本文主要是介绍什么是GC Roots?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么有GC Roots?
java程序在运行的时候,无时无刻都在创建对象,当一些对象已经超过相应的作用域的时候,同时在年轻代的空间不够的时候,就需要进行垃圾回收,对无用的对象进行回收,释放对应的内存。
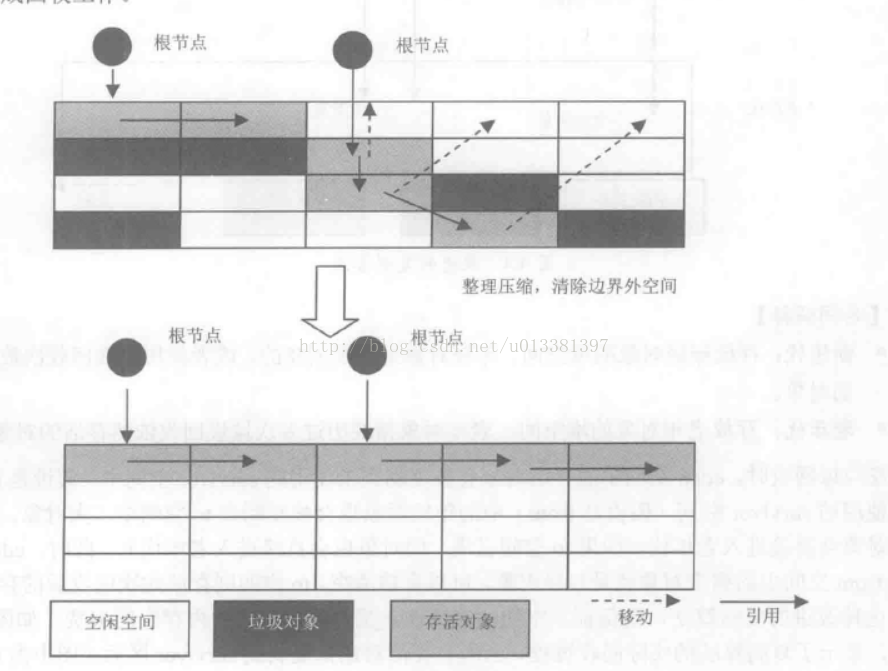
既然要进行回收对象,那肯定是要回收那些已经没用的对象,对运用运行没有影响的那些对象。如何判断对象是否没用并可以回收呢?可达性分析算法
通过一系列 GC Roots 的根对象作为起始点,然后从这些点开始进行搜索,搜索能到的路径,能够在这些链路上的对象,都是有用对象,反之,不在这些路径的对象都是无用的对象,需要被垃圾回收的对象。
可作为 GC Roots 的对象包括下面几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。
- 本地方法栈中 JNI(Native方法)引用的对象
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
- 根据用户所选用的垃圾收集器以及当前回收的内存区域不 同,“临时性”地加入的其他对象。
Java虚拟机定义3种类加载器:
- 启动类加载器(Bootstrap Class Loader):也称为根类加载器,它负责加载Java虚拟机的核心类库,如java.lang.Object等。启动类加载器是虚拟机实现的一部分,它通常是由本地代码实现的,不是Java类。
- 扩展类加载器(Extension Class Loader):它是用来加载Java扩展类库的类加载器。扩展类库包括javax和java.util等包,它们位于jre/lib/ext目录下。
- 应用程序类加载器(Application Class Loader):也称为系统类加载器,它负责加载应用程序的类。它会搜索应用程序的类路径(包括用户定义的类路径和系统类路径),并加载类文件。
这篇关于什么是GC Roots?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!