本文主要是介绍机器学习D10——WOE和IV编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
- WOE和IV通常是用在模型特征筛选的。IV和WOE能够帮助我们衡量什么变量应该进入模型,什么变量应该舍弃。用IV和WOE的值来进行判断,值越大就表示该特征的预测能力越强,则该特征应该加入到模型的训练中。
应用
- 1、变量筛选。我们需要选择重要的变量加入模型,预测强度就可以作为我们判断变量是否重要的一个依据。
- 2、指导变量离散化。在建模过程中,时常需要对连续变量进行离散化处理,如年龄分段。但变量的不同离散化结果(如:年龄分为[0-20]还是[0-15])会对模型产生不同的影响。因此,可以根据指标反应的预测强度,调整变量离散化结果。
WOE
- WOE(Weight Of Evidence)用来衡量特征的预测强度,要使用WOE的话,首先要对特征进行分箱(分组:将一种特征的组成元素进行分组),分箱之后,对于其中第i组的WOE值公式如下:
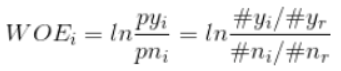
- 其中,pyi表示该组中的正例占负例样本的比例,pni表示整体的正例占负例样本的比例。
- 根据ln函数的特性,就是当这个组中响应样本的比例比总体的响应比例小时为负数,相等时为0,大于时为正数。
- 我们可以把所有分组的WOE值的绝对值加起来,这个可以在一定程度上表示这个变量的预测能力,但是我们一般不会这么做,因为对于分组中的样本数量相差悬殊的场景,WOE值可能不能很好的表示出这个变量的预测能力,我们一般会用到另一个值:IV值。这个值在计算的时候,比WOE值多考虑了一层该变量下该分组占该变量下所有样本的比例。
IV
- IV值的计算公式是在WOE的基础上多乘了一个(py_i-pn_i)
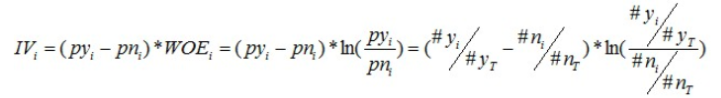
- 把分组计算出来的所有IV值加起来,就是这个变量的IV值,然后把所有变量的IV值都算出来,就可以根据IV值的大小来看出变量的预测能力。
分箱
- 数据分箱(也称为离散分箱或分段)是一种数据预处理技术,用于减少次要观察误差的影响,是一种将多个连续值分组为较少数量的“分箱”的方法。说白了就是将连续型特征进行离散化。
- 例如,如果我们有一组关于人年龄的数据,我们可以设置一些条件将他们的年龄分组到更少的间隔中。
- 对连续性特征进行离散化
- 对连续性特征进行离散化
- 注意:
- 分箱的数据比一定必须是数字,它们可以是任意类型的值,如“狗”,“猫”,“仓鼠”等。分箱也用于图像处理,通过将相邻像素组合成单个像素,它可用于减少数据量。
- 分箱的作用和意义
- 离散特征的增加和减少都很容易,易于模型的快速迭代,提升计算速度。
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。
- 特征离散化以后,起到了简化了模型的作用,可以适当降低了模型过拟合的风险。
- pandas实现数据的分箱:pd.cut()
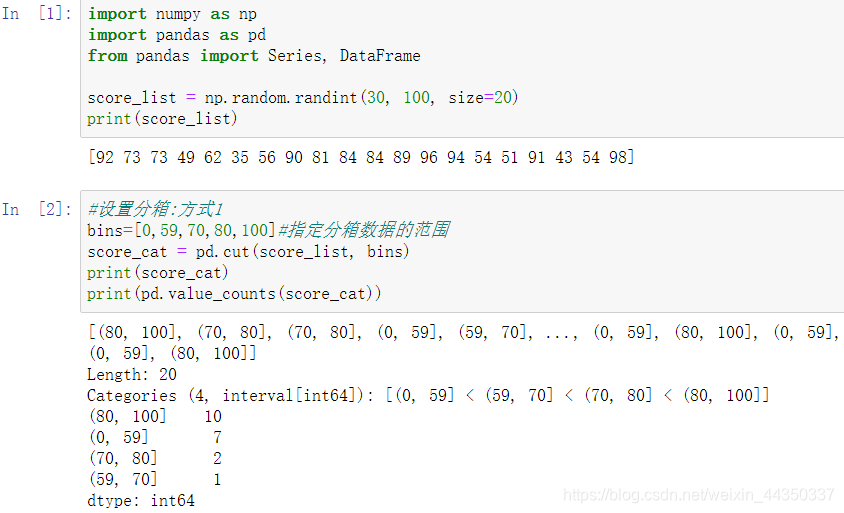
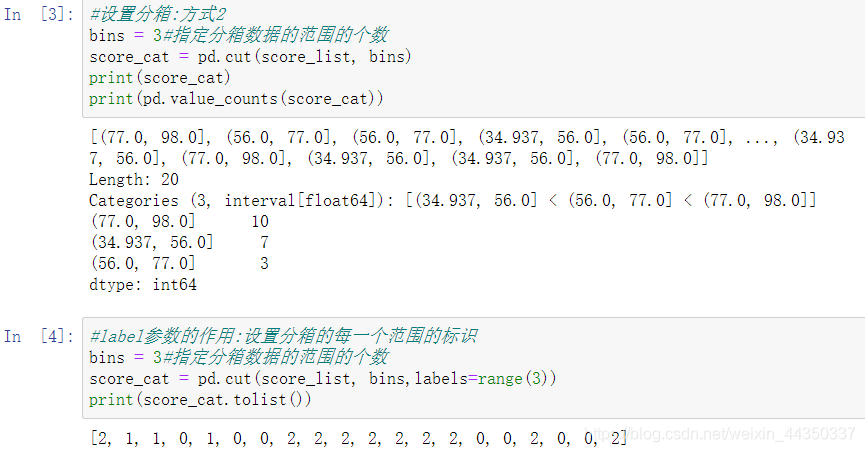
- 注意:我们对特征进行分箱后,需要对分箱后的每组(箱)进行woe编码,然后才能放进模型训练。
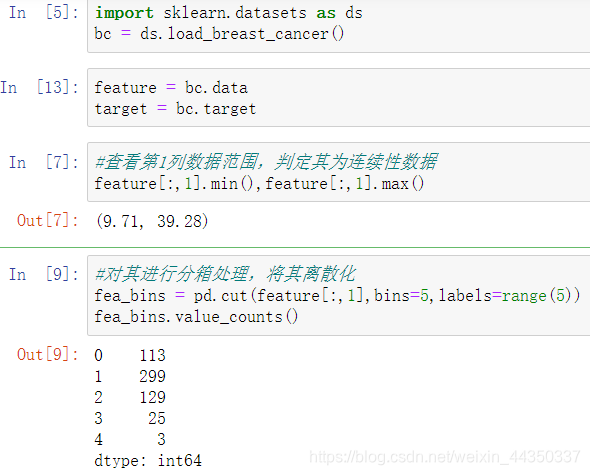
- 进行WOE编码其实就是上面的分组结果给个组号标识。


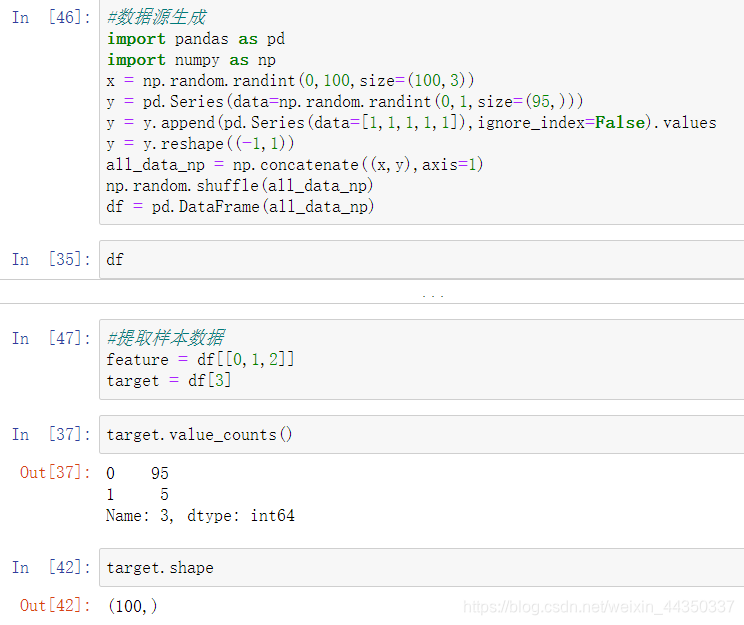
样本类别分布不均衡处理
- 什么是样本类别分布不均衡?
- 举例说明,在一组样本中不同类别的样本量差异非常大,比如拥有1000条数据样本的数据集中,有一类样本的分类只占有10条,此时属于严重的数据样本分布不均衡。
- 样本类别分布不均衡导致的危害:
- 样本类别不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律;即使得到分类模型,也容易产生过度依赖与有限的数据样本而导致过拟合问题,当模型应用到新的数据上时,模型的准确性会很差。
- 解决方法:
- 通过过抽样和欠抽样解决样本不均衡
- 过抽样(over-sampling)【就是插值】:
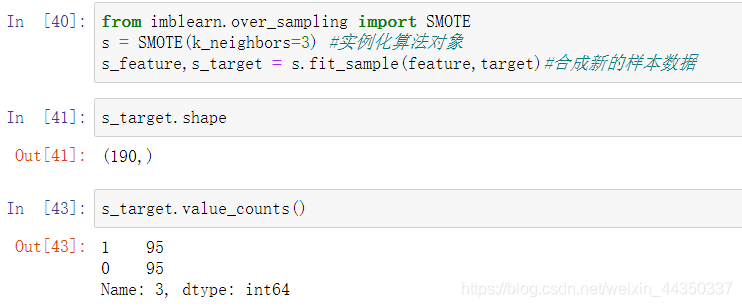
- from imblearn.over_sampling import SMOTE
- 通过增加分类中少数类样本的数量来实现样本均衡,比较好的方法有SMOTE算法。
- SMOTE算法原理介绍:
- 简单来说smote算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
- 环境安装:pip install imblearn
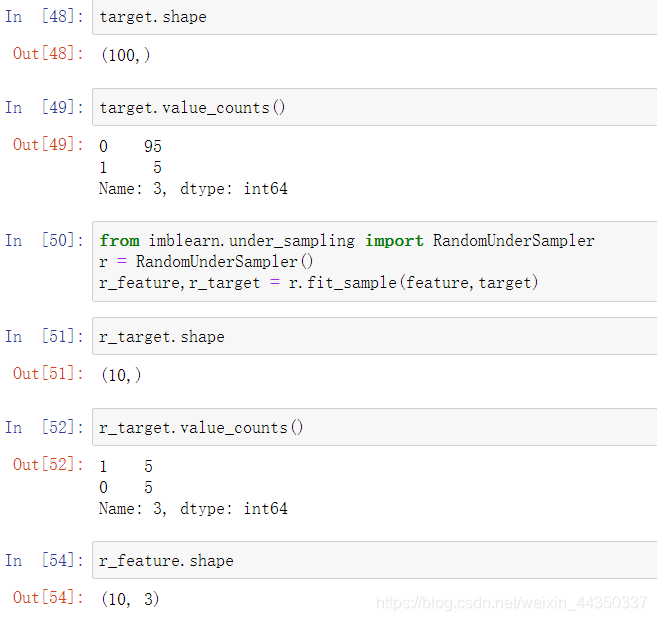
- 欠抽样(under-sampling)【多余数据不要】:
- 通过减少分类中多数类样本的数量来实现样本均衡
- from imblearn.under_sampling import RandomUnderSampler
这篇关于机器学习D10——WOE和IV编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





