本文主要是介绍基于Tire树和最大概率法的中文分词功能的Java实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于分词系统的实现来说,主要应集中在两方面的考虑上:一是对语料库的组织,二是分词策略的制订。
1. Tire树
Tire树,即字典树,是通过字串的公共前缀来对字串进行统计、排序及存储的一种树形结构。其具有如下三个性质:
1) 根节点不包含字符(或汉字),除根节点以外的每个节点只能包含一个字符(汉字)
2) 从根节点到任一节点的路径上的所有节点中的字符(汉字)按顺序排列的字符串(词组)就是该节点所对应的字符串(词组)
3) 每个节点的所有直接子节点包含的字符(汉字)各不相同
上述性质保证了从Tire树中查找任意字符串(词组)所需要比较的次数尽可能最少,以达到快速搜索语料库的目的。
如下图所示的是一个由词组集<一,一万,一万多,一万元,一上午,一下午,一下子>生成的Tire树的子树:
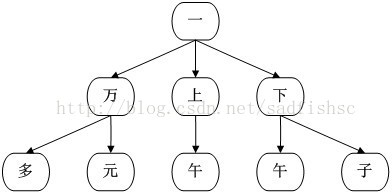
可见,从子树的根节点“一”开始,任意一条路径都能组成一个以“一”开头的词组。而在实际应用中,需要给每个节点附上一些数据属性,如词频,因而可以用这些属性来区别某条路径上的字串是否是一个词组。如,节点“上”的词频为-1,那么“一上”就不是一个词组。
如下的代码是Tire树的Java实现:
- package chn.seg;
-
- import java.util.HashMap;
- import java.util.Map;
-
- public class TireNode {
-
- private String character;
- private int frequency = -1;
- private double antilog = -1;
- private Map<String, TireNode> children;
-
- public String getCharacter() {
- return character;
- }
-
- public void setCharacter(String character) {
- this.character = character;
- }
-
- public int getFrequency() {
- return frequency;
- }
-
- public void setFrequency(int frequency) {
- this.frequency = frequency;
- }
-
- public double getAntilog() {
- return antilog;
- }
-
- public void setAntilog(double antilog) {
- this.antilog = antilog;
- }
-
- public void addChild(TireNode node) {
- if (children == null) {
- children = new HashMap<String, TireNode>();
- }
-
- if (!children.containsKey(node.getCharacter())) {
- children.put(node.getCharacter(), node);
- }
- }
-
- public TireNode getChild(String ch) {
- if (children == null || !children.containsKey(ch)) {
- return null;
- }
-
- return children.get(ch);
- }
-
- public void removeChild(String ch) {
- if (children == null || !children.containsKey(ch)) {
- return;
- }
-
- children.remove(ch);
- }
- }
2. 最大概率法(动态规划)
最大概率法是中文分词策略中的一种方法。相较于最大匹配法等策略而言,最大概率法更加准确,同时其实现也更为复杂。
基于动态规划的最大概率法的核心思想是:对于任意一个语句,首先按语句中词组的出现顺序列出所有在语料库中出现过的词组;将上述词组集中的每一个词作为一个顶点,加上开始与结束顶点,按构成语句的顺序组织成有向图;再为有向图中每两个直接相连的顶点间的路径赋上权值,如A→B,则AB间的路径权值为B的费用(若B为结束顶点,则权值为0);此时原问题就转化成了单源最短路径问题,通过动态规划解出最优解即可。
如句子“今天下雨”,按顺序在语料库中存在的词组及其费用如下:
今,a
今天,b
天,c
天下,d
下,e
下雨,f
雨,g
则可以生成如下的加权有向图:
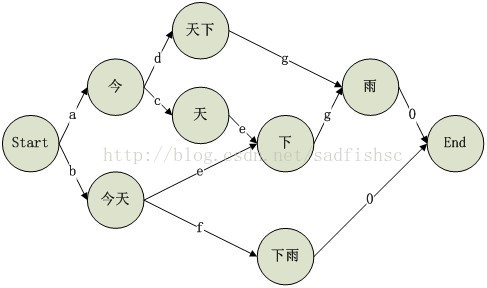
显而易见,从“Start”到“End”的单源路径最优解就是“今天下雨”这个句子的分词结果。
那么,作为权值的费用如何计算呢?对于最大概率法来说,要求的是词组集在语料库中出现的概率之乘积最大。对应单源最短路径问题的费用来说,
费用 = log( 总词频 / 某一词组词频 )
通过上述公式就可以把“最大”问题化为“最小”问题,“乘积”问题化为“求和”问题进行求解了。
如下的代码是基于动态规划的最大概率法的Java实现:
3. 测试代码
- package chn.seg;
-
- import java.io.IOException;
-
- public class Main {
-
- public static void main(String[] args) throws ClassNotFoundException, IOException {
- ChnSeq cs = new ChnSeq();
- cs.init();
-
- String sentence = "生活的决定权也一直都在自己手上";
-
- String[] segs = cs.segment(sentence);
- for (String s: segs) {
- System.out.print(s + "\t");
- }
- }
-
- }
这篇关于基于Tire树和最大概率法的中文分词功能的Java实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






