本文主要是介绍python高潜用户分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高潜用户应该具有的特征:
1)必须有购买行为;
2)对一个商品购买,并且有其他交互行为(如浏览、点击、收藏等)
3) 最早交互时间跟购买时间要大于1
需要处理的数据:自行下载
字段名称 意义 字段名称 意义 user_id 用户编号 user_id 用户编号 age 年龄 sku_id 商品编号 sex 性别 type 行为类型 user_lv_cd 用户级别 time 行为时间 browse_num 浏览数 ate 品类ID addcart num 加购数 delcart num 删购数 buy_num 购买数 favor_num 收藏数 click_num 点击数
# 读取数据
path = r'E:\python\python项目\数据分析\用户画像分析\action.csv'
chunker = pd.read_csv(path, iterator=True)
loop = True
chunksize = 10000 # 设置每次读取10000条数据
chunks = []
while loop:try:chunk = chunker.get_chunk(chunksize)[['user_id', 'sku_id', 'type', 'time', 'cate']]chunks.append(chunk)except StopIteration:loop = Falseprint('文件读取完毕')
# print(chunks)
action = pd.concat(chunks, ignore_index=True)这里我们先读action.csv ,由于数据量比较大,(数据太大读不出来,程序会报错)我们需要按块读取,每次读一点。
数据清洗:
这个表的数据基本可以算是比较好的,不需要数据清洗。
#查看是否需要进行数据清洗
print(action.isnull().sum()) # 无空值
print(action.duplicated().sum()) # 重复值
# 异常值
print(action.describe())#我们在运行的时候发现 时间这一列类型不太对,所以我们就转换一下格式
print(action.info())#类型转换
action['time'] = pd.to_datetime(action['time'])
action['user_id'] = action['user_id'].astype('int')
数据筛选:
1:筛选出购买行为的用户。
action.csv 表中 type列是 行为类型
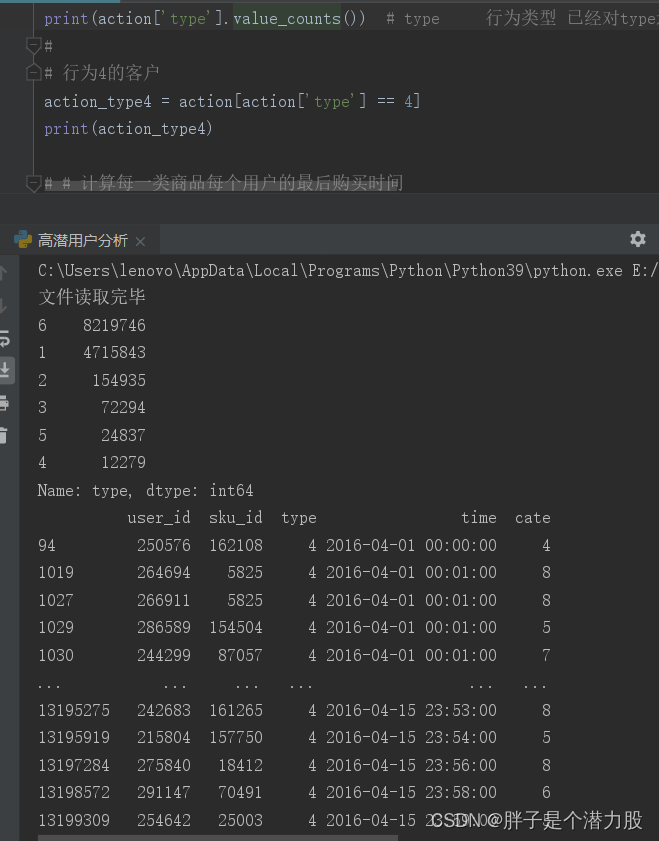
print(action['type'].value_counts()) # type 行为类型 已经对type进行了分类,我们只需要找到数值最低的,就是购买的用户
我们运行查看行为类型后发现,已经是有分好类了,1,2,3,4,5,6.这六种类型,分别对应了多少行。这样我们目前还是不知道那一行是购买记录。所以可以根据实际分析,购买的行为应该是最少的。所以我们就定位到行为为4的购买记录。
然后进行筛选出行为4的客户如下图所示。
# 行为4的客户
action_type4 = action[action['type'] == 4]
print(action_type4)
# 计算每一类商品每个用户的最后购买时间
ac_lastbuytime = action_type4.groupby(by=['cate', 'user_id'])['time'].apply(lambda x: x.max())
print(ac_lastbuytime.head())# 最早与该商品发生交互的日期
# ac_lastbuytime 表id具有唯一性 与总表进行合并,
ac_all_buy = pd.merge(ac_lastbuytime, action, left_on='user_id', right_on='user_id')
print(ac_all_buy.head())ac_firsttime = ac_all_buy.groupby(by='user_id')['time_y'].apply(lambda x: x.min())df = pd.merge(ac_lastbuytime, ac_firsttime.to_frame(), on='user_id')
df.columns = ['buy_time', 'ac_time']
print(df)#计算时间差df['days'] = (pd.to_datetime(df['buy_time']) - pd.to_datetime(df['ac_time'])).dt.days
print(df)# 获取高潜力用户
high_pot = df[df['days'] > 1]
print(high_pot)上面这一段是筛选出高潜用户。
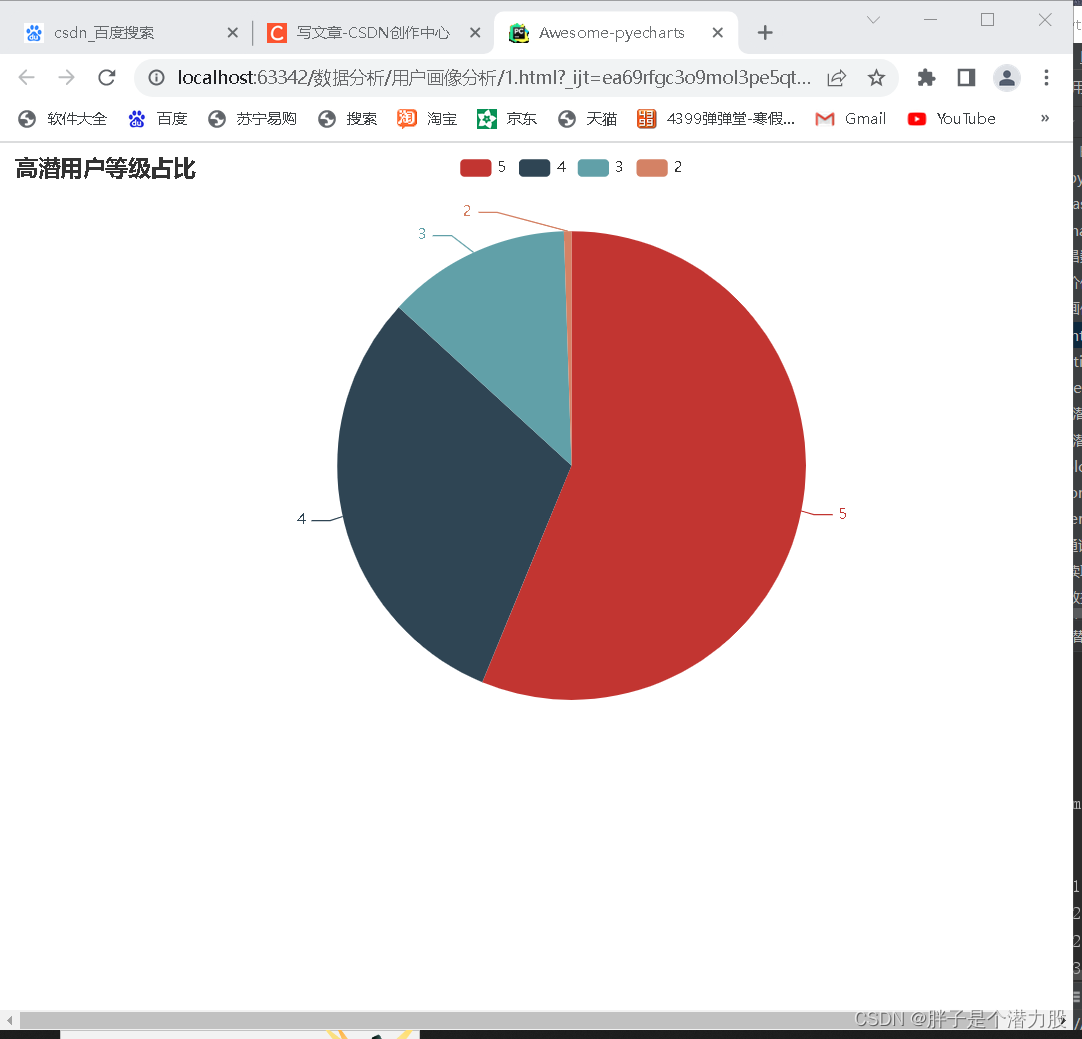
筛选出来后,我们对客户等级进行分类,然后生成一个图表。
# 用户表user = pd.read_csv(r'E:\python\python项目\数据分析\用户画像分析\user.csv')
# 表合并
user_high = pd.merge(user, high_pot, on='user_id')#去重
user_high.drop_duplicates(subset=['user_id'],inplace=True)
print(user_high)# 用户等级分布
user_lv_count = user_high['user_lv_cd'].value_counts()
print(user_lv_count)# 数据可视化
num = user_lv_count.values.tolist()#转列表
lev = user_lv_count.index.tolist()
data_pair = [(i,j)for i ,j in zip(lev,num)]
pie = (Pie().add('',data_pair).set_global_opts(tooltip_opts=opts.TooltipOpts(is_show=True,formatter='等级{b}:{d}%'),title_opts={'text':'高潜用户等级占比'}))
pie.render_notebook()pie.render("1.html")使用pyecharts库生成一个HTML文件,这个库做出了的表比较好看,有一点动画效果。
import pandas as pd
from pyecharts.charts import Pie
import pyecharts.options as opts# 读取数据
path = r'E:\python\python项目\数据分析\用户画像分析\action.csv'
chunker = pd.read_csv(path, iterator=True)
loop = True
chunksize = 10000 # 设置每次读取10000条数据
chunks = []
while loop:try:chunk = chunker.get_chunk(chunksize)[['user_id', 'sku_id', 'type', 'time', 'cate']]chunks.append(chunk)except StopIteration:loop = Falseprint('文件读取完毕')
# print(chunks)
action = pd.concat(chunks, ignore_index=True)
# print(action.head())
# print(action.info())# 数据清洗# print(action.isnull().sum()) # 无空值# 重复值
# print(action.duplicated().sum())# 异常值
# print(action.describe())#类型转换
action['time'] = pd.to_datetime(action['time'])
action['user_id'] = action['user_id'].astype('int')
#
# print(action.info())
#
print(action['type'].value_counts()) # type 行为类型 已经对type进行了分类,我们只需要找到数值最低的,就是购买的用户
#
# 行为4的客户
action_type4 = action[action['type'] == 4]
print(action_type4)# 计算每一类商品每个用户的最后购买时间
ac_lastbuytime = action_type4.groupby(by=['cate', 'user_id'])['time'].apply(lambda x: x.max())
print(ac_lastbuytime.head())# 最早与该商品发生交互的日期
# ac_lastbuytime 表id具有唯一性 与总表进行合并,
ac_all_buy = pd.merge(ac_lastbuytime, action, left_on='user_id', right_on='user_id')
print(ac_all_buy.head())
#
ac_firsttime = ac_all_buy.groupby(by='user_id')['time_y'].apply(lambda x: x.min())df = pd.merge(ac_lastbuytime, ac_firsttime.to_frame(), on='user_id')
df.columns = ['buy_time', 'ac_time']
print(df)# 计算时间差df['days'] = (pd.to_datetime(df['buy_time']) - pd.to_datetime(df['ac_time'])).dt.days
print(df)# 获取高潜力用户
high_pot = df[df['days'] > 1]
print(high_pot)
#
# 用户表user = pd.read_csv(r'E:\python\python项目\数据分析\用户画像分析\user.csv')
# 表合并
user_high = pd.merge(user, high_pot, on='user_id')#去重
user_high.drop_duplicates(subset=['user_id'],inplace=True)
print(user_high)# 用户等级分布
user_lv_count = user_high['user_lv_cd'].value_counts()
print(user_lv_count)# 数据可视化
num = user_lv_count.values.tolist()#转列表
lev = user_lv_count.index.tolist()
data_pair = [(i,j)for i ,j in zip(lev,num)]
pie = (Pie().add('',data_pair).set_global_opts(tooltip_opts=opts.TooltipOpts(is_show=True,formatter='等级{b}:{d}%'),title_opts={'text':'高潜用户等级占比'}))
pie.render_notebook()pie.render("1.html")源码如下:
这篇关于python高潜用户分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





