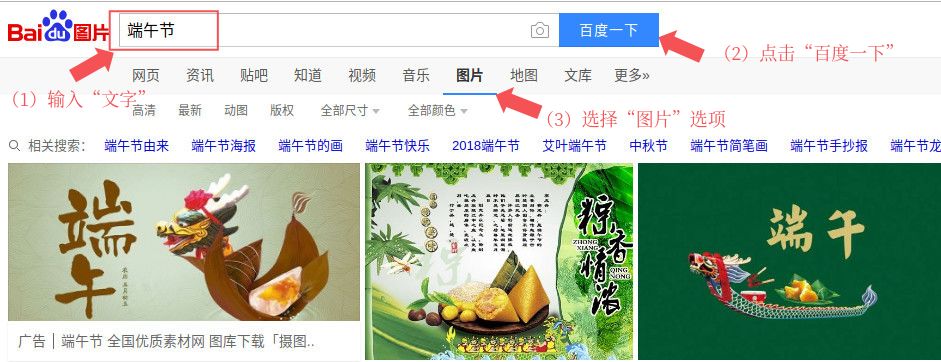
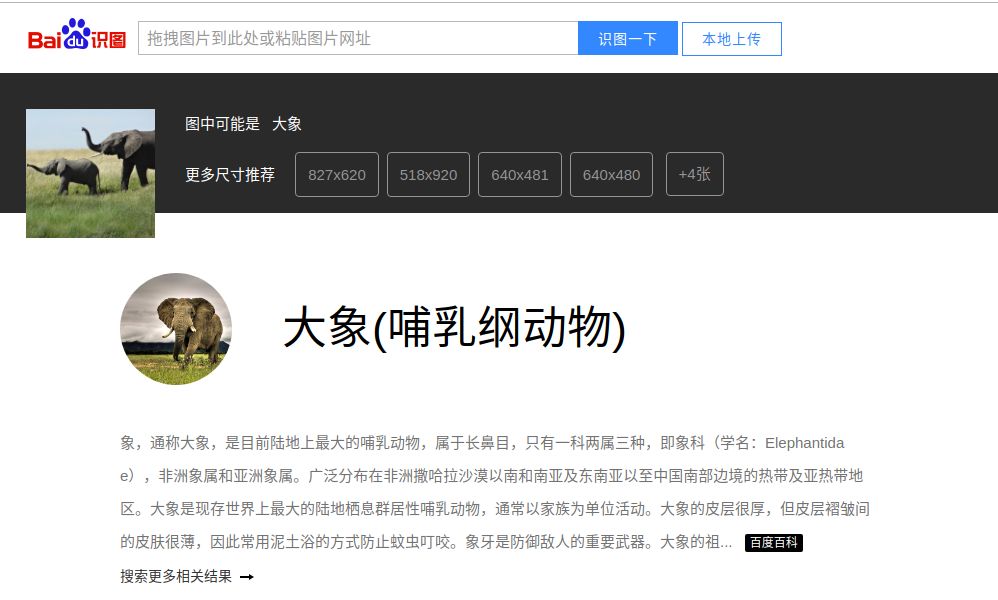
(3)基于图片内容的图片搜索:
1、点击“相机”图标

2、拖拽图片

3、自动显示结果
三、基于内容的图像搜索原理
这里以淘宝的产品拍立淘为例,
拍立淘的原理:
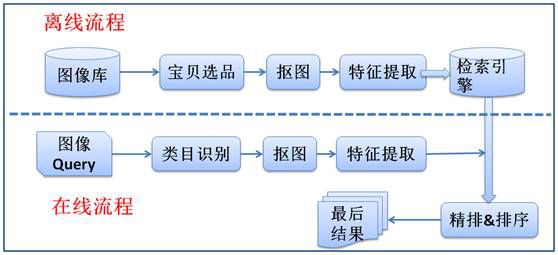
参考:https://www.sohu.com/a/164506831_468650
实际上,拍立淘图像搜索的过程分为两步,
第一步:识别物品种类
第二部:相似度匹配
-------------------------------------------
(1)识别物品种类(目标检测):当你拿起手机拍照的时候,手机淘宝会对图片中的所有物品进行识别,然后提示让你选择你所需要的找的相似物品类别是什么,这个过程实际上就是一个目标检测(如下图所示);
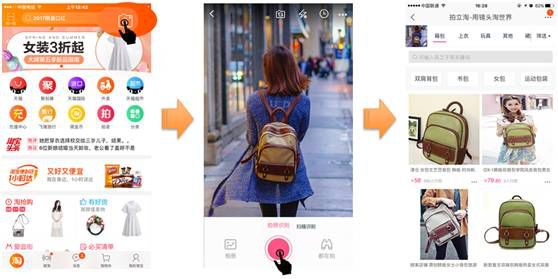
对于上面的图中,含有衣服以及书包,此时软件会让你根据需求进行选择相应的类别,在对应类别的库中搜索相似的商品并输出结果;
(2)相似度匹配:第一步的目的找到对应的类别,而找到了对应的类别还不能满足我们的需求,比如找到了书包,但实际上书包的款式多种多样,还是无法满足我们的需求,对于上图中,如果我们用语言去描述这个书包,很难准确的描述并找到目标商品,这时就体现了以图搜图的价值了,通过对目标商品进行特征提取并在图片库中进行对比,找到最相似的结果并输出。
由于淘宝的应用场景复杂,种类繁多,而这里我们只想演示一下而已,所以做了一个简单的展示,截取重点的部分进行代码演示:
原理:
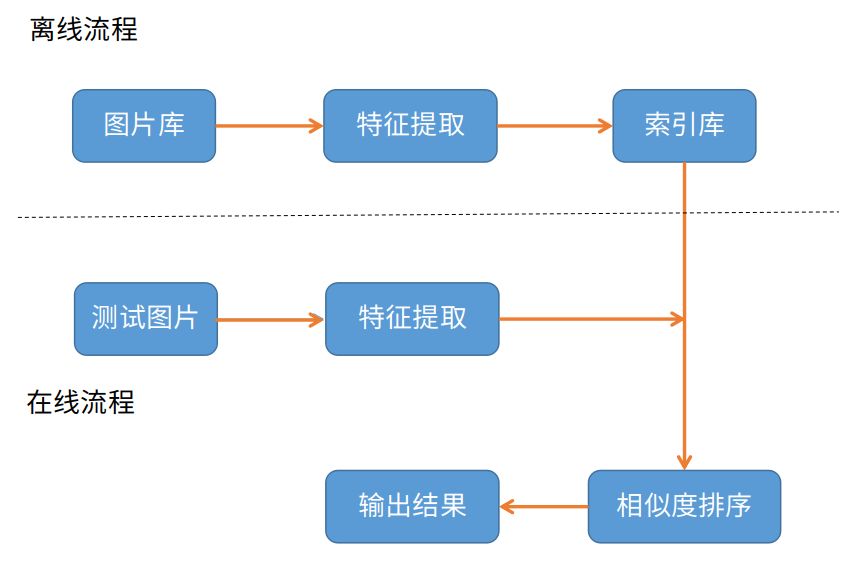
具体步骤:
(1)图片获取——通过关键字,爬取百度上面的图片
(2)对获取的图片提取特征,建立特征索引库
(3)对测试图片进行特征提取,并在索引库中比较,按相似度排序并输出
四、代码实现
所采用的工具python3.6,keras2.2.4
1)图片获取——通过关键字,爬取百度上面的图片
这里不详细说明爬取百度图片的原理和细节,因为我毕竟不是非常懂,重点讲解一下如何使用,具体的原理和代码可以查看下面的链接https://blog.csdn.net/qq_40774175/article/details/81273198
详细操作:
1、新建一个名字为name.txt的文档,并输入需要的关键字(支持多个关键自)
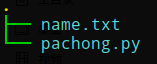
备注:我在name.txt中输入 dasima(换行) wuwukai
这里关键词不要用中文的,不然会对后面的操作会报错
2、运行代码pachong.py,输入每个对应关键字所需要下载的图片数量

此时程序会从网上爬取到图片并保存到对应的文件夹中(以关键词命名的文件夹),获取完毕后新建一个文件夹img,当做图片库的存储,并将爬取的图片都放进去;
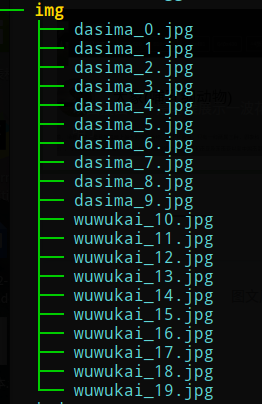
-----------------------获取图片完毕-----------------------
(2)对获取的图片提取特征,建立特征索引库
这里参考《python计算机视觉》的作者之一,袁勇github上面的代码
https://github.com/willard-yuan/flask-keras-cnn-image-retrieval
主要的代码为三个,其中index.py用于提取图片的特征和建立索引,query_online.py用于库内搜索
其基本原理是利用VGG16的预训练模型提取图片库的特征(extract_cnn_vgg16_keras.py),同时会将最终输出的特征向量进行归一化,并建立一个索引库
使用方法:
# 建立索引库
# python3 index.py -database <path-to-dataset> -index <name-for-output-index>index.py -database <path-to-dataset> -index <name-for-output-index>
# 对database文件夹内图片进行特征提取,建立索引文件featureCNN.h5
python3 index.py -database database -index featureCNN.h5(3)对测试图片进行特征提取,并在索引库中比较,按相似度排序并输出
这里采用的相似度实际上是利用测试图片的特征向量(VGG16提取)归一化后与索引库相乘,就是由于特征向量都进行了归一化,当测试图片的特征向量如果与索引库中的某一列的乘积等于1,即说明他们是完全相同的。
其他情况,结果由向量积计算结果可知其相似度的值。

# 在线测试
# python query_online.py -query <path-to-query-image> -index <path-to-index-flie> -result <path-to-images-for-retrieval>
# 使用database文件夹内001_accordion_image_0001.jpg作为测试图片,在database内以featureCNN.h5进行近似图片查找,并显示最近似的3张图片
python3 query_online.py -query database/001_accordion_image_0001.jpg -index featureCNN.h5 -result database注意:这里有个地方可能会报错,当然作者也给出了解决方案

这里,我斗胆进行了一点点的修改,
(1)增加了一个异常处理操作,主要是为了方便,即使手误输错也能继续运行,这个在之前的文章中有讲解过;
(2)作者最终显示的结果只能一张一张的展示,没有对比图,因此我稍微修改了一下,让可视化的效果更加的美观一些,有兴趣的可以参考我的代码;
(3)我对参数输入也进行了修改,将模型名字和图片库的路径都固定了,这样子测试的时候比较方便,大家在使用的时候请注意下,如果修改了名字要对应起来。

#操作汇总
# (1)打开终端执行index.py代码
python3 index.py -database img -index lol.h5
# 此时已经将图片库转成索引库并保存和输出lol.h5模型
# (2)继续运行代码 query_online.py
python3 query_online.py
# 按照提示,如果要退出输入 exit 查询直接enter
# 输入测试图片 名字即可(如果测试图片额代码不在同一路径下需要增加路径——这里 设置EI相对路径)代码:https://github.com/DWCTOD/flask-keras-cnn-image-retrieval-master
可以的话,也可以点一下下star,感谢
五、演示操作和效果



这篇关于是时候展示一波花里胡哨了——以图搜图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!