本文主要是介绍mysql分组后排序取第一条,mysql分组排序取第一条记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先说结论:在Mysql中,通过GroupBy分组后,会取主键ID最小的一条数据作为分组后的数据。如果存在需求,根据其他字段排序后取对应字段最大或者最小值的话,通过SQL语句是可以实现的,核心在于排序后需要加Limit xx。
先直接看结论
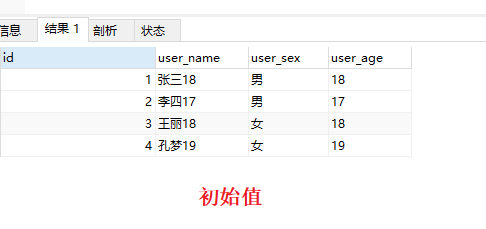
数据如下:
id
user_name
user_sex
user_age
1
张三18
男
18
2
李四17
男
17
3
王丽18
女
18
4
孔梦19
女
19
需求:查询出男生女生年龄最小的数据
正确解法select id,user_name,user_sex,user_age from (
SELECT id,user_name,user_sex,user_age FROM `user_test`
order by user_age
limit 100
)A
group by A.user_sex
结果如下:
id
user_name
user_sex
user_age
2
李四17
男
17
3
王丽18
女
18
常规思路(不知道加 limit)select id,user_name,user_sex,user_age from (
SELECT id,user_name,user_sex,user_age FROM `user_test`
order by user_age
)A
group by A.user_sex
结果如下:
id
user_name
user_sex
user_age
1
张三18
男
18
3
王丽18
女
18
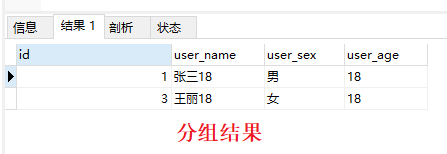
男生是取的年龄最大的,女生则是年龄最小的,唯一的共同点在于取得值都是各自分组内 ID 最小的那个
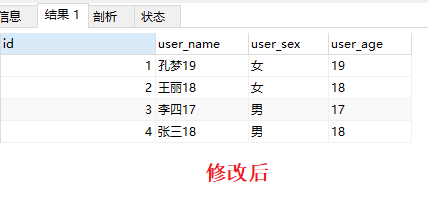
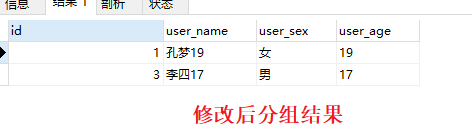
验证
为了验证 GroupBy 以后是以id取优先级,我改一下id值,可以发现分组后永远取的是 id 最小的那个,跟group by的字段没任何关系
![]
原因
在知乎上找到了相应的问题,发现有人说是命中主键 id 最小的,也有人说是谬 论。根据提供的资料,还是看不懂。目前只能先记录下当前的解决方案。
GROUP BY是如何选择哪一条数据留下的?,
优化
limit xx ,可以默认写成 1000 这种,但是如果实际场景每组的数据量很大的话,limit 太小了可能直接就导致数据不全了,可以采用动态拼接 SQL 语句的办法:先查询出指定条件数据的个数(dataCount),将 datacount 作为参数替换 xx 即可。
这篇关于mysql分组后排序取第一条,mysql分组排序取第一条记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






