本文主要是介绍拓端tecdat|基于R语言股票市场收益的统计可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被要求撰写关于股票市场收益的研究报告,包括一些图形和统计输出。
金融市场上最重要的任务之一就是分析各种投资的历史收益。要执行此分析,我们需要资产的历史数据。数据提供者很多,有些是免费的,大多数是付费的。在本文中,我们将使用Yahoo金融网站上的数据。
在这篇文章中,我们将:
- 下载收盘价
- 计算收益率
- 计算收益的均值和标准差
让我们先加载库。
library(tidyquant)
library(timetk)我们将获得Netflix价格的收盘价。
netflix <- tq_get("NFLX", from = '2009-01-01',to = "2018-03-01",get = "stock.prices")接下来,我们将绘制Netflix的调整后收盘价。
netflix %>%ggplot(aes(x = date, y = adjusted)) +geom_line() +ggtitle("Netflix since 2009") +labs(x = "Date", "Price") +scale_x_date(date_breaks = "years", date_labels = "%Y") +labs(x = "Date", y = "Adjusted Price") +theme_bw()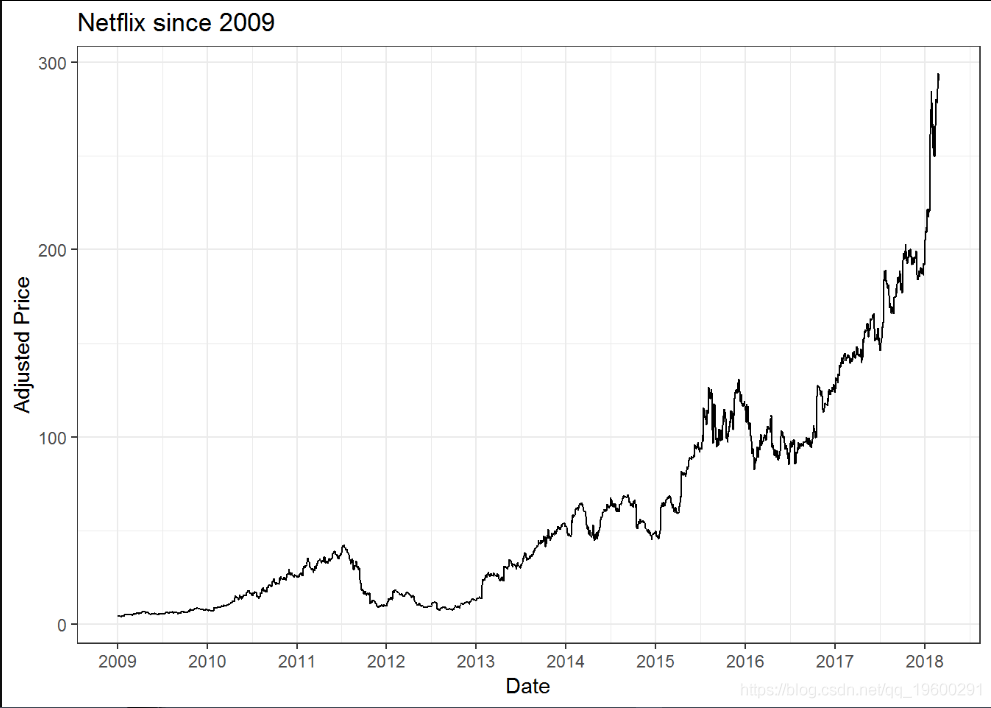
计算单个股票的每日和每月收益率
一旦我们从Yahoo Finance下载了收盘价,下一步便是计算收益。我们将再次使用tidyquant包进行计算。我们已经在上面下载了Netflix的价格数据,如果您还没有下载,请参见上面的部分。
# 计算每日收益netflix_daily_returns <- netflix %>%tq_transmute(select = adjusted, 这指定要选择的列mutate_fun = periodReturn, # 这指定如何处理该列period = "daily", # 此参数计算每日收益col_rename = "nflx_returns") # 重命名列#计算每月收益
netflix_monthly_returns <- netflix %>%tq_transmute(select = adjusted,mutate_fun = periodReturn,period = "monthly", # 此参数计算每月收益col_rename = "nflx_returns")绘制Netflix的每日和每月收益图表
# 我们将使用折线图获取每日收益ggplot(aes(x = date, y = nflx_returns)) +geom_line() +theme_classic() +
查看Netflix的每日收益图表后,我们可以得出结论,收益波动很大,并且股票在任何一天都可以波动+/- 5%。为了了解收益率的分布,我们可以绘制直方图。
netflix_daily_returns %>%ggplot(aes(x = nflx_returns)) +geom_histogram(binwidth = 0.015) +theme_classic() +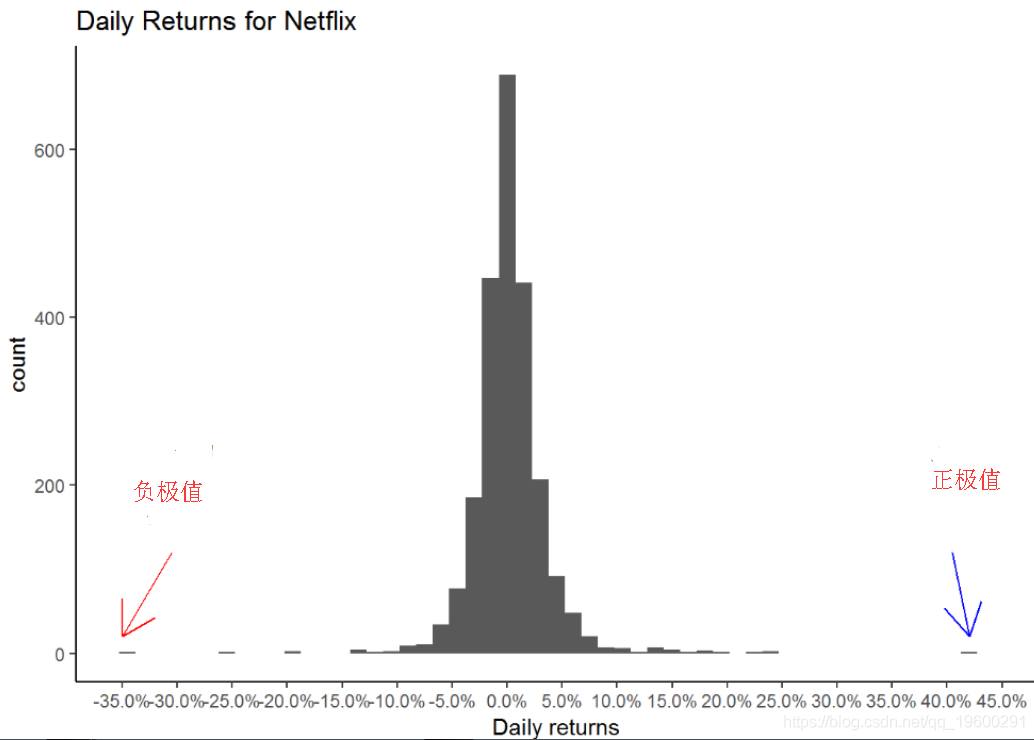
接下来,我们可以绘制自2009年以来Netflix的月度收益率。我们使用条形图来绘制数据。
# 绘制Netflix的月度收益图表。 使用条形图ggplot(aes(x = date, y = nflx_returns)) +geom_bar(stat = "identity") +theme_classic() +

计算Netflix股票的累计收益
绘制每日和每月收益对了解投资的每日和每月波动很有用。要计算投资的增长,换句话说,计算投资的总收益,我们需要计算该投资的累积收益。要计算累积收益,我们将使用 cumprod() 函数。
mutate(cr = cumprod(1 + nflx_returns)) %>% # 使用cumprod函数 ggplot(aes(x = date, y = cumulative_returns)) +geom_line() +theme_classic() +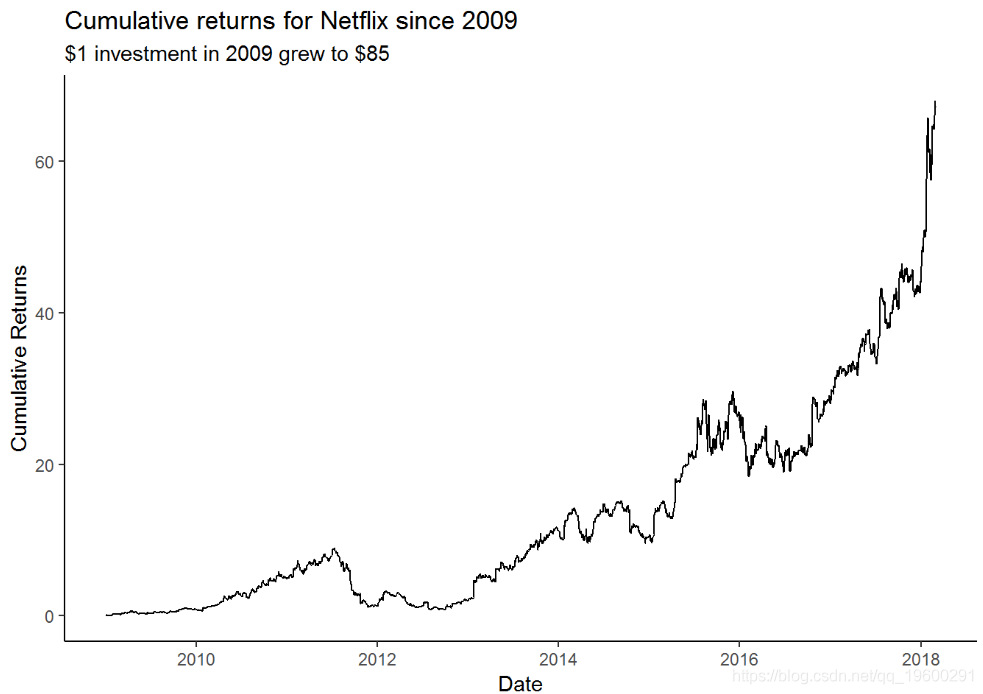
该图表显示了自2009年以来Netflix的累计收益。有了事后分析的力量, 自2009年以来,可以用1美元的投资赚取85美元。但据我们所知,说起来容易做起来难。在10年左右的时间里,在Qwickster惨败期间投资损失了其价值的50%。在这段时期内,很少有投资者能够坚持投资。
ggplot(aes(x = date, y = cumulative_returns)) +geom_line() +theme_classic() + 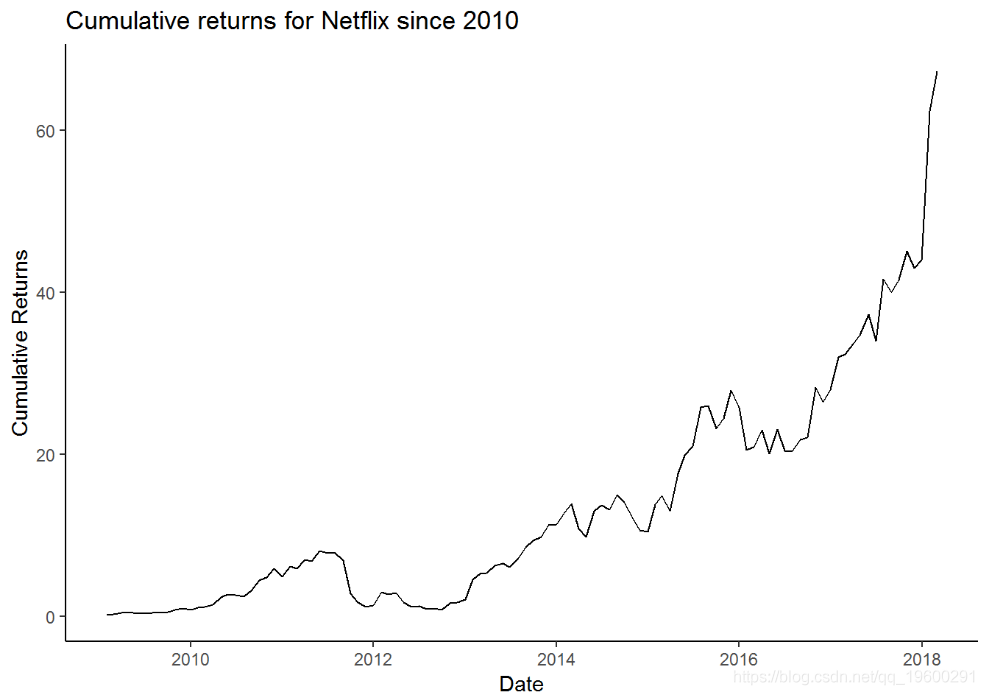
我们可以直观地看到,月收益表比日图表要平滑得多。
多只股票
下载多只股票的股票市场数据。
#将我们的股票代码设置为变量tickers <- c("FB", "AMZN", "AAPL", "NFLX", "GOOG") # 下载股价数据multpl_stocks <- tq_get(tickers, 绘制多只股票的股价图
接下来,我们将绘制多只股票的价格图表
multpl_stocks %>%ggplot(aes(x = date, y = adjusted, 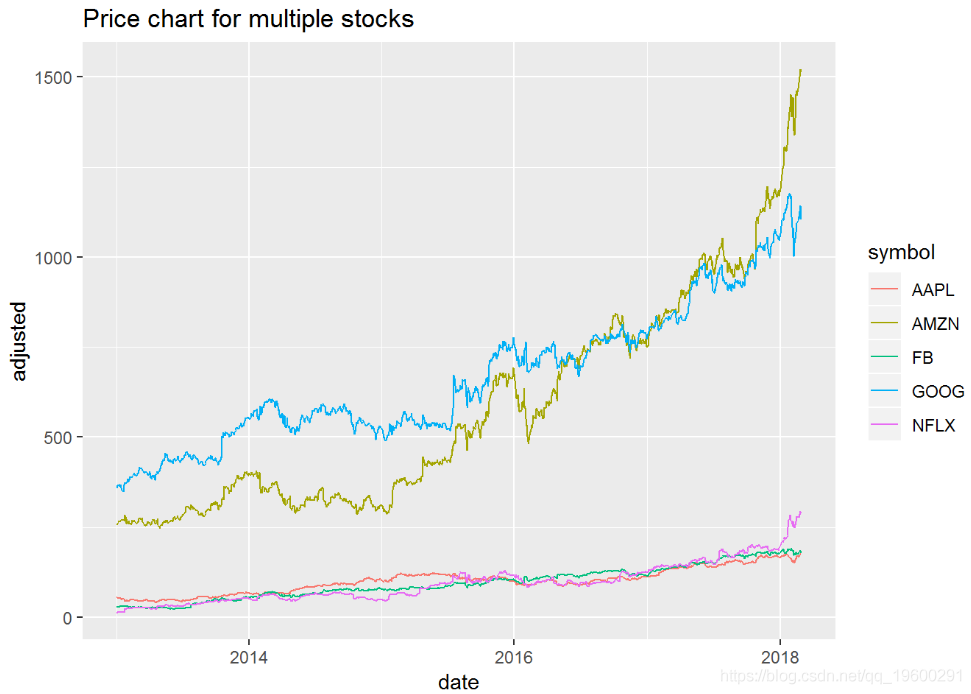
这不是我们预期的结果。由于这些股票具有巨大的价格差异(FB低于165,AMZN高于1950),因此它们的规模不同。我们可以通过按各自的y比例绘制股票来克服此问题。
facet_wrap(~symbol, scales = "free_y") + # facet_wrap用于制作不同的页面theme_classic() + 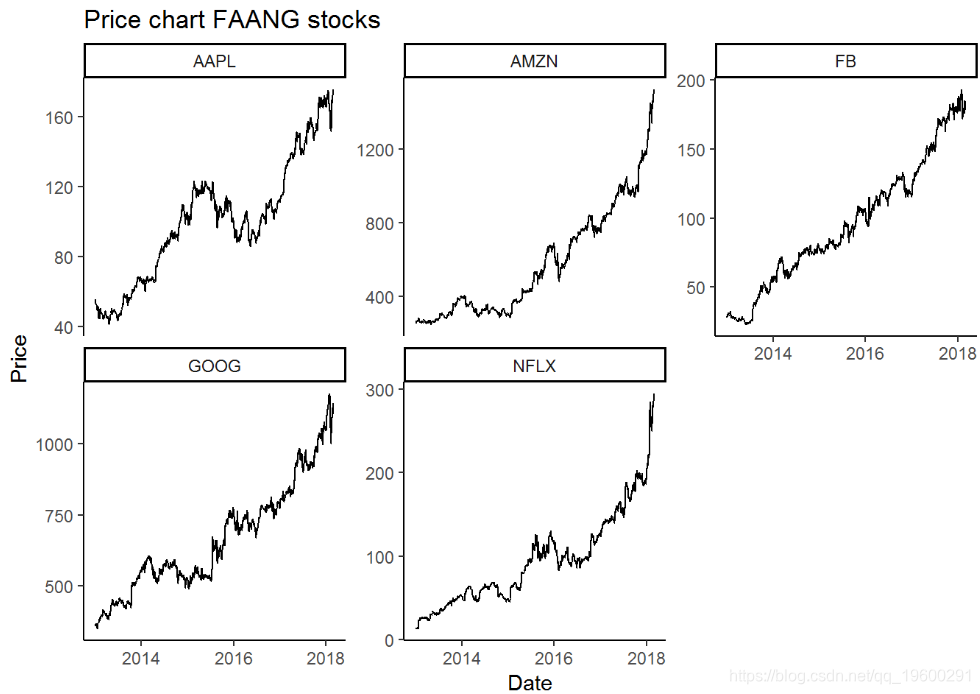
计算多只股票的收益
计算多只股票的收益与单只股票一样容易。这里只需要传递一个附加的参数。我们需要使用参数 group_by(symbol) 来计算单个股票的收益。
#计算多只股票的每日收益tq_transmute(select = adjusted,mutate_fun = periodReturn,period = 'daily',col_rename = 'returns')#计算多只股票的月收益tq_transmute(select = adjusted,mutate_fun = periodReturn,period = 'monthly',col_rename = 'returns')绘制多只股票的收益图表
一旦有了收益计算,就可以在图表上绘制收益。
multpl_stock_daily_returns %>%ggplot(aes(x = date, y = returns)) +geom_line() +geom_hline(yintercept = 0) + 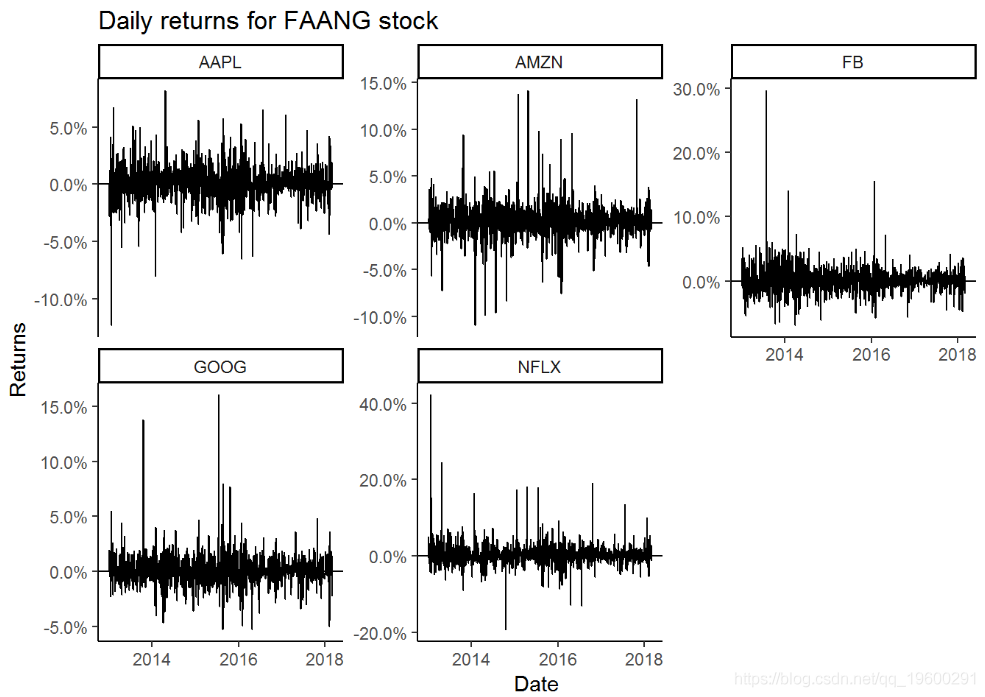
multpl_stock_monthly_returns %>%ggplot(aes(x = date, y = return scale_fill_brewer(palette = "Set1", # 我们会给他们不同的颜色,而不是黑色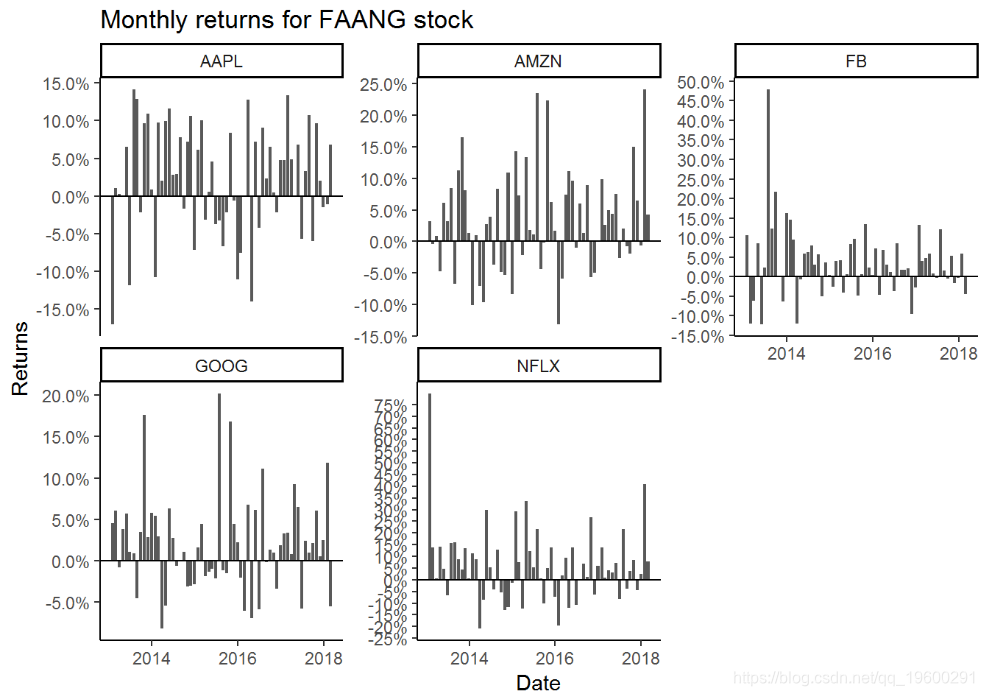
在FAANG股票中,苹果的波动最小,而Facebook和Netflix的波动最大。对于他们从事的业务而言,这是显而易见的。Apple是一家稳定的公司,拥有稳定的现金流量。它的产品受到数百万人的喜爱和使用,他们对Apple拥有极大的忠诚度。Netflix和Facebook也是令人难以置信的业务,但它们处于高增长阶段,任何问题(收益或用户增长下降)都可能对股票产生重大影响。
计算多只股票的累计收益
通常,我们希望看到过去哪种投资产生了最佳效果。为此,我们可以计算累积结果。下面我们比较自2013年以来所有FAANG股票的投资结果。哪项是自2013年以来最好的投资?
multpl_stock_monthly_returns %>%mutate(returns e_returns = cr - 1) %>%ggplot(aes(x = date, y = cumulative_returns, color = symbol)) +geom_line() +labs(x = "Date" 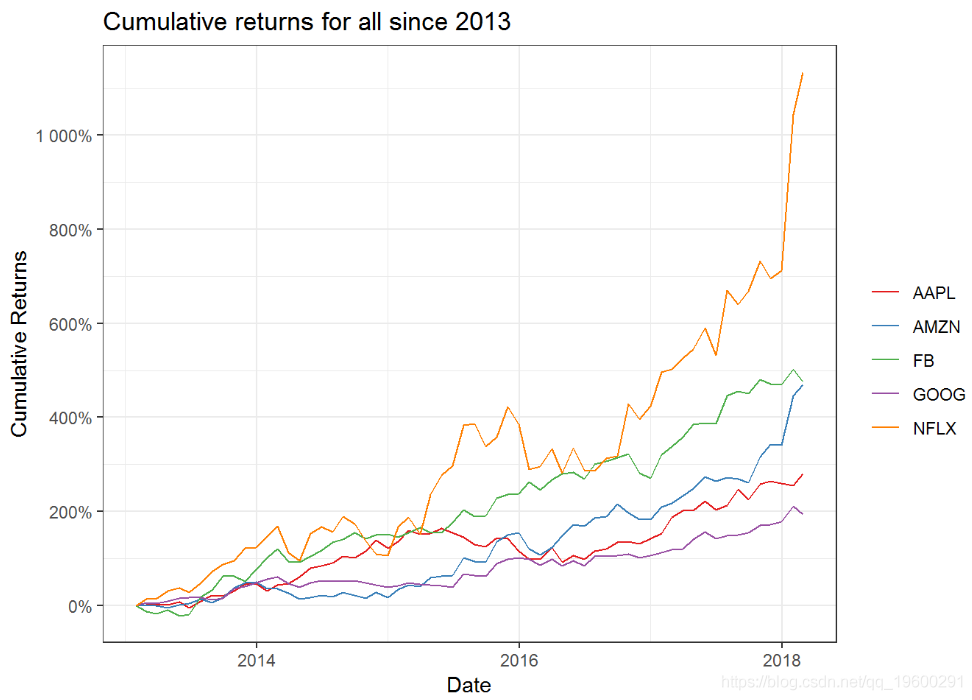
毫不奇怪,Netflix自2013年以来获得了最高的收益。亚马逊和Facebook位居第二和第三。
统计数据
计算单个股票的均值,标准差
我们已经有了Netflix的每日和每月收益数据。现在我们将计算收益的每日和每月平均数和标准差。 为此,我们将使用 mean() 和 sd()函数。
# 计算平均值.[[1]] %>%mean(na.rm = TRUE)nflx_monthly_mean_ret <- netfl turns) %>%.[[1]] %>%mean(na.rm = TRUE)# 计算标准差nflx_daily_sd_ret <- netflirns) %>%.[[1]] %>%sd()nflx_monthly_sd_ret <- netflix_rns) %>%.[[1]] %>%sd()nflx_stat ## # A tibble: 2 x 3
## period mean sd
## <chr> <dbl> <dbl>
## 1 Daily 0.00240 0.0337
## 2 Monthly 0.0535 0.176我们可以看到Netflix的平均每日收益为0.2%,标准差为3.3%。它的月平均回报率是5.2%和17%标准差。该数据是自2009年以来的整个时期。如果我们要计算每年的均值和标准差,该怎么办。我们可以通过按年份对Netflix收益数据进行分组并执行计算来进行计算。
netflix %>%summarise(Monthly_Mean_Returns = mean(nflx_returns),MOnthly_Standard_Deviation = sd(nflx_returns) ## # A tibble: 10 x 3
## year Monthly_Mean_Returns MOnthly_Standard_Deviation
## <dbl> <dbl> <dbl>
## 1 2009 0.0566 0.0987
## 2 2010 0.110 0.142
## 3 2011 -0.0492 0.209
## 4 2012 0.0562 0.289
## 5 2013 0.137 0.216
## 6 2014 0.00248 0.140
## 7 2015 0.0827 0.148
## 8 2016 0.0138 0.126
## 9 2017 0.0401 0.0815
## 10 2018 0.243 0.233我们还可以绘制结果更好地理解。
netflix_monthly_returns %>%mutate(year = rns, Standard_Deviation, keyistic)) +geom_bar(stat = "identity", position = "dodge") +scale_y_continuous(b ) +theme_bw() +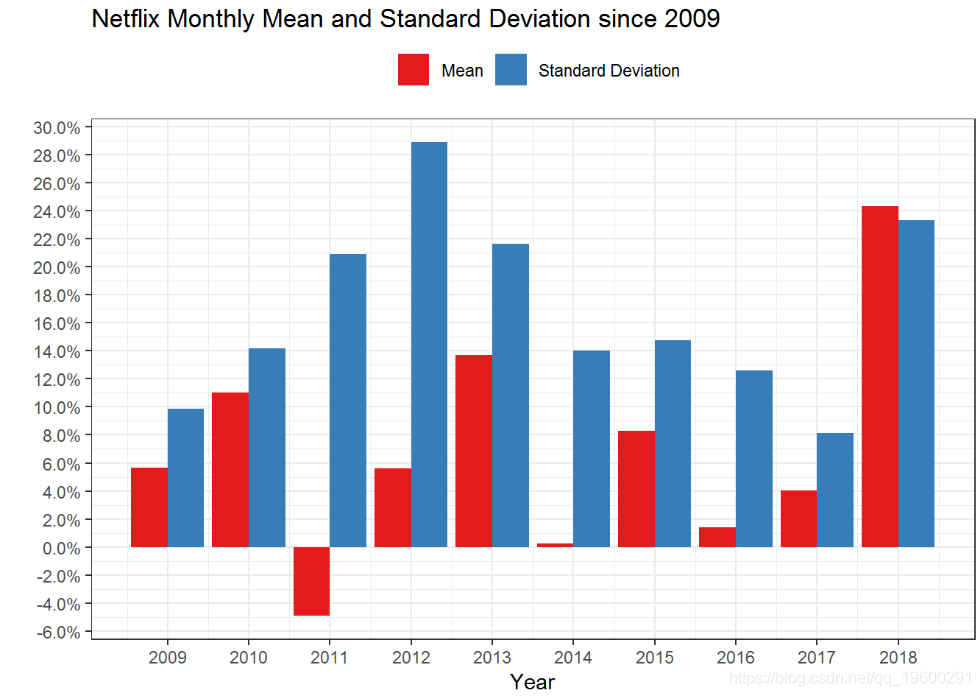
我们可以看到,自2009年以来,每月收益和标准差波动很大。2011年,平均每月收益为-5%。
计算多只股票的均值,标准差
接下来,我们可以计算多只股票的均值和标准差。
group_by(symbol) %>%summarise(mean = mean(returns),sd = sd(returns)) ## # A tibble: 5 x 3
## symbol mean sd
## <chr> <dbl> <dbl>
## 1 AAPL 0.00100 0.0153
## 2 AMZN 0.00153 0.0183
## 3 FB 0.00162 0.0202
## 4 GOOG 0.000962 0.0141
## 5 NFLX 0.00282 0.0300group_by(symbol) %>%summarise(mean = mean(returns),sd = sd(returns)) ## # A tibble: 5 x 3
## symbol mean sd
## <chr> <dbl> <dbl>
## 1 AAPL 0.0213 0.0725
## 2 AMZN 0.0320 0.0800
## 3 FB 0.0339 0.0900
## 4 GOOG 0.0198 0.0568
## 5 NFLX 0.0614 0.157计算收益的年均值和标准差。
%>%group_by(symbol, year) %>%summarise(mean = mean(returns),sd = sd(returns))## # A tibble: 30 x 4
## # Groups: symbol [?]
## symbol year mean sd
## <chr> <dbl> <dbl> <dbl>
## 1 AAPL 2013 0.0210 0.0954
## 2 AAPL 2014 0.0373 0.0723
## 3 AAPL 2015 -0.000736 0.0629
## 4 AAPL 2016 0.0125 0.0752
## 5 AAPL 2017 0.0352 0.0616
## 6 AAPL 2018 0.0288 0.0557
## 7 AMZN 2013 0.0391 0.0660
## 8 AMZN 2014 -0.0184 0.0706
## 9 AMZN 2015 0.0706 0.0931
## 10 AMZN 2016 0.0114 0.0761
## # ... with 20 more rows我们还可以绘制此统计数据。
multpl_stock_monthly_returns %>%mutate(year = year(date)) %>%group_by(symbol, yea s = seq(-0.1,0.4,0.02),labels = scales::percent) +scale_x_continuous(breaks = seq(2009,2018,1)) +labs(x = "Year", y = Stocks") +ggtitle 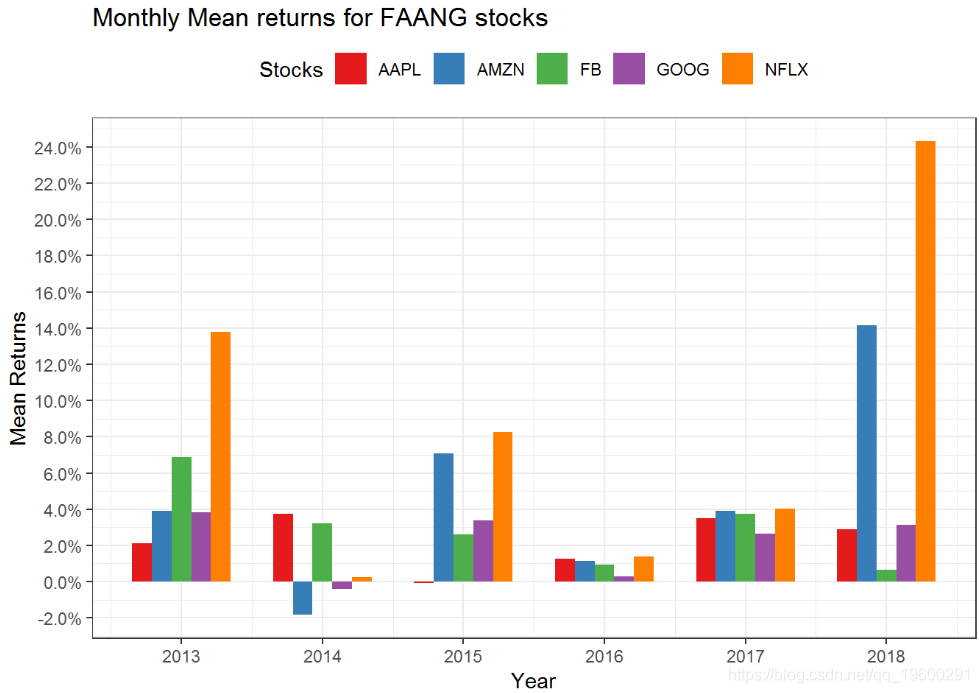
multpl_stock_monthly_returns %>%mutate(year = year(date)) %>% ggplot(aes(x = year, y = sd, fill = symbol)) +geom_bar(stat = "identity", position = "dodge", width = 0.7) +scale_y_continuous(breaks = seq(-0.1,0.4,0.02),labels = scales::p scale_fill_brewer(palette = "Set1", 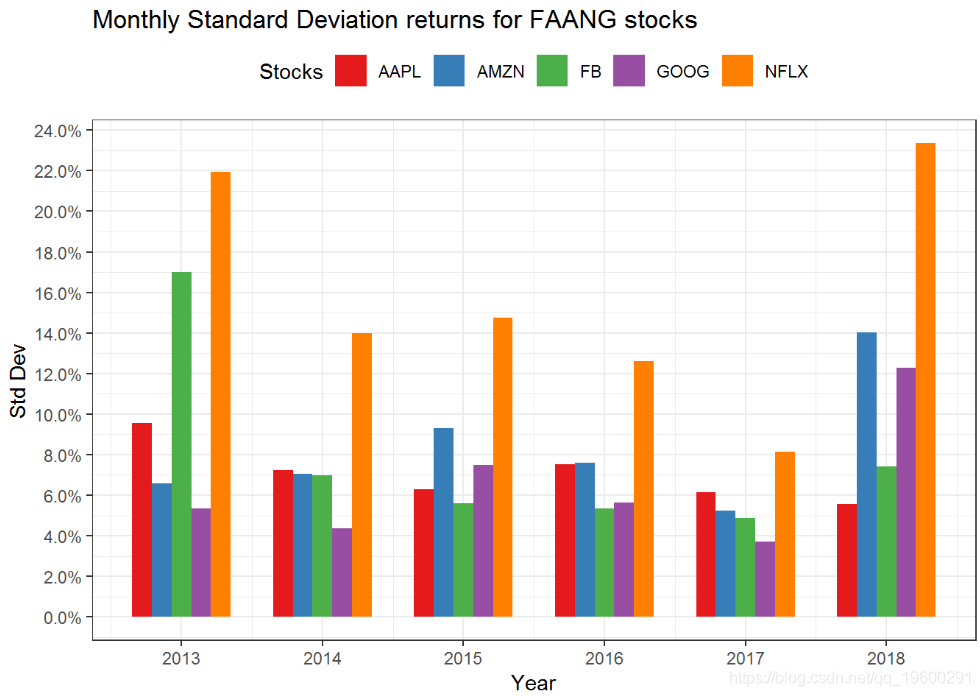
计算多只股票的协方差和相关性
另一个重要的统计计算是股票的相关性和协方差。为了计算这些统计数据,我们需要修改数据。我们将其转换为xts对象。
协方差表
#计算协方差tk_xts(silent = TRUE) %>%cov()## AAPL AMZN FB GOOG NFLX
## AAPL 5.254736e-03 0.001488462 0.000699818 0.0007420307 -1.528193e-05
## AMZN 1.488462e-03 0.006399439 0.001418561 0.0028531565 4.754894e-03
## FB 6.998180e-04 0.001418561 0.008091594 0.0013566480 3.458228e-03
## GOOG 7.420307e-04 0.002853157 0.001356648 0.0032287790 3.529245e-03
## NFLX -1.528193e-05 0.004754894 0.003458228 0.0035292451 2.464202e-02相关表
# 计算相关系数%>%tk_xts(silent = TRUE) %>%cor() ## AAPL AMZN FB GOOG NFLX
## AAPL 1.000000000 0.2566795 0.1073230 0.1801471 -0.001342964
## AMZN 0.256679539 1.0000000 0.1971334 0.6276759 0.378644485
## FB 0.107322952 0.1971334 1.0000000 0.2654184 0.244905437
## GOOG 0.180147089 0.6276759 0.2654184 1.0000000 0.395662114
## NFLX -0.001342964 0.3786445 0.2449054 0.3956621 1.000000000我们可以使用corrplot() 包来绘制相关矩阵图。
## corrplot 0.84 loadedcor() %>%corrplot()

最受欢迎的见解
1.用机器学习识别不断变化的股市状况—隐马尔科夫模型(HMM)的应用
2.R语言GARCH-DCC模型和DCC(MVT)建模估计
3.R语言实现 Copula 算法建模依赖性案例分析报告
4.R语言COPULAS和金融时间序列数据VaR分析
5.R语言多元COPULA GARCH 模型时间序列预测
6.用R语言实现神经网络预测股票实例
7.r语言预测波动率的实现:ARCH模型与HAR-RV模型
8.R语言如何做马尔科夫转换模型markov switching model
9.matlab使用Copula仿真优化市场风险
这篇关于拓端tecdat|基于R语言股票市场收益的统计可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



