本文主要是介绍DDD领域驱动设计:贫血模型和充血模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何快速区分贫血模型和充血模型
贫血模型和充血模型从代码实现和使用上其实很容易区分,下面通过一张简图来说明:
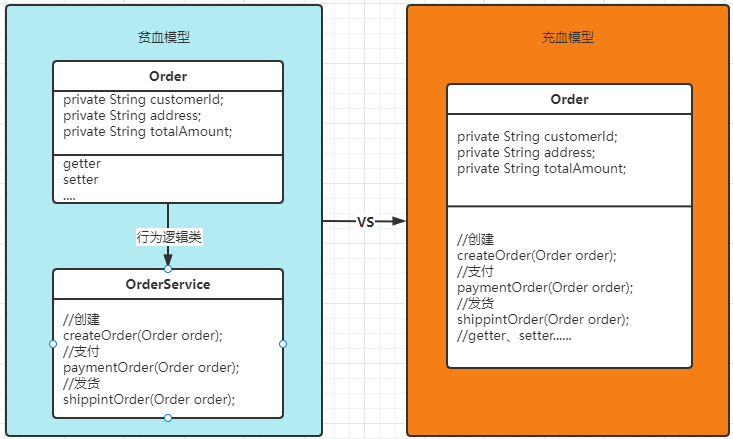
贫血模型在实现上的特点:
订单对象Order非常贫血,只承载数据属性以及属性的getter和setter方法,订单对象的行为通过创建另外一个通常称之为Service的对象来承担,属性和行为分开不同类来实现,打破面向对象思想这种做法,在MVC架构时我们再熟悉不过。
充血模型在实现上的特点:
订单对象Order被充血,不仅承载数据属性,同时承担了订单对象本身相关的行为方法,非常符合面向对象思想,属性和行为都由通过对象来实现。
贫血模型和充血模型应对业务变化的演变
假定业务上从原来的普通订单流程基础上,新增秒杀业务流程,此时有两条订单流程(普通、秒杀),贫血模型演变如下:
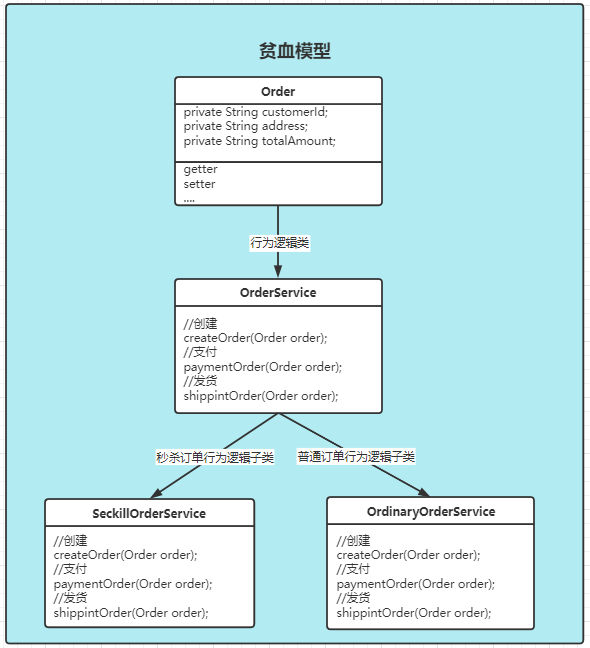
充血模型演变如下:
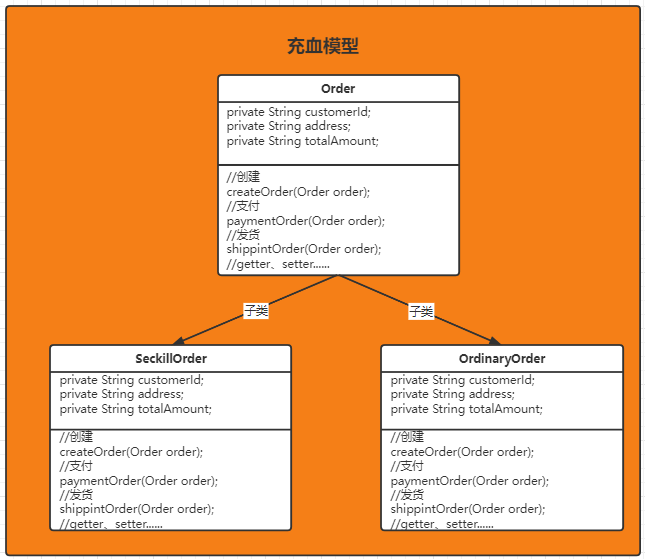
客户的创建订单代码示例:
//贫血模型创建秒杀订单Order order = new Order();OrderService seckillOrderService = new SeckillOrderService();seckillOrderService.createOrder(order);//充血模型创建秒杀订单Order seckillOrder = new SeckillOrder();seckillOrder.createOrder();从上面的演变可以看出,贫血模型和充血模块并没有太大的区别,甚至对于使用客户端来说感受几乎一样,都是多态的方式实例化对应订单流程对象进行createOrder行为的调用。那充血模型和贫血模型到底有什么区别?
充血模型的优势
事实上,贫血模型除了没有符合面向对象原则外,跟充血模块并没有什么太多的区别,那么既然这样,我们就可以回到面向对象的优势上去思考充血模型相对贫血模型的优势,我们来回顾下面向对象的三大特性:封装、继承、多态
1、封装,也就是把客观事物封装成抽象的类,并且类可以把⾃⼰的数据和⽅法只让可信的类或者对象操作,对不可信的进⾏信息隐藏。
2、继承,它可以使⽤现有类的所有功能,并在⽆需重新编写原来的类的情况下对这些功能进⾏扩展。
3、多态,是允许你将⽗对象设置成为和⼀个或更多的他的⼦对象相等的技术,赋值之后,⽗对象就可以根据当前赋值给它的⼦对象的特性以不同的⽅式运作。简单的说,就是⼀句话:允许将⼦类类型的指针赋值给⽗类类型的指针。实现多态,有⼆种⽅式,重写,重载。
简单总结,OOP最大好处就是:做到代码即业务,使通用能力可复用,个性化能力通过多态去实现,做到高内聚,低耦合,核心是提高复用,降低维护成本。
充血模型的劣势
1、充血模型最大的改变设计思路,从业务服务类的方式去堆业务转变为理解对象领域和业务领域的对应关系上来,这就对开发人员OOP抽象能力有非常高的要求;
2、那么充血模型下是不是就完全不需要Service呢,其实仍然需要Service,例如下面示例代码:
//充血模型下需要Service的场景Order sekillOrder1 = new SeckillOrder();Order sekillOrder2 = new SeckillOrder();OrderService orderService = new OrderService();//比较两个订单的总金额,返回金额较大的Order maxOrder = orderService.diffAmount(sekillOrder1, sekillOrder2);很明显,订单对象按面向对象思想只能操作自己本身的数据,不能操作跨订单对象的数据,这时就需要引入Service。这种情况就要去开发人员能够划分清楚Order对象和OrderService的边界;
充血模型适用场景
充血模型更多适用于业务复杂、多变的场景,同时开发人员抽象能力普遍较强的团队。
最后总结
并不能认为任何场景充血模型都优于贫血模型,事实上,贫血模型仍然有很大的优势和场景,只要代码结构写的,多用设计模式去写代码,贫血模型照样可以玩的很溜。
无论是充血模型还是贫血模型,还是其它软件设计方法、架构论,目的永远就是一条:降低软件工程复杂度,提高代码复用,降低维护修改成本。
任何代码只要符合上述要求,都是好代码、好设计、好架构。
---------- 正文结束 ----------
长按扫码关注微信公众号Java软件编程之家这篇关于DDD领域驱动设计:贫血模型和充血模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







