本文主要是介绍prophet Uncertainty Intervals不确定性区间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
例子代码
https://github.com/lilihongjava/prophet_demo/tree/master/uncertainty_intervals
# encoding: utf-8
"""
@author: lee
@time: 2019/8/6 9:22
@file: main.py
@desc:
"""
from fbprophet import Prophet
import pandas as pddef main():df = pd.read_csv('./data/example_wp_log_peyton_manning.csv')df = df.loc[:180, ] # Limit to first six monthsm = Prophet()m.fit(df)future = m.make_future_dataframe(periods=60)# 趋势的不确定性forecast = Prophet(interval_width=0.95).fit(df).predict(future)# 季节性的不确定性m = Prophet(mcmc_samples=300)forecast = m.fit(df).predict(future)fig = m.plot_components(forecast)fig.show()if __name__ == "__main__":main()
默认情况下,Prophet将返回预测返回值中yhat有不确定性区间。这些不确定性区间背后有几个重要的假设。
预测结果中存在三个不确定性来源:趋势的不确定性,季节性的不确定性以及额外的观测噪声。
趋势的不确定性
预测中最大的不确定性来源是未来趋势变化的可能性。我们在之前本系列文档中已经看到时间序列显示了历史上明显的趋势变化。prophet能够发现和拟合这些,但是我们应该期待哪些趋势会发生变化呢?我们无法确切地知道,所以我们尽我们所能做最合理的事情,并且假设我们未来看到的会与历史相似的趋势变化。特别是,我们假设未来趋势变化的平均频率和幅度与我们在历史上观察到的相同。 我们预测这些趋势变化并通过计算它们的分布来获得不确定性区间。
这种测量不确定度方法的一个特点是允许在速率上具有更高的灵活性,通过增加changepoint_prior_scale的值,将增加预测不确定性。 这是因为,如果我们对历史数据更多的速率变化进行建模,那么我们将对未来预测有更多的速率变化,并使不确定性区间成为过度拟合的有用指标。
可以使用以下interval_width参数(默认为80%)设置不确定区间的宽度:
# Python
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
这些区间假设未来看到的与过去有相同的频率和幅度变化。这个假设可能不正确,所以不应该期望从这些不确定区间得到准确覆盖。
季节性的不确定性
默认情况下,Prophet只会返回趋势和观察噪声的不确定性。为了获得季节性的不确定性,必须进行完整的贝叶斯抽样。通过使用参数mcmc.samples(默认为0)来完成。以下使用快速入门中的Peyton Manning前六个月的数据:
# Python
m = Prophet(mcmc_samples=300)
forecast = m.fit(df).predict(future)
这里用MCMC采样取代最大后验估计,而且根据观测的数量,可能需要更长的时间---这里需要几分钟而不是原来几秒钟。如果进行完整采样,那么在绘制它们时,将看到季节性成分的不确定性:
# Python
fig = m.plot_components(forecast)
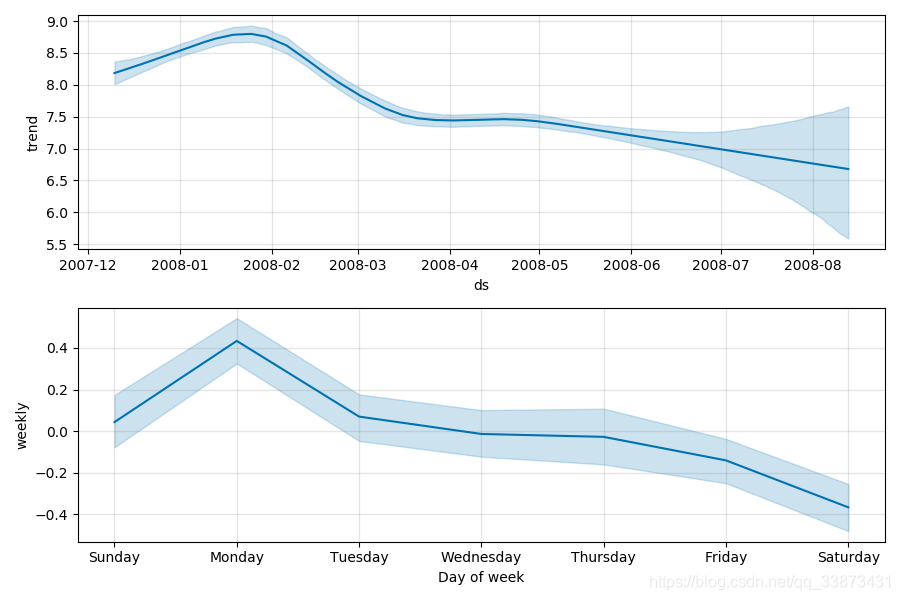
在Python中可以使用 m.predictive_samples(future)方法访问获取原始后验预测样本,或者在R语言中用 predictive_samples(m, future)。
prophet使用的底层PyStan在Windows下中存在问题,这使得MCMC采样速度极慢。在Windows中使用MCMC采样的最佳选择是使用R语言来实现,如果选择用python实现,那么需要在Linux下。
参考资料:
https://facebook.github.io/prophet/docs/uncertainty_intervals.html
这篇关于prophet Uncertainty Intervals不确定性区间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




