本文主要是介绍SpringCloud学习——浅学习(个人整理,很长,适合时间较多的观看),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
根据我的学习规划,目前这个阶段应该是学习ssm整合和springboot,但是目前换工作,公司项目使用springcloud,为了生存,计划总是要变的,这话一点毛病没有。
二 springcloud介绍
1. 单体应用架构
单体应用架构和垂直应用架构相对应, 简单的点说就是将业务都在一个项目中,这样的好处是开发简单,比较适合小型应用,当然缺点是不易维护,代码的耦合性也非常高
2. 垂直应用架构
相对于单体应用架构,垂直应用架构将业务中一个个模块分别在一个个不同的项目工程中,分别去启动部署,这样有点事解决高并发、可以针对不同的模块进行优化,方便扩展和容错;缺点就是系统间相互独立,有一些基础代码会重复开发
3.分布式架构
分布式架构其实可以看成是垂直应用架构的一种优化,它将垂直应用架构中的基础服务代码抽取了出来,成立了一个单独的服务层,由不同的系统去调用服务层来完成代码逻辑的实现。当服务层越来越多,如何调用它就成了新的问题,这时提出了一个中间调度层,也就是dubbo
4.微服务架构
微服务架构在我理解中是对分布式架构的升华,它的重点就是业务需要彻底组件化和服务化,原有的单个业务系统彻底拆分成为多个可以单独开发、设计、运行的小应用
三 注册中心
eureka
因为工作需要,就不详细写相关的知识概要了,这些内容网上有很多,以下以例子和重点知识为主
Eureka注册中心分为服务端、服务提供者、服务消费者
eureka中的元数据:服务的主机名、ip、端口号等信息,可以通过eurekaServer服务端进行获取,用于服务之间的调用
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
springboot 自动装载,自动加载factory后缀名的文件
2. Ribbon
Ribbon是netfix公司开发,具有服务调用和负载均衡功能,配合eureka使用
负载均衡
负载均衡的意思就是在系统中有多个相同的服务A,他们都可以提供相同的服务,调用服务A时应该选择哪一个,这里就用到了负载均衡,选择最适合的服务进行使用
负载均衡分为客户端负载均衡、服务端负载均衡,客户端负载均衡就是在客户端中记录所有服务A的ip地址,通过客户端算法选择合适的服务;服务端负载均衡典型就是nginx、f5(硬件)
Ribbon是典型的客户端方式的负载均衡,记录所有服务的ip,通过算法来选择合适的服务进行调用
Consul
consul同样是一种注册中心,它相较于eureka来说更加一站式,并且是由go语言编写的,使用它只需要下载相关的exe程序在本地运行就可以启动服务了
下载地址
https://www.consul.io/downloads.html
启动consul windows dos命令
consul agent -dev -clinet 0.0.0.0
agent:启动一个consul保护进程
dev:开发者模式,更快应用于开发
client:0.0.0.0 任何ip地址都可以访问
consul启动模式 除了上述dev以外,还有client、server
client:是consul代理和consul server 之间进行交互,一个client对应一个微服务,一般情况下一个微服务和client部署到一个服务器上
server:server 服务
sonsul中涉及的两种协议:Gossip、Raft
Gossip:所有 consul节点都会参与到gossip协议中(多节点中数据复制)
Raft:主要选主,数据同步,以下
1.保证server集群的数据一致
2.三种角色划分:
(1)Leader:是server集群中唯一处理端请求的
(2)Follow:选民,被动接受数据
(3)候选者:可以选择为leader
4 Feign
消费者调用组件,feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service。
具体可看这篇博客https://www.jianshu.com/p/8bca50cb11d8,很通俗易懂
5.Hystrix
Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程隔离、信号量隔离、降级策略、熔断技术、限流技术。
雪崩效应:对于我而言,简单的理解就是当一个服务节点因为其他原因不能使用了,导致整个服务无法使用,引起所谓的雪崩效应
- 信号量隔离本人理解不深就不误人子弟了,网上或netflix官网有完美解释
- 线程池隔离:执行依赖代码的线程与请求线程(比如Tomcat线程)分离,请求线程可以自由控制离开的时间,这也是我们通常说的异步编程,Hystrix是结合RxJava来实现的异步编程。通过设置线程池大小来控制并发访问量,当执行线程饱和的时候可以拒绝服务,防止依赖问题扩散。
- 熔断:在微服务的环境中,当某个节点出现了问题导致无法调用,而采取的牺牲局部保全大局的就是熔断,也就是说服务A调用服务B,此时服务B出现了问题,导致服务A访问等待服务B过慢或者访问不到,此时服务A则认为服务B已经挂掉了,不在访问服务B,这样就可以立即返回不会造成请求堆积。
- 降级:当服务B挂掉后,服务A立即返回,如果立即返回一个报错信息那非常不友好,此时可以采用降级策略,返回一个服务A本地默认数据,来告诉访问者出现了问题
- 限流:限流在一个参考文章中,认为是降级的一部分,也就是说当访问服务B的时候,其实我们是可以对服务B进行一个评估的,可以评估出来服务B的承载能力,如果超过了一个评估的阈值则采取限流策略,比如拒绝访问、部分访问、降级处理等
Hystrix 监控平台Dashboard和actuator
1.引入坐标
<!--引入hystrix actuator 监控信息--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId></dependency>
- 再启动类上 启用
@SpringBootApplication
@EnableDiscoveryClient
// 启动Feign
@EnableFeignClients
//激活hystrix 的监控信息,在feign中只使用熔断不需要加这个注解
@EnableCircuitBreaker
//启动 hystrix dashboard web页面
@EnableHystrixDashboard
public class ConsumerApplication {public static void main(String[] args) {SpringApplication.run(ConsumerApplication.class, args);}}
- hystrix web监控页面详解

Hystrix 中 断路器
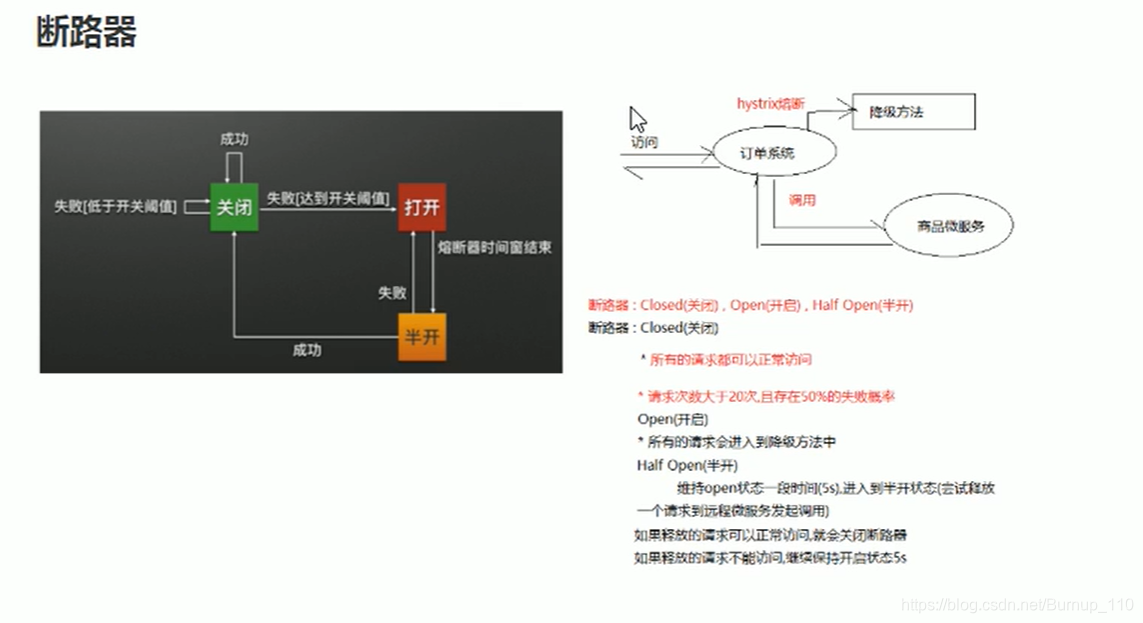
断路器中有三种状态,open,closed,half-open
正常情况下是closed,此时所有的请求是正常访问的
当服务A访问服务B,超过一个阈值,如在20此请求中超过50%的失败率则断路器进入open状态,此时服务A将不再请求服务B,而是直接触发他的降级方法。默认open(睡眠)状态是5s,5s后会进入到half-open状态
在half-open状态中,服务A会尝试请求服务B,请求成功则进入closed状态,失败则保持open状态5s
线程池隔离和信号量隔离的区别

6. Sentinel
Sentinel 是alibaba开发的服务隔离组件,他主要采取的方式是信号量隔离的方式。
官方参考文档
使用Sentinel进行熔断保护可以分为以下几个步骤
定义资源
定义规则
判断规则是否有效
资源:可以是一个服务,服务中的一个方法,甚至是一段代码
规则:流量控制规则、熔断降级规则、系统保护规则、来访访问规则规则、热点参数规则等。Sentinel的规则都是在内存中动态查询和修改、修改后立即生效(这点和hystrix不同)
也就是说,在开发的时候,我们先定义资源,然后再规定规则,只需要在开发中将需要服务隔离的服务定义为资源后,后续就可以根据需要定义规则
6.1 管理控制台
下载最新的控制台jar包
下载后,可以直接通过dos进行启动它
java -Dserver.port=18080 -Dcsp.sentinel.dashboard.server=localhost:18080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar
使用上边的命令启用它,这边设置的端口号是18080,这个可以根据需要进行更改
接下里就可以看到下面这个页面,账号密码都是sentinel

6.2 项目引入sentinel控制台
(1)引入sentinel依赖包
<!--sentinel 服务隔离--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId><version>2.0.2.RELEASE</version></dependency>
(2)配置properties.yml文件
spring:cloud:sentinel:transport:dashboard: localhost:18080
(3)指定服务资源
/*** @SentinelResource* blockHandler:发生熔断时调用的降级方法* fallback:抛出异常执行的降级方法*/@SentinelResource(blockHandler = "testBlockHandler",fallback = "testFallback")@GetMapping("getMessage")public String getRibbon(String name){if (!name.equals("1")){throw new RuntimeException();}ResponseEntity<String> entity=restTemplate.getForEntity("http://eureka-provider/provider/get/"+name,String.class,"NAME");return "entity.getStatusCode():"+entity.getStatusCode()+"\n entity.getHeaders():"+entity.getHeaders()+"\n entity.getBody():"+entity.getBody();}/*** sentinel* 发生异常执行的降级方法* 熔断执行的降级方法*/public String testFallback(String name){return "抛出异常触发的降级方法";}public String testBlockHandler(String name){return "发生熔断时触发的降级方法";}
这样就可以看到,sentinel控制台中的服务信息了
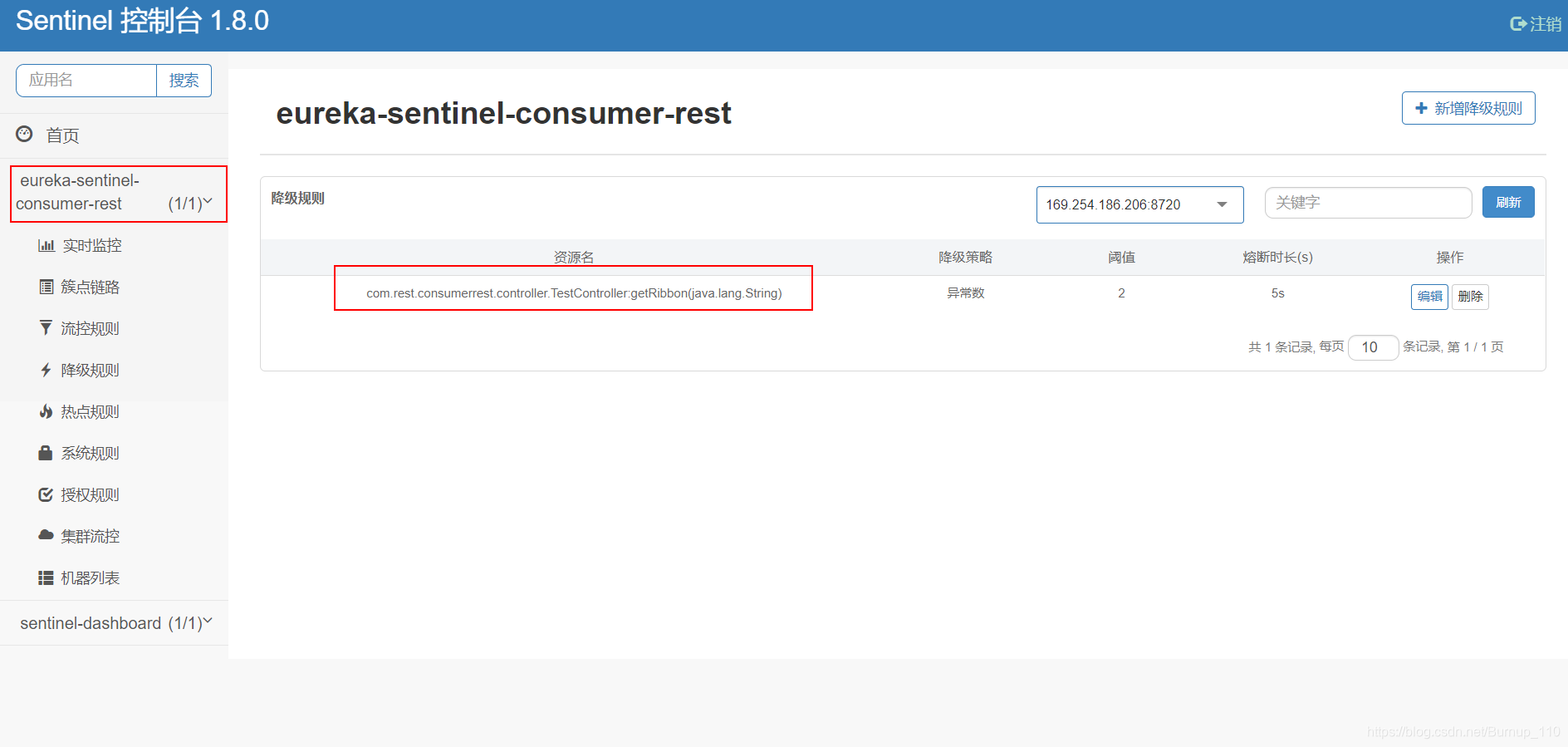
当然,sentinel默认是懒加载模式,也就是说服务启动后,需要访问一次才可以在sentinel控制台看到服务信息
6.3 加载本地配置文件
sentinel服务隔离所有的配置都可以在sentinel控制台进行配置,但是这个也会带来一个问题,就是当服务重启后,sentinel控制台中的配置信息将重置,每次都需要重新进行配置,而这就是本地配置文件将要解决的问题
我们将一些常用的配置信息,配置到本地配置文件中,当服务启动后会自动将配置信息加载到sentinel控制台中,这样就不会每次启动需要重新配置了
(1)配置properties.yml文件
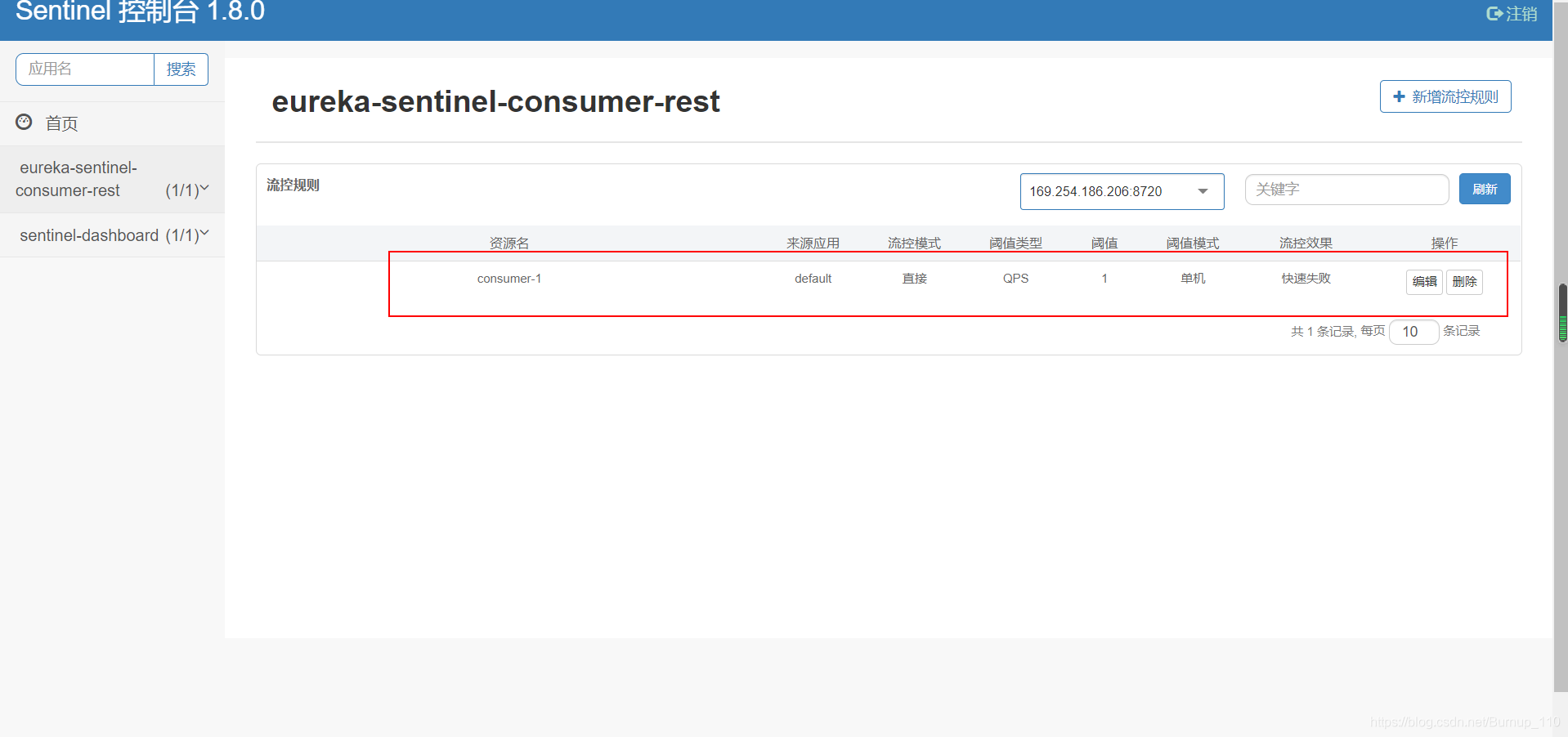
spring:cloud:sentinel:# 配置本地降级规则文件路径,当服务启动时会自动加载到sentinel控制台,文件中的参数配置可参考com.alibaba.csp.sentinel.slots.block.RuleConstantdatasource:ds1:file:file: classpath:flowrule.jsondata-type: jsonrule-type: flow
(2)配置flowrule.json文件
[{"resource": "consumer-1","controlBehavior": 0,"count": 1,"grade": 1,"limitApp": "default","strategy": 0}
]这样启动服务后就可以看到配置的限流信息了
7. 网关—zuul
Zuul 是netfix公司开发的微服务网关。
网关: 是一个网络整体系统中的前置门户入口。请求首先通过网关,进行路径的路由,定位到具体的服务节点上。
Zuul是一个微服务网关,首先是一个微服务。也是会在Eureka注册中心中进行服务的注册和发现。也是一个网关,请求应该通过Zuul来进行路由。
Zuul网关不是必要的。是推荐使用的。
使用Zuul,一般在微服务数量较多(多于10个)的时候推荐使用,对服务的管理有严格要求的时候推荐使用,当微服务权限要求严格的时候推荐使用。
7.1网关的作用
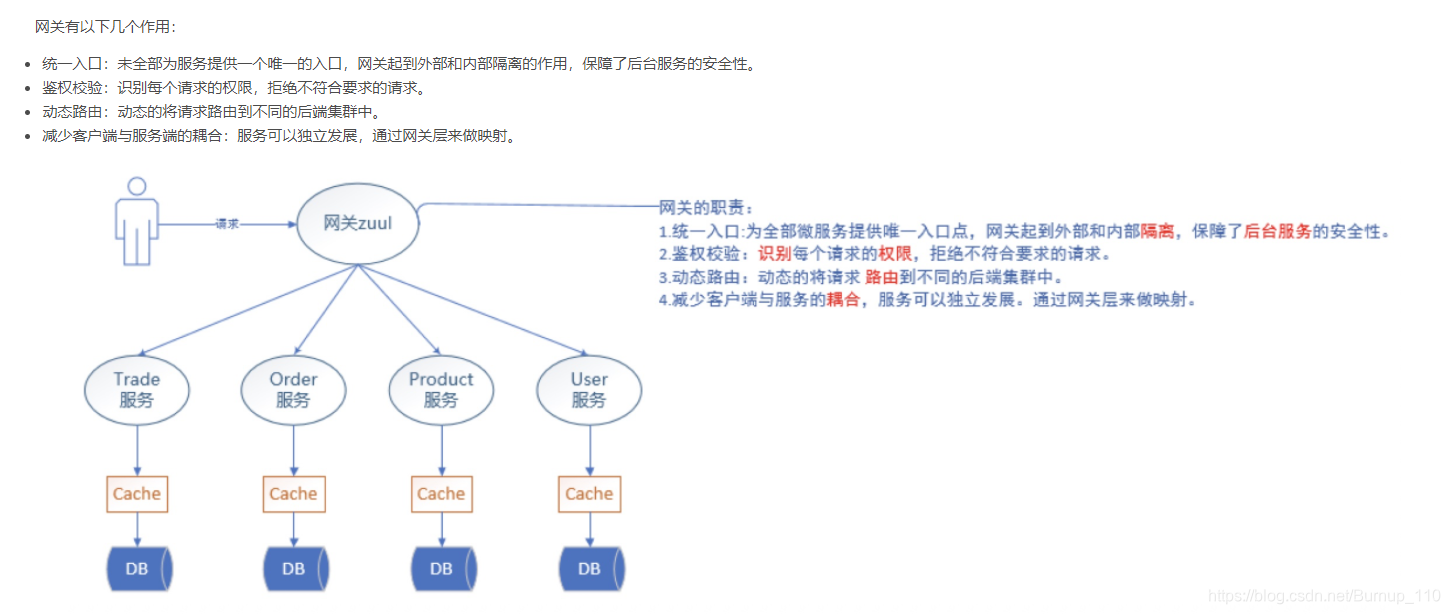
7.2 配置Zuul 环境
(1)引入相关依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-zuul</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--spring cloud ribbon 请求重试坐标--><dependency><groupId>org.springframework.retry</groupId><artifactId>spring-retry</artifactId><version>1.2.5.RELEASE</version></dependency>
(2)启动类配置
/*** @EnableZuulProxy 开启zuul路由*/
@SpringBootApplication
@EnableZuulProxy
public class ApiZuulApplication {public static void main(String[] args) {SpringApplication.run(ApiZuulApplication.class, args);}}(3)路由配置
1) url 全路径配置
# 参数key结构: zuul.routes.customName.path=xxx
# 用于配置路径匹配规则。
# 其中customName自定义。通常使用要调用的服务名称,方便后期管理
#设置zuul路由配置
zuul:routes:eureka-consumer:path: /eureka-consumer/**# url用于配置符合path的请求路径路由到的服务地址。url: http://127.0.0.1:9112
- eureka服务名配置
#设置zuul路由配置
zuul:routes:sentinel-eureka-feigh-consumer:path: /eureka-consumer/**
# url: http://127.0.0.1:9112
# serviceId用于配置符合path的请求路径路由到的服务名称。serviceId: sentinel-eureka-feigh-consumer
3)简化配置
#设置zuul路由配置
zuul:routes:sentinel-eureka-feigh-consumer: /eureka-consumer/**
# path: /eureka-consumer/**
# url: http://127.0.0.1:9112
# serviceId: sentinel-eureka-feigh-consumer
当customName和服务名一致时,可以这样设置简化配置
当然最简化的状态是不写配置,zuul默认配置成这样
zuul:routes:sentinel-eureka-feigh-consumer: /eureka-consumer/**
也就是说,当没有配置任何zuul.routes时,访问http://127.0.0.1:8080/sentinel-eureka-feigh-consumer/consumer/getFeign?name=1,默认在注册中心查找服务名为sentinel-eureka-feigh-consumer的服务,然后进行访问
7.3 Filter 过滤器
Zuul中提供了过滤器定义,可以用来过滤代理请求,提供额外功能逻辑。如:权限验证,日志记录等。
Zuul提供的过滤器是一个父类。父类是ZuulFilter。通过父类中定义的抽象方法filterType,来决定当前的Filter种类是什么。有前置过滤、路由后过滤、后置过滤、异常过滤。
- 前置过滤:是请求进入Zuul之后,立刻执行的过滤逻辑,一般进行权限校验。
- 路由后过滤:是请求进入Zuul之后,并Zuul实现了请求路由后执行的过滤逻辑,路由后过滤,是在远程服务调用之前过滤的逻辑。
- 后置过滤:远程服务调用结束后执行的过滤逻辑。
- 异常过滤:是任意一个过滤器发生异常或远程服务调用无结果反馈的时候执行的过滤逻辑。无结果反馈,就是远程服务调用超时。
继承父类ZuulFilter。在父类中提供了4个抽象方法,分别是:filterType, filterOrder, shouldFilter, run。其功能分别是:
- filterType:方法返回字符串数据,代表当前过滤器的类型。可选值有-pre, route, post, error。
pre - 前置过滤器,在请求被路由前执行,通常用于处理身份认证,日志记录等;
route - 在路由执行后,服务调用前被调用;
error - 任意一个filter发生异常的时候执行或远程服务调用没有反馈的时候执行(超时),通常用于处理异常;
post - 在route或error执行后被调用,一般用于收集服务信息,统计服务性能指标等,也可以对response结果做特殊处理。
- filterOrder:返回int数据,用于为同filterType的多个过滤器定制执行顺序,返回值越小,执行顺序越优先。
- shouldFilter:返回boolean数据,代表当前filter是否生效。
- run:具体的过滤执行逻辑。如pre类型的过滤器,可以通过对请求的验证来决定是否将请求路由到服务上;如post类型的过滤器,可以对服务响应结果做加工处理(如为每个响应增加footer数据)。
简单身份校验例子
/*** @program: springCloud* @description: 实现zuul网关过滤器,该类必须交由spring ioc容器进行管理* @create: 2020-11-09 22:19**/
@Component
public class PreFilter extends ZuulFilter {/*** 方法返回字符串数据,代表当前过滤器的类型。可选值有-pre, route, post, error。* pre - 前置过滤器,在请求被路由前执行,通常用于处理身份认证,日志记录等;* route - 在路由执行后,服务调用前被调用;* error - 任意一个filter发生异常的时候执行或远程服务调用没有反馈的时候执行(超时),通常用于处理异常;* post - 在route或error执行后被调用,一般用于收集服务信息,统计服务性能指标等,也可以对response结果做特殊处理。**/@Overridepublic String filterType() {return "pre";}/*** 返回int数据,用于为同filterType的多个过滤器定制执行顺序,返回值越小,执行顺序越优先。*/@Overridepublic int filterOrder() {return 0;}/*** shouldFilter:返回boolean数据,代表当前filter是否生效。*/@Overridepublic boolean shouldFilter() {return true;}/*** run:具体的过滤执行逻辑。如pre类型的过滤器,可以通过对请求的验证来决定是否将请求路由到服务上;如post类型的过滤器,可以对服务响应结果做加工处理(如为每个响应增加footer数据)。** RequestContext.getCurrentContext(); 获取当前Request上下文对象* requestContext.getRequest(); 获取当前请求* requestContext.setSendZuulResponse(false); 拦截请求**/@Overridepublic Object run() throws ZuulException {RequestContext requestContext = RequestContext.getCurrentContext();HttpServletRequest request = requestContext.getRequest();String token = request.getParameter("token");if (StringUtils.isEmpty(token)){requestContext.setSendZuulResponse(false);requestContext.setResponseStatusCode(HttpStatus.UNAUTHORIZED.value());}// 继续执行return null;}
}
关于zuul的一些内容整理于kosamino的博客
zuul 是早期netflix公司开发的,目前使用较少了,目前使用较多的网关组件是springCloud Gateway,因为zuul网关目前是有一些问题的
Zuul网关所面临的问题:
- 性能问题,zuul1x版本本质上就是一个同步Servlet,采用多线程阻塞模型进行请求转发,也就是说,每多一个请求,servlet容器要为该请求分配一个线程专门负责处理这个请求,直到响应返回客户端这个线程才会被释放返回容器线程池,如果后台服务调用服务比较耗时,那么这个线程就会被阻塞,阻塞期间资源被占用。线程池的数量是有限的,当前端请求数量过大,而后台慢服务较多时,很容易耗尽容器线程池内的线程,造成容器无法接受新的请求
- 不支持任何长连接,如websocket
8 SpringCloud Gateway
因为上面zuul 网关面临的种种问题,所以市面上比较流行的网关组件是 springcloud Gateway,它基本解决了上面提到的问题,在功能上做了一些扩展
多余的不说了,直接上demo吧,其他内容网上很多
8.1 Gateway 路由
(1)坐标引入
<!--gateway 依赖坐标,与mvc 冲突--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>
(2)启动类
启动类不需要添加任何多余的注解,只需要有一个springboot的注解就可以了
(3)配置文件
spring:application:name: api-gatewaycloud:gateway:routes: # 配置gateway 路由- id: eureka-consumer # 自定义的路由 ID,保持唯一即可# uri: http://127.0.0.1:9002 # 目标服务地址uri: lb://eureka-consumer # 目标服务名称,从注册中心中获取到真实ip地址predicates: # 返回一个 boolean值,为true时 路由到uri地址,路由条件- Path=/eureka-consumer/**filters: # 过滤掉path中的服务名,http://127.0.0.1:8080/eureka-consumer/consumer/getFeign?name=123 ——》 http://127.0.0.1:8080/consumer/getFeign?name=123# - StripPrefix=1 # 去掉请求路径的最前面n个部分截取掉,StripPrefix=1就代表截取路径的个数为1,比如前端过来请求/test/good/1/view,匹配成功后,路由到后端的请求路径就会变成http://localhost:8888/good/1/view- RewritePath=/eureka-consumer/(?<segment>.*),/$\{segment} # 路由重写过滤器,在yml中$写成$\discovery: # 配置自动根据服务名进行转发locator:enabled: true # 默认falselower-case-service-id: true # eureka中的服务名默认都是大写,这些配置为小写
server:port: 8080eureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/
这个配置文件中有一些基本配置,有eureka注册配置以及gateway配置,在gateway中routes中单独配置一些服务的id、路径、断言、过滤器等,可以配置多个,其中path和zuul有一些不同,配置- Path=/eureka-consumer/**,代表如果访问http://127.0.0.1:8080/eureka-consumer/provider/get/1010,他会路由到http://127.0.0.1:9002/eureka-consumer/provider/get/1010这个路径下,也就是说他会多出一个eureka-consumer的根路径,这个可以根据需要选择要不要,如果不要的话,就可以使用下边的StripPrefix、RewritePath过滤器了,两个其中哪个都可以,uri中可以配置单独ip,也可以配置从服务中心中注册的服务名,如果是服务名的话,schema协议需要是 lb://
discovery中可以配置自动根据服务名进行转发,这个和zuul类似,不过zuul是默认开启的,而gateway默认是不开启的,需要配置开启,开启后根据服务名路由到指定的路径下
有些内容借鉴于博客https://www.cnblogs.com/crazymakercircle/p/11704077.html
对了,除了Path的断言之外,Gateway还提供了其他非常丰富的断言,借图一张来阐述清晰
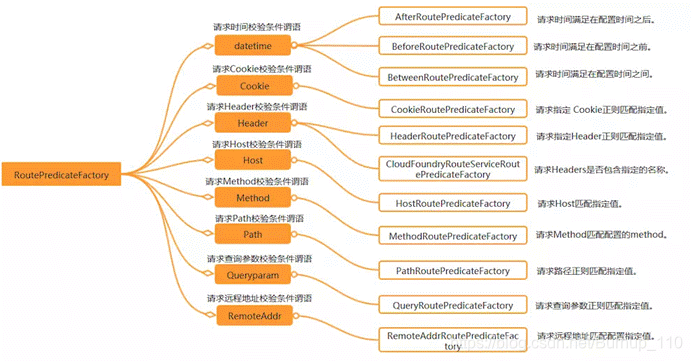
这个并没有写demo,因为基本上大同小异,感兴趣的朋友可以看下刚刚的博客
8.2 Gateway filter
Gateway中的filter和zuul中是不同的,Gateway中filter只有两种pre、post类型,并且Gateway根据作用范围划分为GatewayFilter和GlobalFilter,二者区别如下:
-
GatewayFilter : 需要通过spring.cloud.routes.filters
配置在具体路由下,只作用在当前路由上或通过spring.cloud.default-filters配置在全局,作用在所有路由上 -
GlobalFilter : 全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过GatewayFilterAdapter包装成GatewayFilterChain可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上。
因为filter主要实现一些鉴权、限流、日志输出,所以这两个中global使用的较多,因此我这里只做了Global的简单demo,和zuul的逻辑等同,主要是体现它们的实现区别
/*** @program: springCloud* @description: 测试 Gateway中GlobalFilter* @create: 2020-11-11 16:00**/
@Component
public class LoginFilter implements GlobalFilter, Ordered {/*** filter:在这个中处理过滤器的逻辑内容* ServerWebExchange:类似于zuul中RequestContext,可以获取上下文对象* GatewayFilterChain:filter 链** 以下逻辑实现 判断token是否存在,若不存在则结束路由,返回401*/@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {String token = exchange.getRequest().getQueryParams().getFirst("token");if(StringUtils.isEmpty(token)){exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);return exchange.getResponse().setComplete();}return chain.filter(exchange);}/*** filter 执行顺序,越小执行级别越高*/@Overridepublic int getOrder() {return 0;}
}
关于 Gateway filter 这篇博客写的很不错,可以看一下方志朋的博客
8.3 限流算法
学到gateway网关,那就不得不学其中的限流,学习限流之前,必须知道限流所用的算法知识,计算器算法、漏桶算法、令牌桶算法。
8.3.1 计算器算法
计算器算法是最简单的算法,顾名思义,就是记录一个时间段内 请求数是否达到阈值,如果达到阈值则拒绝、等待或降级等。
比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。那么我们可以这么做:在一开始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,
counter就加1,如果counter的值大于100并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多;
如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter。
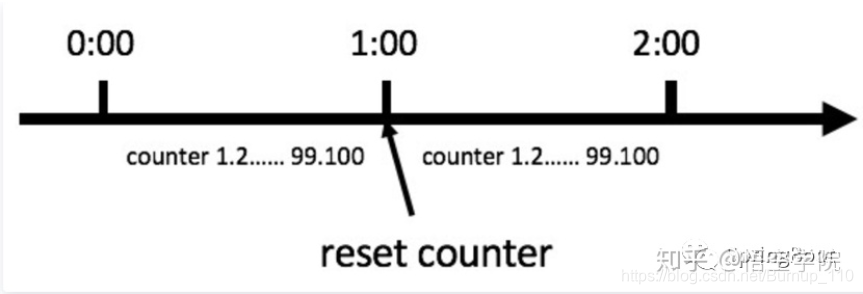
借图一张,大概就是上边的意思,我就不写算法实现了,不好误人子弟,网上也很多实现案例
简单的说一下这个算法的优缺点吧,优点很明显了,就是简单好实现,缺点也比较明显,主要是集中在两点:
(1)比如规定一分钟是一个时间段,到10秒的时候,请求数就达到了100,也就是达到了阈值,按照算法的要求,从这时候开始到一分钟对于新得到的请求都是不处理的,也就是这个时候服务是不工作的,这样相对而言服务请求就没有那么平滑,堵塞到了一起
(2)假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。我们刚才规定的是1分钟最多100个请求,也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。(借鉴于网络)
8.3.2 漏桶算法
漏桶(Leaky Bucket)算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
上边是截取自网络的一个比较官方的介绍,感觉已经很详细了,漏桶算法在高并发中是属于保护子服务的算法,但是不保护自身,也就是说在gateway网关应用于漏桶算法的话,他所调用的其他微服务会保证一个稳定的速率,保障子服务的良好运行,但是对于他本身来说的话,在高并发下,桶内堆积过多是有可能造成并发危险的,看下图
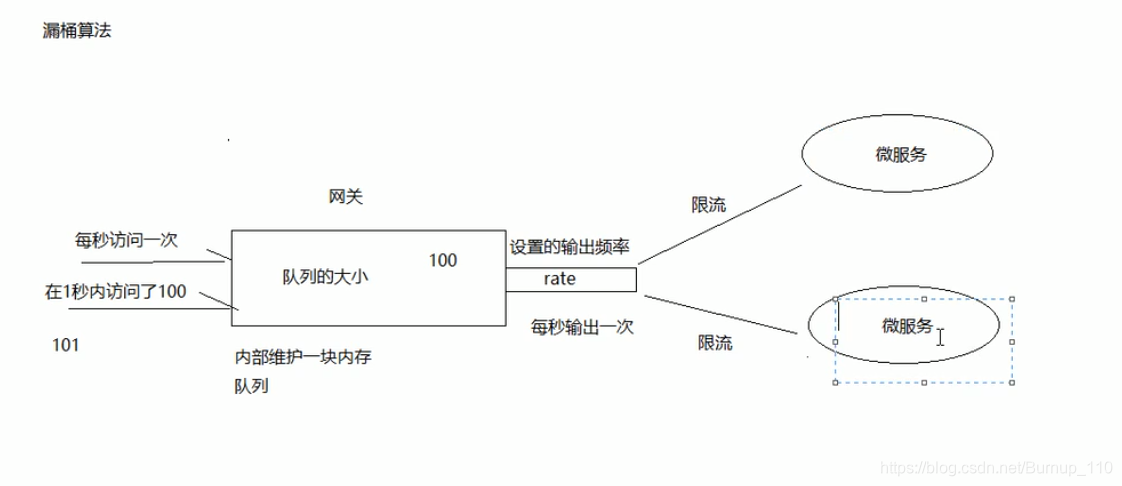
大概这个意思吧,桶内最多维持100个请求,对外每秒访问一次
8.3.3 令牌桶算法
令牌桶算法(Token Bucket)和 Leaky Bucket 效果一样但方向相反的算法,更加容易理解。随着时间流逝,系统会按恒定 1/QPS 时间间隔(如果 QPS=100,则间隔是 10ms)往桶里加入 Token(想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了。新请求来临时,会各自拿走一个 Token,如果没有 Token 可拿了就阻塞或者拒绝服务。令牌桶的另外一个好处是可以方便的改变速度。一旦需要提高速率,则按需提高放入桶中的令牌的速率。一般会定时(比如 100 毫秒)往桶中增加一定数量的令牌,有些变种算法则实时的计算应该增加的令牌的数量。
这个在我的理解中是漏桶算法的升级吧,针对的方向不同弥补了漏桶算法可能会造成当前服务宕机的缺陷,因为这个是根据token来决定是否接受请求的,如果桶中没有token则不接受请求,这样也不会给服务造成压力,因为这个不是对子服务造成限流,是根据桶内的token来算的,所以在也支持高并发的情况下的高峰请求的。
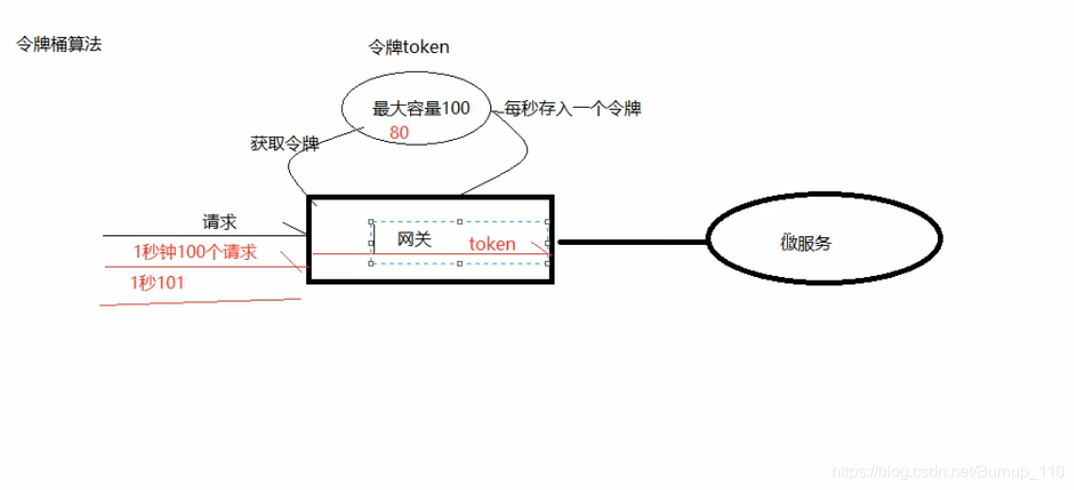
它没有对调用服务进行限流,当桶内有一百个token令牌时,这时一下子进来了一百个请求,那么他会把一百个请求转发出去,然后在根据规则每秒生成相对应的token令牌,这样既保障了高并发的高峰请求,也保障了不会将太多的请求转发出去以免造成宕机
8.4 限流-filter
在Gateway中提供了基于Toekn Bucket算法的限流支持,基于其内置的过滤器工厂RequestRateLimiterGatewayFilterFactory来实现的,在过滤器工厂中通过Redis和lua脚本结合的方式进行流量控制的。
随手记:
偶遇大佬博客,必须记下来
这篇博客对Gateway总结的很全面了,上链接https://blog.csdn.net/qq_38380025/article/details/102968559
这个限流的demo,弄到了凌晨两点,遇到了一个错误,就是关于redis有一个jar包下载不了,就是这个Cannot resolve org.springframework.data:spring-data-redis:2.3.5.RELEASE
这种很明显是spring-boot-starter-data-redis-reactive下包含的spring-data-redis 2.3.5版本下载不下来,上maven仓库也可以找到这个版本的jar包,但是就是下载不下来,因为缺少这个jar包,引发了一系列的其他错误,后来发现后修改了版本号才好了
遇到的另外一个错误是,在yml中配置了启动discovery服务发现,再配置routes的过滤器,不起作用,这个暂时没有找到解决办法,估计要看一下源码找一下冲突原因,目前只是初步学习,没必要搞这么麻烦,只要注释一个就可以了
Demo案例
(1)maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.1.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.gateway</groupId><artifactId>api-gateway</artifactId><version>0.0.1-SNAPSHOT</version><name>api-gateway</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version><spring-cloud.version>Hoxton.SR8</spring-cloud.version></properties><dependencies><!--gateway 依赖坐标,与mvc 冲突--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--redis 的监控依赖,必须要--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--redis 依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis-reactive</artifactId><!--<exclusions><exclusion><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId></exclusion></exclusions>--></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>(2)yml 配置文件
spring:application:name: api-gatewayredis:host: localhostpart: 6379database: 0password: 123cloud:gateway:discovery: # 设置服务发现,这样可以不用为每个服务配置路由,默认根据服务名来路由locator:enabled: true # 默认falselower-case-service-id: true # 服务中心中 服务名一般为大写,所以需要配置成小写default-filters:- name: RequestRateLimiter # 配置RequestRateLimiter过滤器,他是采用令牌桶算法来进行限流的args:key-resolver: '#{@keyResolver}' # key 解析器,在这个过滤器中是以redis作为桶的,需要设置一个key 解析器redis-rate-limiter.replenishRate: 1 # 每秒产生令牌的速率redis-rate-limiter.burstCapacity: 3 # 令牌桶容量
# routes: # 设置路由转发规则
# - id: eureka-consumer # 设置路由id,保证唯一性即可
# # uri: http://127.0.0.1:9002 # 具体转发的url地址
# uri: lb://eureka-consumer # 根据注册中心的服务名进行转发,scheme协议为 lb://
# predicates: # 断言,只有断言为true才会被转发,gateway内置了很多的断言规则,-Path,是根据路径进行判断,只有发送过来的路径符合/eureka-consumer/**才会被转发
# - Path=/eureka-consumer/**
# filters: # 过滤器,Gateway的过滤器根据范围分为两种,一个是GatewayFilter,一个是GlobalFilter
# # - StripPrefix=1 # StripPrefix过滤器,清除前n个路径,比如- StripPrefix=1 ==》http://127.0.0.1:8080/eureka-consumer/consumer/getFeign-》http://127.0.0.1:8080/consumer/getFeign
# - name: RequestRateLimiter
# args:
# key-resolver: '#{@keyResolver}'
# redis-rate-limiter.replenishRate: 1
# redis-rate-limiter.burstCapacity: 3
# - RewritePath=/eureka-consumer/(?<segment>.*),/$\{segment} # 路径重写过滤器,后面的值是正则表达式,功能和StripPrefix过滤器一致
server:port: 8080
eureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/
(3)配置Key 解析器
@Configuration
public class KeyResolverConfiguartion {/*** 可以定义根据Path、Param、Ip来进行限流* 根据Path限流*/
/* @Beanpublic KeyResolver keyResolver(){return new KeyResolver() {@Overridepublic Mono<String> resolve(ServerWebExchange exchange) {return Mono.just(exchange.getRequest().getPath().toString());}};}*//*** 根据Path限流*/
/* @Beanpublic KeyResolver keyResolver(){return exchange -> Mono.just(exchange.getRequest().getPath().toString());}*//*** 根据Param限流*/@Beanpublic KeyResolver keyResolver(){return exchange -> Mono.just(exchange.getRequest().getQueryParams().getFirst("token"));}}
对了,因为这个限流是基于redis的,所以需要启动redis服务
8.5 Sentinel 限流
Gatway集成Sentinel限流,从Sentinel的1.6.0版本开始,提供了SpringCloud Gateway的适配模块,可以提供两种资源维度的限流:
1、route 维度:即在Spring配置文件中配置的路由条目,资源名为对应的routeId
2、自定义 API 维度:用户可以利用 Sentinel 提供的 API 来自定义一些 API 分组
8.5.1 route维度限流
(1)依赖
<!--gateway 依赖坐标,与mvc 冲突--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--redis 的监控依赖,必须要--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--redis 依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis-reactive</artifactId><!--<exclusions><exclusion><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId></exclusion></exclusions>--></dependency><dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-spring-cloud-gateway-adapter</artifactId><version>1.7.1</version></dependency>(2)yml 配置文件
spring:application:name: api-gatewayredis:host: localhostpart: 6379database: 0password: 123cloud:gateway:
# discovery: # 设置服务发现,这样可以不用为每个服务配置路由,默认根据服务名来路由
# locator:
# enabled: true # 默认false
# lower-case-service-id: true # 服务中心中 服务名一般为大写,所以需要配置成小写
# default-filters: #全局 过滤器配置
# - name: RequestRateLimiter # 配置RequestRateLimiter过滤器,他是采用令牌桶算法来进行限流的
# args:
# key-resolver: '#{@keyResolver}' # key 解析器,在这个过滤器中是以redis作为桶的,需要设置一个key 解析器
# redis-rate-limiter.replenishRate: 1 # 每秒产生令牌的速率
# redis-rate-limiter.burstCapacity: 3 # 令牌桶容量routes: # 设置路由转发规则- id: eureka-consumer # 设置路由id,保证唯一性即可# uri: http://127.0.0.1:9002 # 具体转发的url地址uri: lb://eureka-consumer # 根据注册中心的服务名进行转发,scheme协议为 lb://predicates: # 断言,只有断言为true才会被转发,gateway内置了很多的断言规则,-Path,是根据路径进行判断,只有发送过来的路径符合/eureka-consumer/**才会被转发- Path=/eureka-consumer/**filters: # 过滤器,Gateway的过滤器根据范围分为两种,一个是GatewayFilter,一个是GlobalFilter# - StripPrefix=1 # StripPrefix过滤器,清除前n个路径,比如- StripPrefix=1 ==》http://127.0.0.1:8080/eureka-consumer/consumer/getFeign-》http://127.0.0.1:8080/consumer/getFeign
# - name: RequestRateLimiter
# args:
# key-resolver: '#{@keyResolver}'
# redis-rate-limiter.replenishRate: 1
# redis-rate-limiter.burstCapacity: 3- RewritePath=/eureka-consumer/(?<segment>.*),/$\{segment} # 路径重写过滤器,后面的值是正则表达式,功能和StripPrefix过滤器一致
server:port: 8080
eureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/
(3)配置类
@Configuration
public class SentinelConfiguration {private final List<ViewResolver> viewResolvers;private final ServerCodecConfigurer serverCodecConfigurer;public SentinelConfiguration(ObjectProvider<List<ViewResolver>> viewResolversProvider,ServerCodecConfigurer serverCodecConfigurer) {this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList);this.serverCodecConfigurer = serverCodecConfigurer;}/*** 注册异常处理器*/@Bean@Order(Ordered.HIGHEST_PRECEDENCE)public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {// Register the block exception handler for Spring Cloud Gateway.return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer);}/*** 将sentinel过滤器加入到全局过滤器链中*/@Bean@Order(Ordered.HIGHEST_PRECEDENCE)public GlobalFilter sentinelGatewayFilter() {return new SentinelGatewayFilter();}/*** @PostConstruct:初始化执行此方法*/@PostConstructpublic void doInit() {initGatewayRules();initBlockHandler();
// initCustomizeApis();}/*** 初始化限流规则*/private void initGatewayRules() {/*GatewayFlowRule:网关限流规则,针对 API Gateway 的场景定制的限流规则,可以针对不同 route 或自定义的 API 分组进行限流,支持针对请求中的参数、Header、来源 IP 等进行定制化的限流。*/Set<GatewayFlowRule> rules = new HashSet<>();/*设置限流规则resource: 资源名称,这里为路由router的IDresourceMode: 路由模式count: QPS即每秒钟允许的调用次数intervalSec: 每隔多少时间统计一次汇总数据,统计时间窗口,单位是秒,默认是 1 秒。*/rules.add(new GatewayFlowRule("eureka-consumer").setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_ROUTE_ID).setCount(1).setIntervalSec(1));
// rules.add(new GatewayFlowRule("eureka-consumer")
// .setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_CUSTOM_API_NAME)
// .setCount(1).setIntervalSec(1));
// rules.add(new GatewayFlowRule("eureka-provider")
// .setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_CUSTOM_API_NAME)
// .setCount(1).setIntervalSec(1));/*** 配置gateway rule 规则*/GatewayRuleManager.loadRules(rules);}/*** 自定义API限流分组* 1.定义分组* 2.对小组配置限流规则*/private void initCustomizeApis(){Set<ApiDefinition> definitions = new HashSet<>();// 匹配/eureka-consumer/ 开头的所有urlApiDefinition apiDefinition1 = new ApiDefinition("eureka-consumer").setPredicateItems(new HashSet<ApiPredicateItem>(){{add(new ApiPathPredicateItem().setPattern("/eureka-consumer/**").setMatchStrategy(SentinelGatewayConstants.URL_MATCH_STRATEGY_PREFIX));}});// 完全匹配/eureka-provider/provider/get/1ApiDefinition apiDefinition = new ApiDefinition("eureka-provider").setPredicateItems(new HashSet<ApiPredicateItem>(){{add(new ApiPathPredicateItem().setPattern("/eureka-provider/provider/get/1"));}});definitions.add(apiDefinition);definitions.add(apiDefinition1);GatewayApiDefinitionManager.loadApiDefinitions(definitions);}/*** 自定义限流异常处理* ResultSupport 为自定义的消息封装类,代码略*/
// private void initBlockHandler() {
// GatewayCallbackManager.setBlockHandler(new BlockRequestHandler() {
// @Override
// public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange,
// Throwable throwable) {
// Map<String,String> map = new HashMap<>();
// map.put("code","1400");
// map.put("message","Sentinel block");
// return ServerResponse.status(HttpStatus.OK)
// .contentType(MediaType.APPLICATION_JSON_UTF8)
// .body(BodyInserters.fromObject(map));
// }
// });
// }/*** 限流提示信息*/private void initBlockHandler() {GatewayCallbackManager.setBlockHandler((serverWebExchange,throwable)->{Map<String,String> map = new HashMap<>();map.put("code","1400");map.put("message","Sentinel block");return ServerResponse.status(HttpStatus.OK).contentType(MediaType.APPLICATION_JSON_UTF8).body(BodyInserters.fromObject(map));});}
}
8.5.2 自定义分组限流
(1)pom 依赖
与上面保持一致
(2)yml配置文件
spring:application:name: api-gatewayredis:host: localhostpart: 6379database: 0password: 123cloud:gateway:discovery: # 设置服务发现,这样可以不用为每个服务配置路由,默认根据服务名来路由locator:enabled: true # 默认falselower-case-service-id: true # 服务中心中 服务名一般为大写,所以需要配置成小写
# default-filters: #全局 过滤器配置
# - name: RequestRateLimiter # 配置RequestRateLimiter过滤器,他是采用令牌桶算法来进行限流的
# args:
# key-resolver: '#{@keyResolver}' # key 解析器,在这个过滤器中是以redis作为桶的,需要设置一个key 解析器
# redis-rate-limiter.replenishRate: 1 # 每秒产生令牌的速率
# redis-rate-limiter.burstCapacity: 3 # 令牌桶容量
# routes: # 设置路由转发规则
# - id: eureka-consumer # 设置路由id,保证唯一性即可
# # uri: http://127.0.0.1:9002 # 具体转发的url地址
# uri: lb://eureka-consumer # 根据注册中心的服务名进行转发,scheme协议为 lb://
# predicates: # 断言,只有断言为true才会被转发,gateway内置了很多的断言规则,-Path,是根据路径进行判断,只有发送过来的路径符合/eureka-consumer/**才会被转发
# - Path=/eureka-consumer/**
# filters: # 过滤器,Gateway的过滤器根据范围分为两种,一个是GatewayFilter,一个是GlobalFilter
# # - StripPrefix=1 # StripPrefix过滤器,清除前n个路径,比如- StripPrefix=1 ==》http://127.0.0.1:8080/eureka-consumer/consumer/getFeign-》http://127.0.0.1:8080/consumer/getFeign
## - name: RequestRateLimiter
## args:
## key-resolver: '#{@keyResolver}'
## redis-rate-limiter.replenishRate: 1
## redis-rate-limiter.burstCapacity: 3
# - RewritePath=/eureka-consumer/(?<segment>.*),/$\{segment} # 路径重写过滤器,后面的值是正则表达式,功能和StripPrefix过滤器一致
server:port: 8080
eureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/
(3)配置类
@Configuration
public class SentinelConfiguration {private final List<ViewResolver> viewResolvers;private final ServerCodecConfigurer serverCodecConfigurer;public SentinelConfiguration(ObjectProvider<List<ViewResolver>> viewResolversProvider,ServerCodecConfigurer serverCodecConfigurer) {this.viewResolvers = viewResolversProvider.getIfAvailable(Collections::emptyList);this.serverCodecConfigurer = serverCodecConfigurer;}/*** 注册异常处理器*/@Bean@Order(Ordered.HIGHEST_PRECEDENCE)public SentinelGatewayBlockExceptionHandler sentinelGatewayBlockExceptionHandler() {// Register the block exception handler for Spring Cloud Gateway.return new SentinelGatewayBlockExceptionHandler(viewResolvers, serverCodecConfigurer);}/*** 将sentinel过滤器加入到全局过滤器链中*/@Bean@Order(Ordered.HIGHEST_PRECEDENCE)public GlobalFilter sentinelGatewayFilter() {return new SentinelGatewayFilter();}/*** @PostConstruct:初始化执行此方法*/@PostConstructpublic void doInit() {initGatewayRules();initBlockHandler();initCustomizeApis();}/*** 初始化限流规则*/private void initGatewayRules() {/*GatewayFlowRule:网关限流规则,针对 API Gateway 的场景定制的限流规则,可以针对不同 route 或自定义的 API 分组进行限流,支持针对请求中的参数、Header、来源 IP 等进行定制化的限流。*/Set<GatewayFlowRule> rules = new HashSet<>();/*设置限流规则resource: 资源名称,这里为路由router的IDresourceMode: 路由模式count: QPS即每秒钟允许的调用次数intervalSec: 每隔多少时间统计一次汇总数据,统计时间窗口,单位是秒,默认是 1 秒。*/
// rules.add(new GatewayFlowRule("eureka-consumer")
// .setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_ROUTE_ID)
// .setCount(1).setIntervalSec(1));rules.add(new GatewayFlowRule("eureka-consumer").setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_CUSTOM_API_NAME).setCount(1).setIntervalSec(1));rules.add(new GatewayFlowRule("eureka-provider").setResourceMode(SentinelGatewayConstants.RESOURCE_MODE_CUSTOM_API_NAME).setCount(1).setIntervalSec(1));/*** 配置gateway rule 规则*/GatewayRuleManager.loadRules(rules);}/*** 自定义API限流分组* 1.定义分组* 2.对小组配置限流规则*/private void initCustomizeApis(){Set<ApiDefinition> definitions = new HashSet<>();// 匹配/eureka-consumer/ 开头的所有urlApiDefinition apiDefinition1 = new ApiDefinition("eureka-consumer").setPredicateItems(new HashSet<ApiPredicateItem>(){{add(new ApiPathPredicateItem().setPattern("/eureka-consumer/**").setMatchStrategy(SentinelGatewayConstants.URL_MATCH_STRATEGY_PREFIX));}});// 完全匹配/eureka-provider/provider/get/1ApiDefinition apiDefinition = new ApiDefinition("eureka-provider").setPredicateItems(new HashSet<ApiPredicateItem>(){{add(new ApiPathPredicateItem().setPattern("/eureka-provider/provider/get/1"));}});definitions.add(apiDefinition);definitions.add(apiDefinition1);GatewayApiDefinitionManager.loadApiDefinitions(definitions);}/*** 自定义限流异常处理* ResultSupport 为自定义的消息封装类,代码略*/
// private void initBlockHandler() {
// GatewayCallbackManager.setBlockHandler(new BlockRequestHandler() {
// @Override
// public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange,
// Throwable throwable) {
// Map<String,String> map = new HashMap<>();
// map.put("code","1400");
// map.put("message","Sentinel block");
// return ServerResponse.status(HttpStatus.OK)
// .contentType(MediaType.APPLICATION_JSON_UTF8)
// .body(BodyInserters.fromObject(map));
// }
// });
// }/*** 限流提示信息*/private void initBlockHandler() {GatewayCallbackManager.setBlockHandler((serverWebExchange,throwable)->{Map<String,String> map = new HashMap<>();map.put("code","1400");map.put("message","Sentinel block");return ServerResponse.status(HttpStatus.OK).contentType(MediaType.APPLICATION_JSON_UTF8).body(BodyInserters.fromObject(map));});}
}
这两个中一个是根据routeId来定义限流,一个是根据自定义的分组名称来定义限流,这两个只是根据划分区间有所不同,其他没有区别
但是在完成这个demo的过程中,我发现当我开启了spring.cloud.discovery.locator.enabled=true后,在spring.cloud.routes下设置的配置就不起作用了,这个暂时没有找到冲突的问题点在哪里,所以只能在使用routeID的地方启用routes配置,在其他地方启用discovery服务发现配置,这样更方便点。
大神路过,请不吝赐教,解决一下这个问题
这篇博客,写的比较详细,但是自我感觉有点乱,读懂要花费时间,以后在研究,先贴在这里
https://blog.csdn.net/fouse_/article/details/106073597
一一一一一一
8.6 Gateway 网关高可用+ ngnix
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
关于这个高可用,我就不重复写了,需要的可以直接看这个博客springCloudGateway-网关高可用
不过在写这个demo的过程中,我不可抑制的产生了一个疑惑,为了实现网关高可用,需要实现网关集群化,为了保障对外接口唯一性,在网关和客户端之间加了一个nginx服务器,实现客户端统一接口调用,那么问题来了,nginx的高可用如何保障?如果nginx服务是唯一的,那么nginx服务宕了,一样会造成整个服务的瘫痪。
这个问题,我没有弄明白,如果有大佬路过,请不吝赐教
9 链路追踪
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。
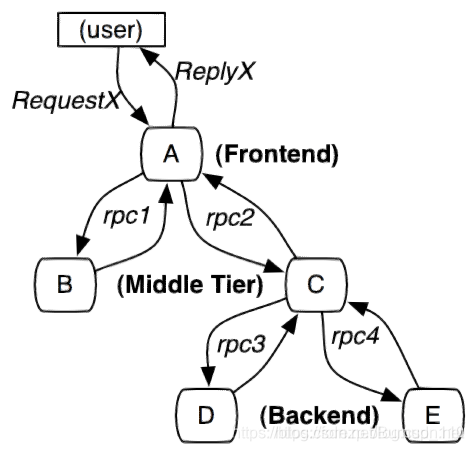
随着服务的越来越多,对调用链的分析会越来越复杂。它们之间的调用关系也许如下:

在这里,我的理解很简单,就是在微服务架构中,随着服务节点的增多,完成一个复杂的请求所要经过的节点也越来越多,这种情况下,很难去记录整个请求所经过的日志等其他情况,所以在这里引入了链路追踪的概念,相对应的组件是springcloud sleuth,但是在sleuth中只是记录了各个节点的信息,并没有非常友好的展示出来,这种情况,需要配合Twitter公司开发的组件zipkin,使用它对链路追踪的信息进行友好的存储、展示等
9.1 SpringCloud Sleuth
Sleuth中有两个非常重要的概念,spanID和traceID,我对此不敢说很清晰,就不强做解释了,关于链路追踪的内容,大部分参考与这方志朋的博客,有兴趣可以看一下,当然最好看git上的官方解释,我对这篇博客的定义就是会用,理解流程即可
好了,不多说了,上demo
官方文档
(1)引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><version>2.0.1.RELEASE</version></dependency>
(2)yml配置
# 配置 路由追踪日志打印
logging:level:root: infoorg.springframework.web.servlet.DispatcherServlet: debugorg.springframework.cloud.sleuth: debug
以上两个在需要的节点,配置上就可以看到追踪的链路信息了

比如这个,就是我刚刚打印出来的,主要介绍一下这几个参数
[eureka-consumer,db64eaa8fd5fa12f,6c47847505ef837f,true]
eureka-consumer:当前节点的spring application,name的值
db64eaa8fd5fa12f:sleuth生成的一个工D,叫 TraceID,用来标识一条请求链路,一条请求链路中包含一个 TraceID,多个SpanID
6c47847505ef837f:spanid基本的工作单元,获取元数据,如发送一个http
true:是否要将该信息输出到 zipkin服务中来收集和展示
也就是说结构是这样的:【applicationName,TraceID,SpanID,boolean】
9.2 zipkin
刚刚已经有介绍了,我认为就和hystrix的actuator组件一样,都是为了更好地整理收集信息而设计的组件,这个zipkin也一样如此,不过它除了支持收集信息以web ui的形式展示,还支持异步传输、持久化追踪信息等功能,功能还是非常全面的。
而且目前zipkin已经不需要建立一个服务去启用了,直接就可以 下载jar包,然后启动,这样就可以使用了
下载jar包地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
启动命令:java -jar zipkin-server-2.10.1-exec.jar
web ui : http://127.0.0.1:9411/
基本的demo
(1)依赖引入
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId><version>2.0.1.RELEASE</version></dependency>
(2)yml配置文件
zipkin:base-url: http://127.0.0.1:9411sender:type: web #数据的传输方式,以http的形式向server端发送数据sleuth:sampler:probability: 1 # 采样比,1是完全采样
这样就可以了,就可以在http://127.0.0.1:9411/zipkin/查看自己的链路信息了,当然了,前提是你要请求一下要不然也不会有链路信息,比如:
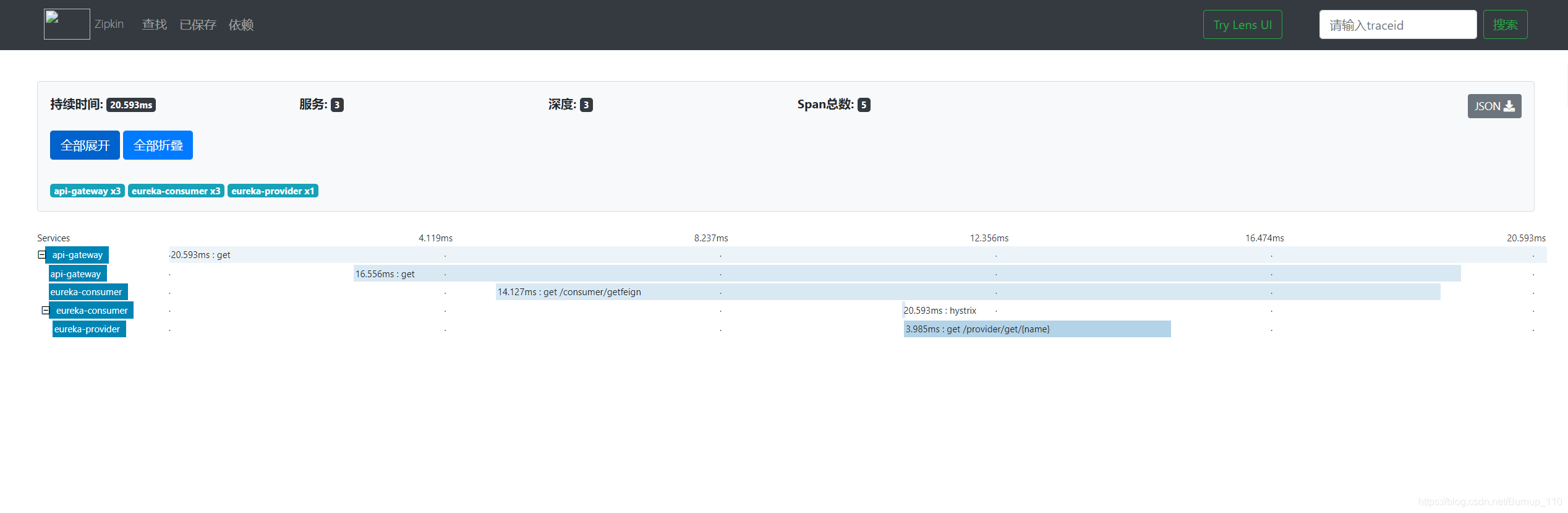
cloud 的组件都是非常简单的,除非深入研究实现过程。当然上边的这个例子,很明显并不能持久化,也没有使用消息中间件,这样的话,当zipkin服务宕机了,那么所有存储在内存中的链路信息都没了,而且默认是使用http进行传输,我们也知道http请求占用的资源也是较多的,我们最好能做到持久化和使用消息中间件,实现异步传输,这个看下边的例子
持久化-消息中间件
demo案例
(1)依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId><version>2.0.1.RELEASE</version></dependency><dependency><groupId>org.springframework.amqp</groupId><artifactId>spring-rabbit</artifactId></dependency>
(2)yml配置文件
spring:zipkin:#base-url: http://127.0.0.1:9411base-url: http://127.0.0.1:5672sender:#type: web #数据的传输方式,以http的形式向server端发送数据type: rabbit # 以rabbitmq的方式来实现异步传输sleuth:sampler:probability: 1 # 采样比,1是完全采样rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guestlistener: #设置请求重试策略direct:retry:enabled: truesimple:retry:enabled: true
zipkin持久化的话,还需要建立一个zipkin的数据库,sql如下
CREATE DATABASE `zipkin`;USE `zipkin`;CREATE TABLE IF NOT EXISTS zipkin_spans (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL,`id` BIGINT NOT NULL,`name` VARCHAR(255) NOT NULL,`parent_id` BIGINT,`debug` BIT(1),`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';CREATE TABLE IF NOT EXISTS zipkin_annotations (`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';CREATE TABLE IF NOT EXISTS zipkin_dependencies (`day` DATE NOT NULL,`parent` VARCHAR(255) NOT NULL,`child` VARCHAR(255) NOT NULL,`call_count` BIGINT,`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);启动 zipkin命令如下
java -jar zipkin-server-2.12.6-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=123 --MYSQL_DB=zipkin --RABBIT_ADDRESSES=127.0.0.1:5672
命令含义:
–STORAGE_TYPE:数据库类型
–MYSQL_HOST:数据库地址
–MYSQL_TCP_PORT:数据库端口号
–MYSQL_USER:数据库用户名
–MYSQL_PASS:数据库密码
–MYSQL_DB:数据库名
–RABBIT_ADDRESSES:Rabbitmq地址
大概就这些意思,当然因为我的Rabbitmq都是采用的默认用户名和密码,所以就没有重复写了,如果有朋友改过用户名和密码,那么需要调整一下启动参数
这样就可以了,可以在数据库中看到持久化的信息,如果zipkin宕机了,那么也不会丢失链路信息,因为信息传到了Rabbitmq中,当zipkin重新启动后,就会再次收到消息,这样不会丢失信息,这是中间件的特性
10 SpringCloud Stream
Stream组件主要是为了消除具体项目中存在的消息中间件差异而存在的,在大型项目中消息中间件不可避免的会被使用,因为它可以做到应用解耦、异步消息、流量削峰等,实现高性能、高可用、可伸缩和高度一致性架构。但是市面上有多种消息中间件,比如activemq、Rabbitmq、kafka,他们的结构是不一样的,这样也代表了针对不同的消息中间件实现的代码是不同的,但是遇到更换消息中间件的情况,那对于项目来说就是一个很大的工程,但是如果使用了Stream的话,对于Stream进行消息中间件操作,再用Stream去调用中间件,这样对于我们来说不管是什么中间件,使用的方式都是一样的,这样的话,更换中间件或者其他的操作只是简单的配置一下参数的问题了
简单Demo
(1)依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-stream</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-rabbit</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-stream-binder-rabbit</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version><scope>compile</scope></dependency>
(2)yml配置文件
提供者:
server:port: 11002
spring:application:name: stream-providerrabbitmq:addresses: 127.0.0.1port: 5672cloud:stream:binders: # 配置绑定器defaultRabbit:type: rabbitbindings:output:destination: stream # 配置消息发送的exchange
消费者:
server:port: 11001
spring:application:name: stream-consumerrabbitmq:addresses: 127.0.0.1port: 5672cloud:stream:binders: # 配置绑定器defaultRabbit:type: rabbitbindings:input:destination: stream # 配置消息发送的exchange
(3)消息工具类
提供者:
/*** @program: springCloud* @description: 实现消息中间件工具类* 使用stream实现消息中间消费消息,必须定义个channel,stream内置了一个channel,可以直接使用它,也可以自定义一个channel* @EnableBinding: 绑定通道* MessageChannel: Source内置的发送消息的通道,可以使用它进行消息发送* @create: 2020-11-15 11:31**/
@Slf4j
@Component
@EnableBinding(Source.class)
public class MessageUtil {@Autowiredprivate MessageChannel output;public void output(){log.info("Stream send start");output.send(MessageBuilder.withPayload("Hello Word!!").build());log.info("Stream send end");}}
消费者:
/*** @program: springCloud* @description: 实现消息中间件工具类* 使用stream实现消息中间消费消息,必须定义个channel,stream内置了一个channel,可以直接使用它,也可以自定义一个channel* @EnableBinding: 绑定通道* @StreamListener:添加监听器* @create: 2020-11-15 11:31**/
@Slf4j
@Component
@EnableBinding(Sink.class)
public class MessageUtil {@StreamListener(Sink.INPUT)public void input(Object obj){log.info("Stream start");System.out.println("Stream 接受的信息:"+ JSON.toJSONString(obj));log.info("Stream end");}}
这样就可以提动消息消费者,然后利用Junit在提供者方发送消息,然后查看消费者是否接受到消息
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class MessageUtilTest { @Autowiredprivate MessageUtil messageUtil;@Testpublic void testOutput() throws Exception {messageUtil.output();}} 这样一个简单的Rabbitmq+Stream就完成了,完全消除了关于消息中间件的差异。但是这个简单的Demo我们也可以看到关于通道我们并不是只可以使用内置的input、output,我们也可以自定义一个通道,然后因为这个是发布-订阅的一个结构,所以当我们provider发送一条消息后,所有订阅的consumer都会收到消息,有时候我们是不希望这样的,比如分布式服务,有多个相同的节点,我们往往只希望一个节点接受到消息并进行处理,而不希望多个节点重复处理;另外当我们发送一些特殊的消息时我们希望特定的节点去处理。关于这三个问题,在Stream中有相应的解决方式,如自定义通道、分区、分组
下面这个demo主要就是解决上面所提到的问题
关于分组、分区、自定义消息通道Demo
(1)依赖保持一致
(2)yml配置文件
Consumer-1
server:port: 11001
spring:application:name: stream-consumerrabbitmq:addresses: 127.0.0.1port: 5672cloud:stream:instance-count: 2 # 消费者总数instance-index: 0 # 当前消费者的索引,没有弄懂这个匹配规则是什么样的binders: # 配置绑定器defaultRabbit:type: rabbitbindings:input:destination: stream # 配置消息发送的exchangegroup: group1consumer:partitioned: true # 开启消费者分区配置custom_input: # 自定义消息通道destination: stream-customgroup: group1 #设置消息的组名称,同一个消息分组,只会有一个consumer去消费信息
Consumer-2
server:port: 11011
spring:application:name: stream-consumerrabbitmq:addresses: 127.0.0.1port: 5672cloud:stream:instance-count: 2 # 消费者总数instance-index: 1 # 当前消费者的索引,没有弄懂这个匹配规则是什么样的binders: # 配置绑定器defaultRabbit:type: rabbitbindings:input:destination: stream # 配置消息发送的exchangegroup: group1consumer:partitioned: true # 开启消费者分区配置custom_input: # 自定义消息通道destination: stream-customgroup: group1 #设置消息的组名称,同一个消息分组,只会有一个consumer去消费信息
Provider
server:port: 11002
spring:application:name: stream-providerrabbitmq:addresses: 127.0.0.1port: 5672cloud:stream:binders: # 配置绑定器defaultRabbit:type: rabbitbindings:output:destination: stream # 配置消息发送的exchangeproducer:partitionKeyExpression: payload # 分区关键字,可以设置根据对象某个特征进行分区,如id,name等;payload是字符串全部匹配partitionCount: 2 # 消费者大小custom_output: # 自定义消息通道destination: stream-custom
(3) 工具类及自定义通道
Provider
/*** @program: springCloud* @description: 自定义消息通道* @create: 2020-11-15 12:33**/public interface CustomChannel {String CUSTOM_OUTPUT = "custom_output";String CUSTOM_INPUT = "custom_input";@Output("custom_output")MessageChannel cusOutput();@Input("custom_input")SubscribableChannel cutInput();
}
/*** @program: springCloud* @description: 实现消息中间件工具类* 使用stream实现消息中间消费消息,必须定义个channel,stream内置了一个channel,可以直接使用它,也可以自定义一个channel* @EnableBinding: 绑定通道* MessageChannel: Source内置的发送消息的通道,可以使用它进行消息发送* @create: 2020-11-15 11:31**/
@Slf4j
@Component
@EnableBinding({Source.class,CustomChannel.class})
public class MessageUtil {@Autowired@Qualifier(value = "output")private MessageChannel output;@Autowired@Qualifier(value = "custom_output")private MessageChannel cusOutput;public void output(String index){log.info("Stream send start");output.send(MessageBuilder.withPayload("Hello Word!! output").build());log.info("Stream send end");}public void cusOutput(String index){log.info("Stream send start");cusOutput.send(MessageBuilder.withPayload("Hello Word!! cusOutput "+index).build());log.info("Stream send end");}/*** 分区测试*/public void partition(String index){log.info("Stream send start");output.send(MessageBuilder.withPayload(index).build());log.info("Stream send end");}}
Consumer
/*** @program: springCloud* @description: 自定义消息通道* @author: hs* @create: 2020-11-15 12:33**/public interface CustomChannel {String CUSTOM_OUTPUT = "custom_output";String CUSTOM_INPUT = "custom_input";@Output("custom_output")MessageChannel cusOutput();@Input("custom_input")SubscribableChannel cutInput();
}/*** @program: springCloud* @description: 实现消息中间件工具类* 使用stream实现消息中间消费消息,必须定义个channel,stream内置了一个channel,可以直接使用它,也可以自定义一个channel* @EnableBinding: 绑定通道* @StreamListener:添加监听器* @create: 2020-11-15 11:31**/
@Slf4j
@Component
@EnableBinding({Sink.class,CustomChannel.class})
public class MessageUtil {@StreamListener(Sink.INPUT)public void input(String message){log.info("Stream start");System.out.println("Stream 接受的信息:"+ message);log.info("Stream end");}@StreamListener(CustomChannel.CUSTOM_INPUT)public void custom_input(String message){log.info("Stream start");System.out.println("Stream 接受的信息:"+ message);log.info("Stream end");}}
Provider Test测试类
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class MessageUtilTest { @Autowiredprivate MessageUtil messageUtil;@Testpublic void testOutput() throws Exception {
// messageUtil.output();for (int i=0;i<10;i++){messageUtil.cusOutput(i+"");}}@Testpublic void partition() throws Exception {for (int i=0;i<5;i++){messageUtil.partition("25487");}}}
自定义消息通道很简单,只需要重写一个类似的消息通道就可以了;
消息分组也是比较简单的,只需要加上一个配置就可以了,保证同组的节点组名相同即可;
消息分区是为了防止同一个消息被多个节点消费,比如一条用户信息,分成多个消息段发送,这个很明显不希望被多个节点消费,只希望一个节点消费,这时候就可以使用分区了,但是有一点我没理解,就是当分区的时候,如果指定一些特殊消息到一些特殊节点,这个应该和partitionKeyExpression这个配置有关,但是目前不知道如何处理。以后处理吧
11 配置中心
对于单体应用而言,常使用配置文件来管理所有的配置,比如springboot的application.properties文件,但是在微服务架构中全部手动修改的话很麻烦而且不易维护,微服务的配置管理一般有以下的需求:
- 集中配置管理,一个微服务架构中可能有成百上千个微服务,所以集中配置管理是很重要的。
- 不同的环境不同配置,比如数据源配置在不同的环境中是不同的
- 运行期间可以动态调整配置
- 配置修改后可自动更新,例如配置内容发生了变化,微服务可以自动更新配置,也就是所说的热启动
以上所述,一个微服务中配置中心组件就非常重要了
11.1 SpringCloud Config
Spring Cloud Config项目是一个解决分布式系统的配置管理方案。它包含了Client和Server两个部分,server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,client通过接口获取数据、并依据此数据初始化自己的应用。
Conifg是一个这样的结构
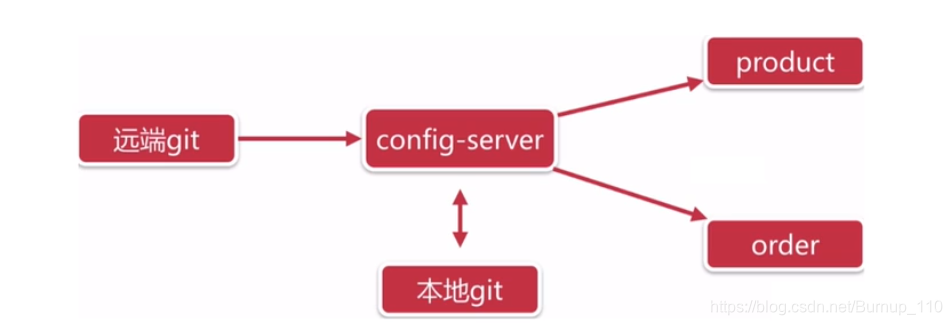
它是将配置文件存放在远程的git中,这个远程git可以选择自己搭建一个git服务,当然也可以使用GitHub、gitee,我使用的是gitee,然后config-server服务器从gitee中获取到相应的配置文件存储到内存中,其他节点再从config server中获取到配置信息
下面写一个简单的demo
Server端:
(1)先看一下我的gitee的内容
其实就是新建了一个项目,然后在里边存储了一个application-dev.yml配置文件,这样就可以了
(2)引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-config-server</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId></dependency>
(3)配置文件
server:port: 15000
spring:application:name: config-servercloud:config:server:git:uri: https://gitee.com/heshuai_mayun/config_-server_-repo.git
# search-paths: # git仓库地址下的相对地址 多个用逗号","分割。
# username: #仓库的账号
# password: # git仓库的密码。eureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/ # ,http://127.0.0.1:8000/eureka/# register-with-eureka: false- spring.cloud.config.server.git.uri: 配置的Git仓库的地址。
- spring.cloud.config.server.git.search-paths: git仓库地址下的相对地址 多个用逗号","分割。
- spring.cloud.config.server.git.username:git仓库的账号。
- spring.cloud.config.server.git.password:git仓库的密码。
因为这个是个公开的仓库,所以也不需要设置账号密码,相对路径也不需要
(4) 启动类
/*** @EnableConfigServer : 启动config server*/
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {public static void main(String[] args) {SpringApplication.run(ConfigServerApplication.class, args);}}
client端:
(1)引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
(2)配置文件
建立一个bootstrap.yml文件,并不是application.yml文件,因为我们需要将大多数配置信息放到config server中,所以需要建立bootstrap.yml文件,当项目启动的时候,bootstrap.yml比application.yml的优先级要高,会优先加载bootstrap.yml文件,所以这时侯可以将配置信息加载进来,大概就是这个意思
spring:cloud:config:name: application # 配置文件的名称。profile: dev # 配置的策略。label: master # 配置文件的分支,默认是master。如果是是本地获取的话,则无用。
# uri: http://127.0.0.1:15000 # 配置配置中心服务端地址discovery:enabled: true #从注册中心中发现配置中心信息serviceId: config-server # 指定注册中心中配置中心的service-id,以便配置高可用集群# 开启动态刷新请求路径断点
management:endpoints:web:exposure:include: refresheureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/ # ,http://127.0.0.1:8000/eureka/(3)在需要动态配置的类上边添加@RefreshScope 注解,比如下边这个类
package com.eureka.client.consumer.controller;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.servlet.DispatcherServlet;import java.util.List;/*** @program: springCloud* @description: 测试消费者控制层* @create: 2020-10-10 09:32**/
@RestController
@RequestMapping("consumer")
@RefreshScope // 开启动态配置
public class TestController {private final Logger logger= LoggerFactory.getLogger(TestController.class);@Autowiredprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;@Value("${name}")private String name;@Autowiredprivate EurekaConsumerFeign eurekaConsumerFeign;@GetMapping("getFeign")public String getFeign(String name){return eurekaConsumerFeign.getFeign(name);}@GetMapping("getName")public String getName(){return name;}@GetMapping("getRibbon")public String getRibbon(String name){ResponseEntity<String> entity=restTemplate.getForEntity("http://eureka-provider/provider/get/"+name,String.class,"NAME");return "entity.getStatusCode():"+entity.getStatusCode()+"\n entity.getHeaders():"+entity.getHeaders()+"\n entity.getBody():"+entity.getBody();}/*** 调用eureka元数据的方法获取客户端url并调用* @param name* @return*/@GetMapping("get")public String get(String name){logger.debug("进入TestController方法");List<ServiceInstance> instances=discoveryClient.getInstances("eureka-provider");if(instances.size()>0){ServiceInstance serviceInstance=instances.get(0);ResponseEntity<String> entity=restTemplate.getForEntity(serviceInstance.getUri().toString()+"/provider/get/"+name,String.class,"NAME");return "entity.getStatusCode():"+entity.getStatusCode()+"\n entity.getHeaders():"+entity.getHeaders()+"\n entity.getBody():"+entity.getBody();}else {return "暂无可提供的服务";}}/*** 调用eureka元数据的方法获取客户端url并调用* @return*/@GetMapping("detail")public String detail(){/*** 获取注册中心服务名集合*/List<String> services=discoveryClient.getServices();for (String service:services) {System.out.println(service);}System.out.println("*********************");System.out.println("*********************");List<ServiceInstance> instances=discoveryClient.getInstances("eureka-provider");for (ServiceInstance instance:instances) {/*** instance.getHost():10.159.82.116* 获取该服务ip*/System.out.println("instance.getHost():"+instance.getHost());/*** instance.getScheme():http* 获取该服务协议*/System.out.println("instance.getScheme():"+instance.getScheme());/*** instance.getServiceId():EUREKA-CONSUMER* 获取该服务名称*/System.out.println("instance.getServiceId():"+instance.getServiceId());/*** instance.getMetadata():{management.port=9002}* 获取该服务元数据*/System.out.println("instance.getMetadata():"+instance.getMetadata());/*** instance.getPort():9002* 获取该服务端口号*/System.out.println("instance.getPort():"+instance.getPort());/*** instance.getUri():http://10.159.82.116:9002* 获取该服务url路径*/System.out.println("instance.getUri():"+instance.getUri());}return null;}}@Value("${name}")是从配置文件中获取name的值,可以在这个类上添加@RefreshScope注解,这样当配置中心中的配置文件改变后,就可以通过调用acuaotr的一个接口来进行动态配置,而不需要每次都重启服务了。
调用接口:
http://127.0.0.1:9002/actuator/refresh
前边为服务地址,后边的refresh是配置的接口,这个是在配置文件中进行配置的
上边这样的一个配置中心已经比较完善了,有了配置中心高可用的一个支持,但是不知道发现一个问题没,当我们有多个节点服务的时候,线上配置因为需要进行了修改,如果想要达到动态配置的效果的话,理论上需要一个个去请求各个节点,实现动态配置,但是这样做,很明显太麻烦了。这也就有了接下来的消息总线,只需要请求配置中心服务端,然后再由服务端去请求客户端,客户端最后在更新配置,这样一个线程,具体请看下图
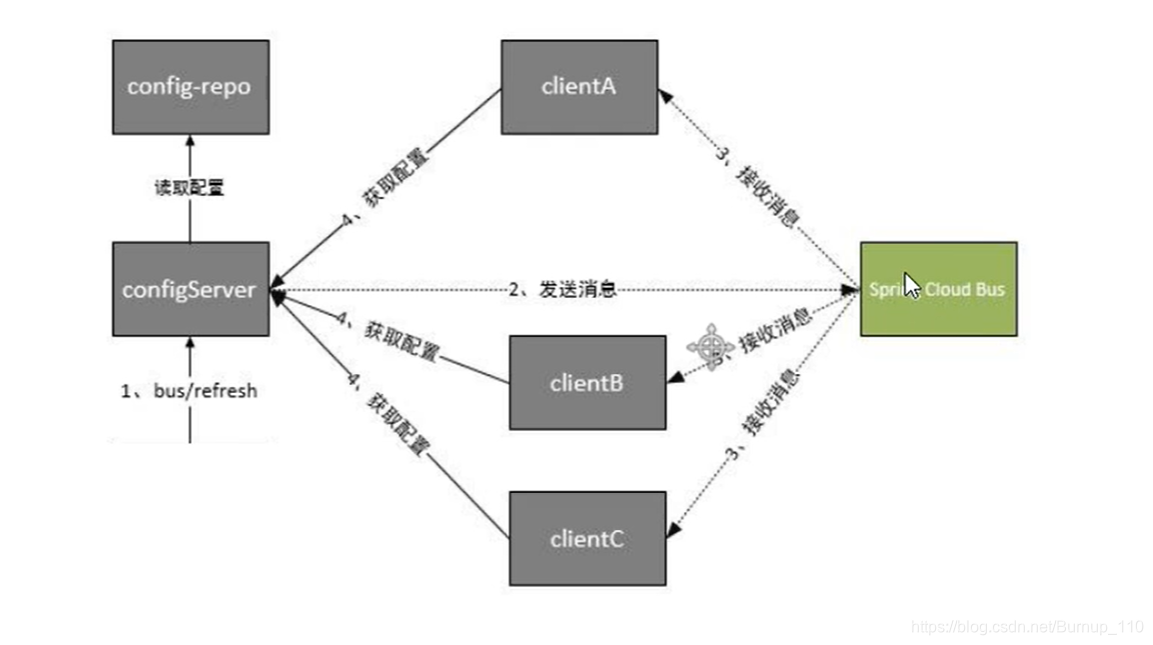
根据上边的项目修改如下
(1)添加依赖
<!--消息总线 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-bus</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-stream-binder-rabbit</artifactId></dependency>
config Server和config Client 都需要添加此依赖
(2)修改配置文件
Config Server:
server:port: 15000
spring:application:name: config-servercloud:config:server:git:uri: https://gitee.com/heshuai_mayun/config_-server_-repo.git
# search-paths: # git仓库地址下的相对地址 多个用逗号","分割。
# username: #仓库的账号
# password: # git仓库的密码。rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guesteureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/ # ,http://127.0.0.1:8000/eureka/# register-with-eureka: false# 开启动态刷新请求路径断点
management:endpoints:web:exposure:include: bus-refreshConfig Client:
spring:rabbitmq:host: 127.0.0.1port: 5672username: guestpassword: guestcloud:config:name: application # 配置文件的名称。profile: dev # 配置的策略。label: master # 配置文件的分支,默认是master。如果是是本地获取的话,则无用。
# uri: http://127.0.0.1:15000 # 配置配置中心服务端地址discovery:enabled: true #从注册中心中发现配置中心信息serviceId: config-server # 指定注册中心中配置中心的service-id,以便配置高可用集群## 开启动态刷新请求路径断点
#management:
# endpoints:
# web:
# exposure:
# include: refresheureka:instance:instance-id: ${spring.cloud.client.ip-address}:${server.port}prefer-ip-address: trueclient:service-url:defaultZone: http://127.0.0.1:9000/eureka/ # ,http://127.0.0.1:8000/eureka/配置文件变动不大,只是添加了消息中间件的配置和对于服务端的Acuator的配置
11.2 Apollo
Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
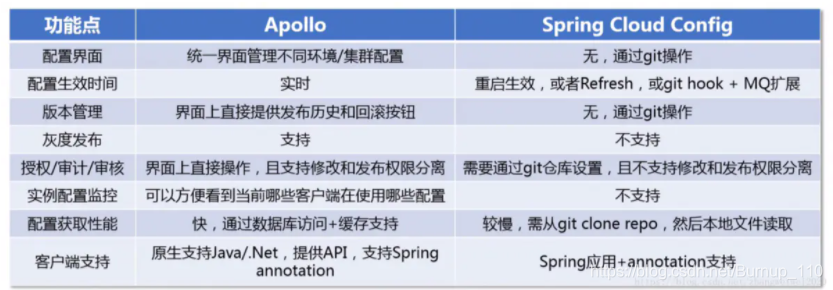
针对于SpringCloud Config,Appolo还有不少改进的地方,比如配置修改实时生效(热发布)、版本发布管理、灰度发布、权限管理、发布审核、操作审计等,具体详细内容可以看GitHub项目。中国项目,所以是中文的。。
看一下对比图
Apollo Demo
这个ApolloDemo是分为服务端和客户端的,服务端的话可以直接参考博客或者官网,在这里边已经对Apollo Quick Start安装非常详细了,不过这里边有一个确实在完成Demo的过程中困扰了我很久,下载jar包的时候,追求功能全面,选择了最新的apollo-quick-start-1.7.1版本,启动起来一直有问题,后来换了apollo-quick-start-1.6.0,可以正常启动了,特此标记
客户端:
客户端,我这里简单的建立了一个springboot的项目,就可以对配置中心进行练习了
(1)引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.0</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.appolo</groupId><artifactId>demo</artifactId><version>0.0.1-SNAPSHOT</version><name>demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.ctrip.framework.apollo</groupId><artifactId>apollo-client</artifactId><version>1.1.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.0.6.RELEASE</version></plugin></plugins></build></project>(2)application.yml配置文件
app:id: apollo-config # AppID,在apollo中创建项目所添加的appIDapollo:meta: http://localhost:8080 # 注册中心地址#cluster: myCluster#cacheDir: /opt/testDirbootstrap: # 开启apolloenable: truenamespaces: applicationenv: DEVserver:port: 16000
spring:application:name: apollo-configname: I is name
app.id:为在服务端web页面上创建的项目APP的id apollo.meta为apollo服务端的地址
apollo.cluster:为要配置的集群名称,如果没有可不填 apollo.cacheDir为自定义缓存路径
apollo.bootstrap.enable:为是否在工程启动的bootstrap阶段向Spring容器注入被托管的namespaces中的配置
apollo.bootstrap.namespaces:为要使用的namespaces,可在web页面上看到
env:为要获取的配置环境,目前支持以下几个值(大小写不敏感):
DEV(Development environment)
FAT(Feature Acceptance Test environment)
UAT(User Acceptance Testenvironment)
PRO(Production environment)
(3)启动类
因为项目比较简单,所以直接在启动类里边写了一些测试代码
/*** @EnableApolloConfig: 在启动类上添加此依赖,启动Apollo*/
@SpringBootApplication
@RestController
@RequestMapping
@EnableApolloConfig
public class DemoApplication {public static void main(String[] args) {SpringApplication.run(DemoApplication.class, args);}@Value("${name}")private String name;@GetMapping("getName")public String getName(){return name;}
}这样简单的Demo就写完了,还是比较简单的
结语
还记得同事问我:知道SpringCloud五大组件是什么么?很遗憾当时我并不知道,无言以对啊,只能以此为耻。
这篇博客从写的那天开始,也是我接触Cloud的时间,经历了将近两个月,这两个月利用工作之余的时间,一点点终于把整个SpringCloud体系都看了遍,不敢说多么了解,但是对于整个体系有了一个清晰的认识,以后还会在工作中或者练习一些Cloud项目进行深入学习。我很庆幸我坚持下来了,我也希望这是我学习的开始,永远不是结束。
有点感慨,啰嗦了一些。不过我估计这篇博客也不会有人看,毕竟太长了,我也初次学习,不敢说整理的多好。等一下深入学习了,在整理一些实用的博客吧。
SpringCloud五大组件:注册中心(Eureka、Consul、Nacos)、负载均衡(Ribbon)、断路器(Hystrix、Sentinel)、网关(Zuul、Gateway)、配置中心(Config、Apollo、Nacos)
贴一个与本篇博客相对应的Demo项目吧,已上传到GitHub,项目名:SpringCloud-primary
自此结束,如有感看,感谢这么长的文章坚持不弃。
这篇关于SpringCloud学习——浅学习(个人整理,很长,适合时间较多的观看)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





