本文主要是介绍论文阅读-- A simple transmit diversity technique for wireless communications,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一种简单的无线通信发射分集技术
论文信息:
Alamouti S M. A simple transmit diversity technique for wireless communications[J]. IEEE Journal on selected areas in communications, 1998, 16(8): 1451-1458.
创新性:
- 提出了一种新的发射分集方案。结果表明,在使用两个发射天线和一个接收天线的情况下,新方案提供了与使用一个发射天线和两个接收天线的MRRC相同的分集阶数。
- 该方案可以容易地推广到两个发射天线和接收天线,以提供分集顺序为。该方案的一个明显应用是在无线系统中的所有远程单元提供分集改进,在基站使用两个发射天线,而不是在所有远程终端使用两个接收天线。该方案不需要接收机对发射机的任何反馈,其计算复杂度与MRRC相似。
- 与MRRC相比,如果总辐射功率保持不变,则发射分集方案具有3dB的缺点,因为来自两个天线的两个不同符号同时发射。否则,如果总辐射功率加倍,那么它的性能与MRRC相同。此外,假设辐射功率相等,与MRRC的一个全功率放大器相比,该方案需要两个半功率放大器,这对于系统实现可能是有利的。
Abstract
提出了一种简单的双分支发射分集方案。该方案使用两个发射天线和一个接收天线,提供了与一个发射天线和两个接收天线的最大比率接收机组合(MRRC)相同的分集阶数。
I. INTRODUCTION
使可靠的无线传输变得困难的基本现象是时变多径衰落。
如何缓解无线通信中的多径效应?
控制发射功率是最有效的技术,然而发射功率及放大器成本是受限的且发射机需要信道信息这将导致吞吐量降低及发射机和接收机的复杂度。
天线分集易实现且有效,然而典型的接收分集方案的明显缺点是远端的成本大小和功率,而下一代无线通信系统的基本趋势为增加基站复杂性,基站通常服务于数百到数千个远程单元。因此,向基站添加设备比向远程单元添加设备更经济。因此作者在接收分集的基础上提出了一种简单的发射分集技术。
第二节讨论了经典的最大比接收分集组合,并给出了简单的数学描述。在第三节中,讨论了具有一个和两个接收天线的新的两分支发射分集方案。 在第四节中,给出了相干二进制相移键控(BPSK)调制的新方案的误比特性能,并与MRRC进行了比较。 第五节中详细讨论所提出的方案的实际实现和经典的MRRC之间存在成本和性能差异。
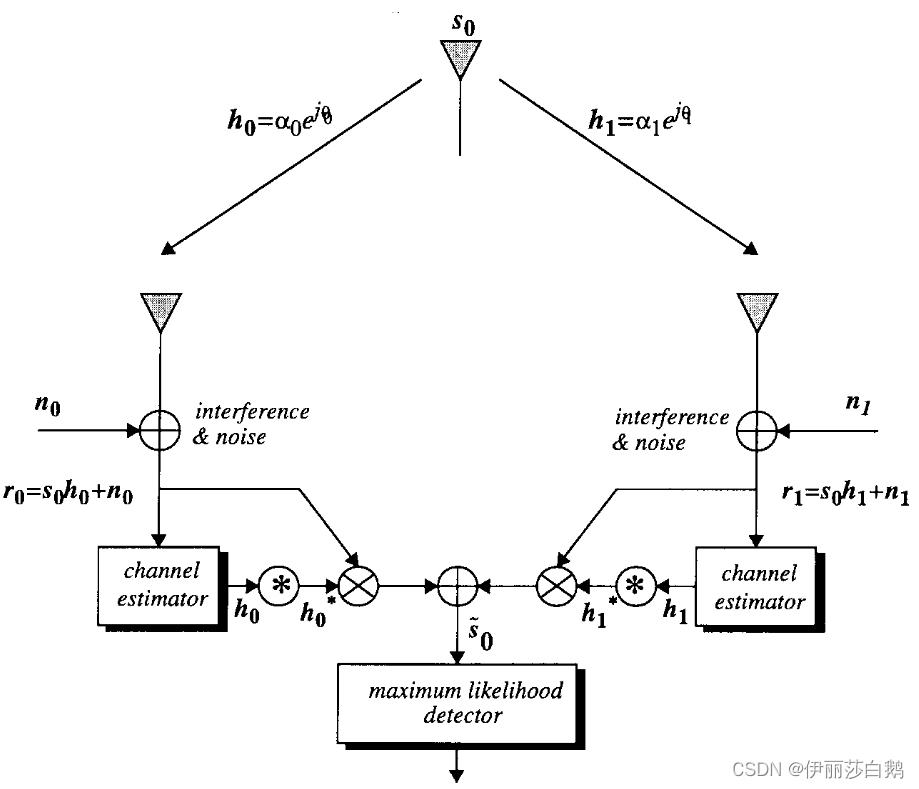
II. CLASSICAL MAXIMAL-RATIO RECEIVE COMBINING (MRRC) SCHEME
本章给出了经典接收分集技术–MRRC,并给出了其数学推导
III. THE NEW TRANSMIT DIVERSITY SCHEME
A. Two-Branch Transmit Diversity with One Receiver
本章是文章的核心,作者提出了一种新的发射分集技术
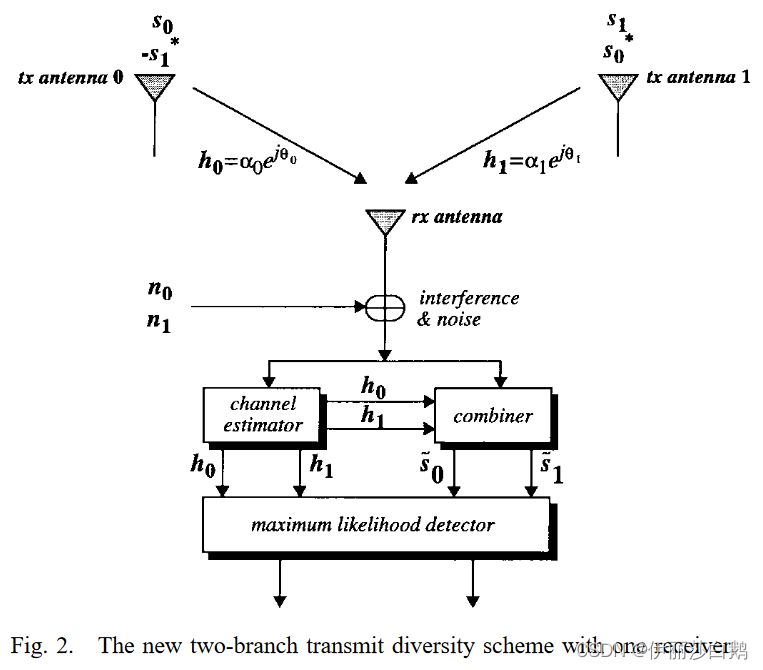
整个结构可以分为三个部分
-
The Encoding and Transmission Sequence 编码传输序列
两个天线同时开始发送数据,下一次发送数据为之前另一个天线的共轭复数。

-
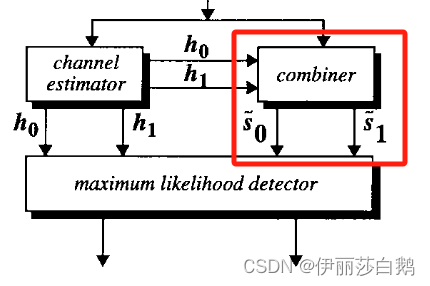
The Combining Scheme 组合方案
图中所示的组合器构建以下两个组合信号,它们被发送到最大似然检测器中(在接收分集中这里只有一个组合信号了)
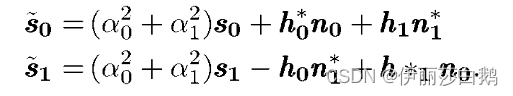
-
The Maximum Likelihood Decision Rule 最大似然检测器判断
最大似然判定规则:这些组合信号然后被发送到最大似然检测器,对于每个信号和,最大似然检测器对PSK信号使用规则进行判定。
Two-Branch Transmit Diversity with Receivers
可能存在需要更高阶分集并且远程单元处的多个接收天线是可行的应用。在这种情况下,可以用2个发射和M个接收天线提供2M的分集阶数。文中详细讨论了两个发射天线和两个接收天线的特殊情况。

IV. ERROR PERFORMANCE SIMULATIONS
在瑞利衰落的情况下,采用相干BPSK的误码性能下,同样分集阶数的新方案为使得两个发射天线的总发射功率与MRRC方案相同,其误码性能较后者差3dB**(差异原因是总功率保持了一致)**,若按每个发射天线的平均SNR画误码率曲线图,则二者误码率曲线将重叠。而在实际执行中,发射端 3dB 的降低同样能另线性功率放大器降低成本。
横轴为发射总功率
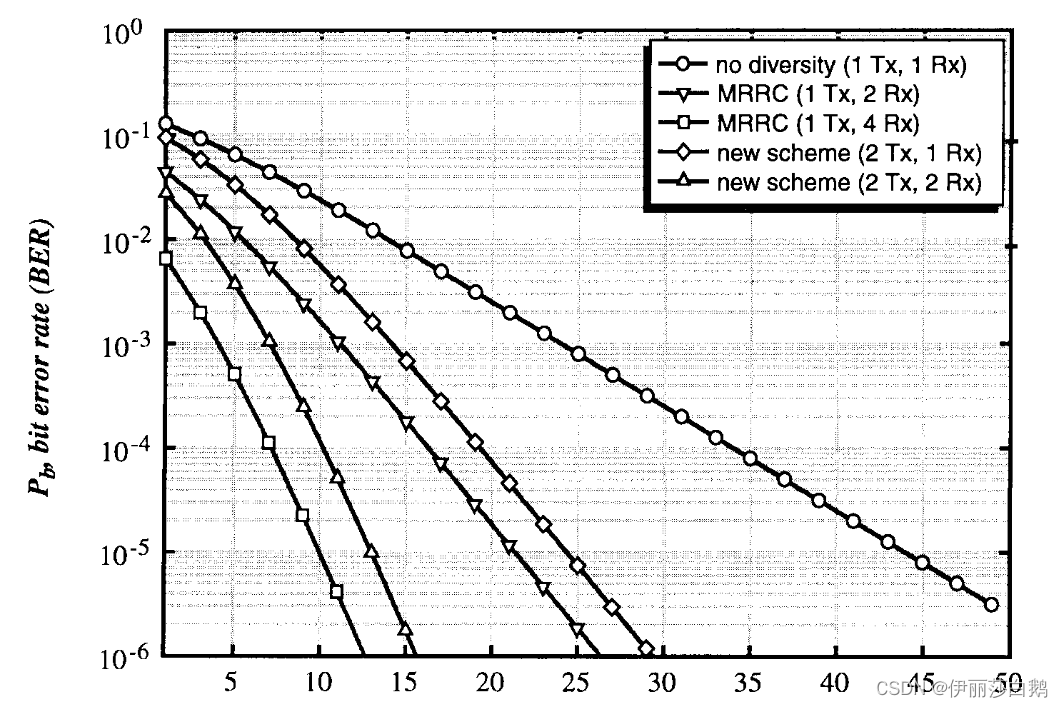
V. IMPLEMENTATION ISSUES 应用对比
Power Requirements
如果系统受到辐射功率限制,发射分集为了从两个发射天线获得相同的总辐射功率,分配给每个符号的能量应该减半。这将导致错误性能损失3dB。然而,每个发射链中功率降低3dB意味着功率放大器更便宜、更小或线性度更低。新方案有3dB的劣势,但仅需要两个1/2功率放大器。
Sensitivity to Channel Estimation Errors
信道的估计必须从单个接收信号中导出。因此,信道估计任务是不同的。为了估计从一个发射天线到接收天线的信道,导频符号必须仅从相应的发射天线发射。为了估计所有信道,导频必须在天线之间交替(或者必须从天线发送正交导频符号)。无论哪种情况,都需要数倍的导频。这意味着对于双分支发射分集方案,需要两倍于双接收分集组合方案的导频。
Impact on Interference
新方案要求同时从两个天线传输信号。虽然一半的功率从每个天线发射,但潜在干扰源的数量似乎增加了一倍,即我们有两倍的干扰源数量,每个干扰源具有一半的干扰功率。
Soft Failure
软故障接收分集组合方案的优点之一是由于多个接收链而增加了可靠性。如果其中一个接收链出现故障,而另一个接收链正常工作,则性能损失与分集增益相当。换句话说,信号仍然可以被检测,但是质量较差。发射分集同样适用
预备知识
分集阶数(diversity order):指独立的支路衰落数,若每对接收天线间的衰落都独立,则分集阶数=分集天线数Nt*接收天线数Nr,分集阶数越多,可以获得的最大分集增益越大,对系统性能改善越多。
这篇关于论文阅读-- A simple transmit diversity technique for wireless communications的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)