本文主要是介绍【VIS】Video Instance Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/Yang_Video_Instance_Segmentation_ICCV_2019_paper.pdf
代码地址:https://github.com/ youtubevos/MaskTrackRCNN
新数据集:YouTube-VIS,地址:https:// youtube-vos.org/dataset/vis
字节跳动的大佬又开辟了新的task:Video Instance Segmentation,但今天看到已经算晚的了,2019年都已经办过比赛了。今天读一读这篇论文。
按照作者的定义,VIS是一个 aims at simultaneous detection, segmentation and tracking of object instances in videos.可算是把所有能用的方法都融合的很难的task了。
Problem Definition
这个任务的目标就是,把视频帧的每一个实例分割出来。与VOS不同的是,VOS不需要知道分割前景的label,VIS不仅要连续追踪,分割,而且要做到实例分割,那么就有一个难点:有的实例不是第一帧会出现的,这是与VOS不同的。
Evaluation Metrics
作者借用了实例分割使用的AP和AR两个指标,迁移到本任务里。
AP is defined as the area under the precision-recall curve. The confidence score is used to plot the curve. AP is averaged over multiple intersection-over-union (IoU) thresholds.
AR is defined as the maximum recall given some fixed number of segmented instances per video.
但是本任务IOU计算和image instance segmentation不同,计算如下,T为某一个视频的总帧数,m是binary segmentation mask.
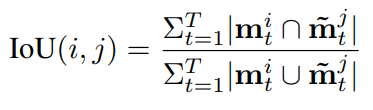
也就是说,第一帧的时候,后面的都为0,只算第一帧的IOU,第二帧的时候,算第一帧和第二帧,其他为0,以此类推。
作者任务可以达到If the algorithm detects object masks successfully, but fails to track the objects across frames, it will get a low IoU这样的效果。
MaskTrack R-CNN

介绍一下论文作者用的网络,简单来说就是Mask-RCNN再加一个分支叫“Track Head”。
整个网络也是two-stage的,first stage就是对每一帧都产生各自的一系列object Bbox。
在Bbox Head 和 Mask Head 计算的同时,加一个 Track Head(2个全连接层),用于对每一个候选框分配一个instance label。
假设已经计算出了前一帧有N个instance,那么当前帧的候选框所属的label要么属于这N个,要么属于一个新的label。所以把这个当作N+1的分类问题,可以计算一个label n被分配给候选框i的概率:
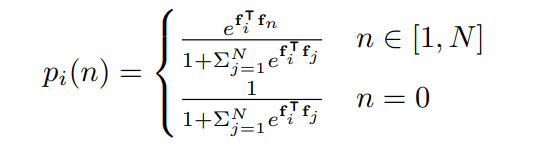
这是一个多项式逻辑回归。可以看出,在算fi和fn的内积,那么问题来了,fn,fj,j∈[1,N]是哪来的?
其中fi是输入Track Head的当前帧的RoI Align的feature,而其他是前一帧存下来的feature(Memory)。
这里用一个CE Loss来约束Track Head,![]() ,y_i是对应实例label。
,y_i是对应实例label。
如果当前帧的候选框i对应的label属于前一帧的N个实例中的一个,那么Memory里的feature会更新;如果是一个新的label,那么Memory里也会添加一个新的feature。
训练的时候,随机挑选一对frames,一个做reference,一个做query。对reference只提取GT里instance region里的feature存到memory里,query frame会先在first stage里选出positive candidate bbox,在对它分配label。作者选择IOU 和GT bbox overlap超过0.7的做为positive。
整个网络的LOSS是: ![]()
但最后,所有cues整合,才能确认最终的对应的instance的分割,也即分配给每个bbox的label的score如下,本文是做一个后处理:
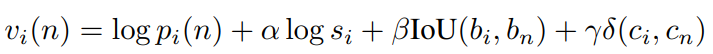
p_i是刚才的概率,s_i是置信度,b_i是bbox,c_i是class。这个方程只在测试时应用,不对训练做贡献。
作者发现,IOU和class consistency比较重要。而置信度只是轻微提升效果。
值得一提的是,Track Head只训了20个epoch,整个网络的处理速度是20fps。

指标的话好像没有那么强,现在看VIS数据集的比赛最高已经mAP0.446 了,哎,大神们动手都太快了。
2020年01月09日
这篇关于【VIS】Video Instance Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







