本文主要是介绍ORACLE集群管理-集群丢失心跳导致集群重新配置(NHB,DHB,LHB)步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ORACLE 11.2版本以上,集群心跳汇总图表如下:
脑裂处理原则:
1 节点数多的子集群存活。
2 如果分裂的相同,则包含最小编号节点的子集群存活。
可以通过以下命令,查询ocssd.bin的线程信息:
pstack -p PID<ocssd.bin>
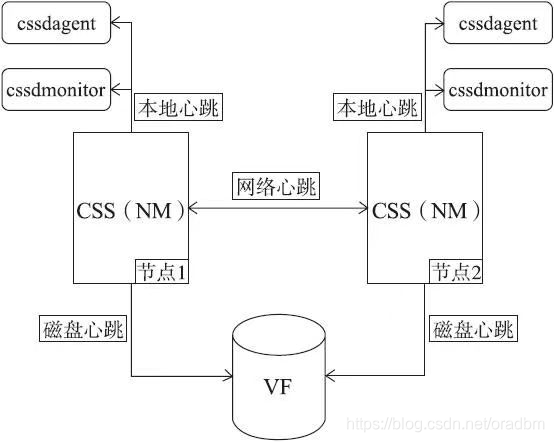
<1> 丢失网络心跳
网络心跳主要由以下occd.bin线程:
1 发送线程clssnmSendingThread,该线程每秒钟向集群钟所有节点发送心跳信息。
2 分析线程clssnmPollingThread,该线程会分析收到的网络信息(私有),如果发现某一个或节点出现丢失网络心跳(超过misscount值)就会通知集群进行重新配置。
3 重新配置现场clssnmRcfgMgrTheead该进程负责集群重新配置。
4 派遣线程clssnmClusterListener负责从远端节点接受信息,根据信息类型发送给相关线程进行处理。
<1.1> 丢失网络心跳,重新配置步骤
1 当集群一个节点连续一段时间 (超过集群的misscount) 丢失网络心跳之后,分析线程决定发起重新配置集群。
2 集群发起重新配置的节点为RM节点,这个节点通常为节点编号最小的,想集群其他节点发送重新配置消息,所有收到此消息的节点会回复该消息,并通知RM节点自己的状态。
3 RM节点基于每个节点进行投票并检查是否有脑裂会发生。
4 对于脑裂检查,RM节点会检查网络心跳无法.
5 RM节点向表决盘的kill block中写入 "有毒信息",需要重启的节点在访问表决盘时读取到"有毒“信息时,完成对本节点的重启。如果RM节点发现某些节点已经离开集群,那么也会发生重新配置。
6 RM节点修改集群列表(主要是在表决盘中),重新配置完成。
在节点2 直接使用ifdown命令关闭唯一的私有网卡,节点1开始出现diskping相关日志。节点2被驱逐,将私网网卡ifup后,数据库启动正常。
<2> 磁盘心跳
磁盘心跳主要目的就是当集群发生时,帮助制定脑裂的解决方案 。
Oracle集群的每一个节点 每秒钟都会像集群的所有表决盘注册本地节点的磁盘心跳信息,(也就是说vf中的信息是相同的),同时也将自己能够联系到的集群中的其他节点信息写入表决盘。
一旦发生脑裂问题,css重新配置线程就可以通过表决盘中的信息了解集群节点之间的连通性,而决定集群分裂成几个子集群,以及每个子集群包含节点情况和每个节点的状态。
磁盘心跳主要包含以下线程:
1 磁盘心跳线程,(clssnmvDiskPingThread):该线程负责向集群的表决盘中发送 磁盘心跳信息,同时还负责读取表决盘中kill block的信息,以确定本节点是否需要重新启动。--发生脑裂时,才启动。
这篇关于ORACLE集群管理-集群丢失心跳导致集群重新配置(NHB,DHB,LHB)步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









