本文主要是介绍较真儿学源码系列-PowerJob启动流程源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PowerJob版本:4.3.2-main。
1 简介
PowerJob是全新一代的分布式任务调度与计算框架,官网地址:http://www.powerjob.tech/。其中介绍了PowerJob的功能特点,以及与其他调度框架的对比,这里就不再赘述了。
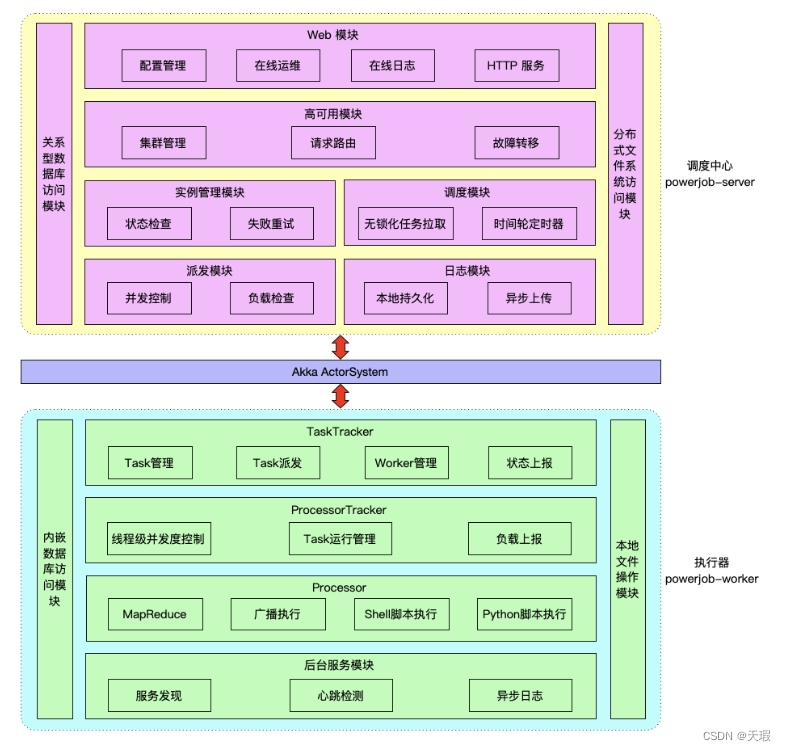
以上是PowerJob的架构图,取自官网。可以看出,PowerJob是典型的客户端/服务端交互的架构(但是在PowerJob中却没有一般分布式中间件会有的注册中心)。本文就从启动流程出发,来一起探究下PowerJob在启动阶段中都做了些什么动作。
2 服务端
既然要看启动流程源码,那么首先就来看下启动类。PowerJob依赖于Spring Boot,启动类为PowerJobServerApplication:
/*** powerjob-server entry** @author tjq* @since 2020/3/29*/
@Slf4j
@EnableScheduling
@SpringBootApplication
public class PowerJobServerApplication {private static final String TIPS = "\n\n" +"******************* PowerJob Tips *******************\n" +"如果应用无法启动,我们建议您仔细阅读以下文档来解决:\n" +"if server can't startup, we recommend that you read the documentation to find a solution:\n" +"https://www.yuque.com/powerjob/guidence/problem\n" +"******************* PowerJob Tips *******************\n\n";public static void main(String[] args) {pre();// Start SpringBoot application.try {SpringApplication.run(PowerJobServerApplication.class, args);} catch (Throwable t) {log.error(TIPS);throw t;}}private static void pre() {log.info(TIPS);PropertyUtils.init();}}/*** 加载配置文件** @author tjq* @since 2020/5/18*/
@Slf4j
public class PropertyUtils {private static final Properties PROPERTIES = new Properties();public static Properties getProperties() {return PROPERTIES;}public static void init() {URL propertiesURL = PropertyUtils.class.getClassLoader().getResource("application.properties");Objects.requireNonNull(propertiesURL);try (InputStream is = propertiesURL.openStream()) {PROPERTIES.load(is);} catch (Exception e) {ExceptionUtils.rethrow(e);}}
}
其中pre方法只是将配置文件内容加载进Properties缓存中。
既然启动类看不出什么逻辑,那么接下来就来看下服务端启动时有没有什么初始化的逻辑:
2.1 PowerTransportService
PowerTransportService类是用作数据传输服务的,也就是客户端和服务端之间的通信。其实现了InitializingBean接口,所以查看下其afterPropertiesSet方法的实现:
/*** PowerTransportService:*/
@Override
public void afterPropertiesSet() throws Exception {log.info("[PowerTransportService] start to initialize whole PowerTransportService!");log.info("[PowerTransportService] activeProtocols: {}", activeProtocols);if (StringUtils.isEmpty(activeProtocols)) {throw new IllegalArgumentException("activeProtocols can't be empty!");}for (String protocol : activeProtocols.split(OmsConstant.COMMA)) {try {final int port = parseProtocolPort(protocol);//初始化网络通讯initRemoteFrameWork(protocol, port);} catch (Throwable t) {log.error("[PowerTransportService] initialize protocol[{}] failed. If you don't need to use this protocol, you can turn it off by 'oms.transporter.active.protocols'", protocol);ExceptionUtils.rethrow(t);}}//选择默认的通信协议,默认为HTTPchoseDefault();log.info("[PowerTransportService] initialize successfully!");log.info("[PowerTransportService] ALL_PROTOCOLS: {}", protocolName2Info);
}/*** 第18行代码处:*/
private void initRemoteFrameWork(String protocol, int port) {// 从构造器注入改为从 applicationContext 获取来避免循环依赖//获取所有注解了@Actor的beanfinal Map<String, Object> beansWithAnnotation = applicationContext.getBeansWithAnnotation(Actor.class);log.info("[PowerTransportService] find Actor num={},names={}", beansWithAnnotation.size(), beansWithAnnotation.keySet());Address address = new Address().setHost(NetUtils.getLocalHost()).setPort(port);EngineConfig engineConfig = new EngineConfig().setServerType(ServerType.SERVER).setType(protocol.toUpperCase()).setBindAddress(address).setActorList(Lists.newArrayList(beansWithAnnotation.values()));log.info("[PowerTransportService] start to initialize RemoteEngine[type={},address={}]", protocol, address);RemoteEngine re = new PowerJobRemoteEngine();//初始化网络层final EngineOutput engineOutput = re.start(engineConfig);log.info("[PowerTransportService] start RemoteEngine[type={},address={}] successfully", protocol, address);//放入相关缓存中this.engines.add(re);this.protocolName2Info.put(protocol, new ProtocolInfo(protocol, address.toFullAddress(), engineOutput.getTransporter()));
}其中需要说明的一点是:PowerJob网络层使用的协议是Akka或Vert.x:
- Akka是一个在JVM上构建高并发、分布式和弹性消息驱动的应用程序。其是用Scala写的,使用到了Actor模型;
- 而Vert.x是一个在JVM上构建响应式应用程序的工具包,其底层基于Netty(之前我对Netty的源码也进行过分析,感兴趣的话可以查看《较真儿学源码系列-Netty核心流程源码分析》)。
PowerJob屏蔽了底层的实现,用两个自定义的注解@Actor和@Handler进行了统一的封装。客户端传过来的请求会自动跳转到@Actor注解的类、@Handler注解的方法上。拿客户端发送心跳给服务端的逻辑为例,流程如下所示:
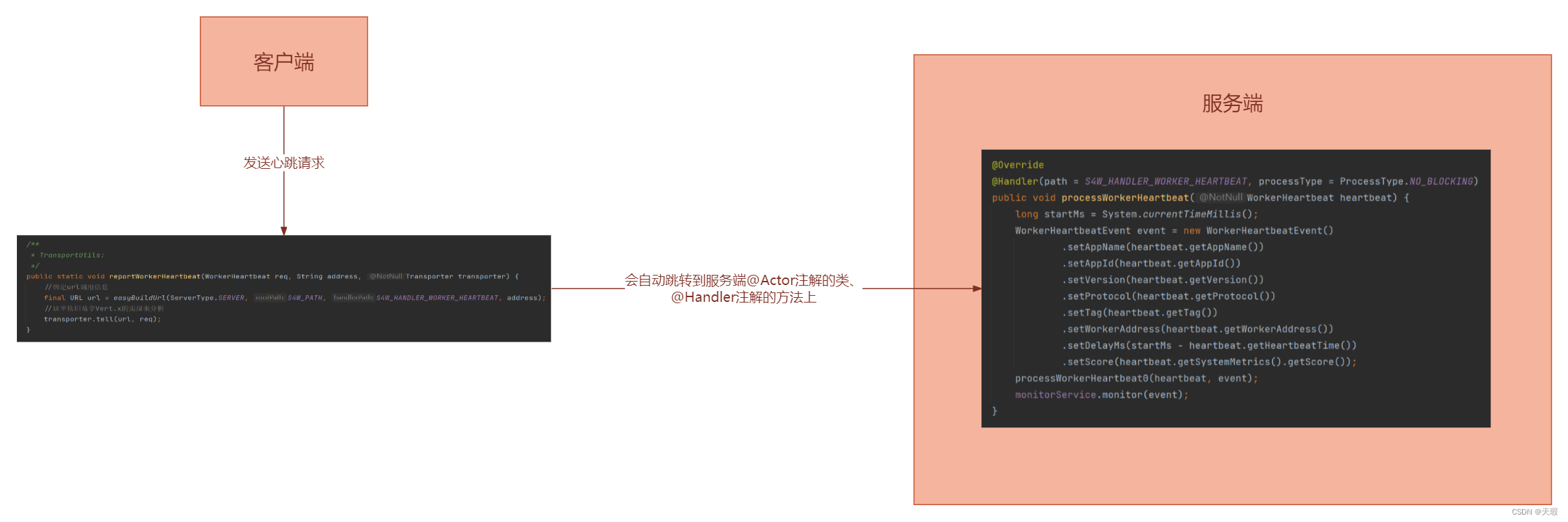
下面就来继续看下,在上面的第53行代码处。PowerJob是如何完成这个绑定的:
/*** PowerJobRemoteEngine:*/
@Override
public EngineOutput start(EngineConfig engineConfig) {final String engineType = engineConfig.getType();EngineOutput engineOutput = new EngineOutput();log.info("[PowerJobRemoteEngine] [{}] start remote engine with config: {}", engineType, engineConfig);//获取所有@Actor的类,和其中注解了@Handler的方法List<ActorInfo> actorInfos = ActorFactory.load(engineConfig.getActorList());//遍历获取指定协议的CSInitializercsInitializer = CSInitializerFactory.build(engineType);String type = csInitializer.type();Stopwatch sw = Stopwatch.createStarted();log.info("[PowerJobRemoteEngine] [{}] try to startup CSInitializer[type={}]", engineType, type);//CsInitializer初始化,这里以Vert.x为例,查看下其实现csInitializer.init(new CSInitializerConfig().setBindAddress(engineConfig.getBindAddress()).setServerType(engineConfig.getServerType()));// 构建通讯器Transporter transporter = csInitializer.buildTransporter();engineOutput.setTransporter(transporter);log.info("[PowerJobRemoteEngine] [{}] start to bind Handler", engineType);actorInfos.forEach(actor -> actor.getHandlerInfos().forEach(handlerInfo -> log.info("[PowerJobRemoteEngine] [{}] PATH={}, handler={}", engineType, handlerInfo.getLocation().toPath(), handlerInfo.getMethod())));// 绑定 handlercsInitializer.bindHandlers(actorInfos);log.info("[PowerJobRemoteEngine] [{}] startup successfully, cost: {}", engineType, sw);return engineOutput;
}/*** ActorFactory:* 第11行代码处:*/
static List<ActorInfo> load(List<Object> actorList) {List<ActorInfo> actorInfos = Lists.newArrayList();actorList.forEach(actor -> {final Class<?> clz = actor.getClass();try {final Actor anno = clz.getAnnotation(Actor.class);ActorInfo actorInfo = new ActorInfo().setActor(actor).setAnno(anno);//获取所有注解了@Handler的方法,并缓存进handlerInfos里actorInfo.setHandlerInfos(loadHandlerInfos4Actor(actorInfo));actorInfos.add(actorInfo);} catch (Throwable t) {log.error("[ActorFactory] process Actor[{}] failed!", clz);ExceptionUtils.rethrow(t);}});return actorInfos;
}/*** CSInitializerFactory:* 第13行代码处:*/
static CSInitializer build(String targetType) {Reflections reflections = new Reflections(OmsConstant.PACKAGE);//使用Reflections反射获取CSInitializer的实现类,即AkkaCSInitializer和HttpVertxCSInitializer。Reflections的介绍和简单使用请看https://blog.csdn.net/weixin_30342639/article/details/124521467Set<Class<? extends CSInitializer>> cSInitializerClzSet = reflections.getSubTypesOf(CSInitializer.class);log.info("[CSInitializerFactory] scan subTypeOf CSInitializer: {}", cSInitializerClzSet);for (Class<? extends CSInitializer> clz : cSInitializerClzSet) {try {CSInitializer csInitializer = clz.getDeclaredConstructor().newInstance();//获取类型:AKKA/HTTPString type = csInitializer.type();log.info("[CSInitializerFactory] new instance for CSInitializer[{}] successfully, type={}, object: {}", clz, type, csInitializer);//遍历获取指定协议的CSInitializerif (targetType.equalsIgnoreCase(type)) {return csInitializer;}} catch (Exception e) {log.error("[CSInitializerFactory] new instance for CSInitializer[{}] failed, maybe you should provide a non-parameter constructor", clz);ExceptionUtils.rethrow(e);}}throw new PowerJobException(String.format("can't load CSInitializer[%s], ensure your package name start with 'tech.powerjob' and import the dependencies!", targetType));
}/*** HttpVertxCSInitializer:* 第21行代码处:* 这里也就是在做Vert.x的初始化工作,不再继续深入了*/
@Override
public void init(CSInitializerConfig config) {this.config = config;vertx = VertxInitializer.buildVertx();httpServer = VertxInitializer.buildHttpServer(vertx);httpClient = VertxInitializer.buildHttpClient(vertx);
}/*** 第34行代码处:*/
@Override
@SneakyThrows
public void bindHandlers(List<ActorInfo> actorInfos) {Router router = Router.router(vertx);// 处理请求响应router.route().handler(BodyHandler.create());actorInfos.forEach(actorInfo -> {Optional.ofNullable(actorInfo.getHandlerInfos()).orElse(Collections.emptyList()).forEach(handlerInfo -> {//获取目标地址,即@Actor和@Handler注解上path的拼接String handlerHttpPath = handlerInfo.getLocation().toPath();ProcessType processType = handlerInfo.getAnno().processType();Handler<RoutingContext> routingContextHandler = buildRequestHandler(actorInfo, handlerInfo);//添加路由绑定Route route = router.post(handlerHttpPath);if (processType == ProcessType.BLOCKING) {//绑定阻塞调用handlerroute.blockingHandler(routingContextHandler, false);} else {//绑定非阻塞调用handlerroute.handler(routingContextHandler);}});});// 启动 vertx http serverfinal int port = config.getBindAddress().getPort();final String host = config.getBindAddress().getHost();httpServer.requestHandler(router).exceptionHandler(e -> log.error("[PowerJob] unknown exception in Actor communication!", e)).listen(port, host).toCompletionStage().toCompletableFuture().get(1, TimeUnit.MINUTES);log.info("[PowerJobRemoteEngine] startup vertx HttpServer successfully!");
}/*** 第127行代码处:*/
private Handler<RoutingContext> buildRequestHandler(ActorInfo actorInfo, HandlerInfo handlerInfo) {Method method = handlerInfo.getMethod();Optional<Class<?>> powerSerializeClz = RemoteUtils.findPowerSerialize(method.getParameterTypes());// 内部框架,严格模式,绑定失败直接报错if (!powerSerializeClz.isPresent()) {throw new PowerJobException("can't find any 'PowerSerialize' object in handler args: " + handlerInfo.getLocation());}//这里实际上是注册了一个事件驱动的回调函数(Netty的玩法),当有请求过来的时候,会走到下面的代码里return ctx -> {final RequestBody body = ctx.body();final Object convertResult = body.asPojo(powerSerializeClz.get());try {//这里通过反射调用相关的@Handler注解的方法Object response = method.invoke(actorInfo.getActor(), convertResult);if (response != null) {if (response instanceof String) {ctx.end((String) response);} else {ctx.json(JsonObject.mapFrom(response));}return;}ctx.end();} catch (Throwable t) {// 注意这里是框架实际运行时,日志输出用标准 PowerJob 格式log.error("[PowerJob] invoke Handler[{}] failed!", handlerInfo.getLocation(), t);ctx.fail(HttpResponseStatus.INTERNAL_SERVER_ERROR.code(), t);}};
}通过上面的buildRequestHandler方法可知,当Vert.x接收到客户端的请求时,会调用到一个回调函数。而这个回调函数会最终通过反射的方式调用到自定义的@Handler注解的方法中来。
上面只是完成了初始化和绑定的操作,还缺少具体调用时候的逻辑(这里属于一个整体流程,所以就一起分析了)。继续拿发送心跳为例,调用的方法是:TransportUtils.reportWorkerHeartbeat:
/*** TransportUtils:*/
public static void reportWorkerHeartbeat(WorkerHeartbeat req, String address, Transporter transporter) {//绑定url调用信息final URL url = easyBuildUrl(ServerType.SERVER, S4W_PATH, S4W_HANDLER_WORKER_HEARTBEAT, address);//这里依旧是拿Vert.x的实现来分析transporter.tell(url, req);
}/*** VertxTransporter:* 第8行代码处:*/
@Override
public void tell(URL url, PowerSerializable request) {post(url, request, null);
}/*** 这里就涉及到Vert.x的具体调用细节了,不再深入*/
@SuppressWarnings("unchecked")
private <T> CompletionStage<T> post(URL url, PowerSerializable request, Class<T> clz) {final String host = url.getAddress().getHost();final int port = url.getAddress().getPort();final String path = url.getLocation().toPath();RequestOptions requestOptions = new RequestOptions().setMethod(HttpMethod.POST).setHost(host).setPort(port).setURI(path);// 获取远程服务器的HTTP连接Future<HttpClientRequest> httpClientRequestFuture = httpClient.request(requestOptions);// 转换 -> 发送请求获取响应Future<HttpClientResponse> responseFuture = httpClientRequestFuture.compose(httpClientRequest ->httpClientRequest.putHeader(HttpHeaderNames.CONTENT_TYPE, HttpHeaderValues.APPLICATION_JSON).send(JsonObject.mapFrom(request).toBuffer()));return responseFuture.compose(httpClientResponse -> {// throw exceptionfinal int statusCode = httpClientResponse.statusCode();if (statusCode != HttpResponseStatus.OK.code()) {// CompletableFuture.get() 时会传递抛出该异常throw new RemotingException(String.format("request [host:%s,port:%s,url:%s] failed, status: %d, msg: %s",host, port, path, statusCode, httpClientResponse.statusMessage()));}return httpClientResponse.body().compose(x -> {if (clz == null) {return Future.succeededFuture(null);}if (clz.equals(String.class)) {return Future.succeededFuture((T) x.toString());}return Future.succeededFuture(x.toJsonObject().mapTo(clz));});}).toCompletionStage();
}当客户端往服务端发送完请求后,服务端接受到相关的请求,会调用到相应的回调函数,从而最终调用到@Handler注解的方法。整个流程就串起来了。
2.2. InstanceMetadataService
同PowerTransportService类一样,InstanceMetadataService也实现了InitializingBean接口,所以查看下其afterPropertiesSet方法的实现:
/*** InstanceMetadataService:*/
@Override
public void afterPropertiesSet() throws Exception {instanceId2JobInfoCache = CacheBuilder.newBuilder().concurrencyLevel(CACHE_CONCURRENCY_LEVEL).maximumSize(instanceMetadataCacheSize).softValues().build();
}其中只是初始化了一个本地缓存,没有多余的逻辑。
2.3 CoreScheduleTaskManager
CoreScheduleTaskManager也实现了InitializingBean接口,查看下其afterPropertiesSet方法的实现:
/*** CoreScheduleTaskManager:*/
@SuppressWarnings("AlibabaAvoidManuallyCreateThread")
@Override
public void afterPropertiesSet() {// 定时调度coreThreadContainer.add(new Thread(new LoopRunnable("ScheduleCronJob", PowerScheduleService.SCHEDULE_RATE, () -> powerScheduleService.scheduleNormalJob(TimeExpressionType.CRON)), "Thread-ScheduleCronJob"));coreThreadContainer.add(new Thread(new LoopRunnable("ScheduleDailyTimeIntervalJob", PowerScheduleService.SCHEDULE_RATE, () -> powerScheduleService.scheduleNormalJob(TimeExpressionType.DAILY_TIME_INTERVAL)), "Thread-ScheduleDailyTimeIntervalJob"));coreThreadContainer.add(new Thread(new LoopRunnable("ScheduleCronWorkflow", PowerScheduleService.SCHEDULE_RATE, powerScheduleService::scheduleCronWorkflow), "Thread-ScheduleCronWorkflow"));coreThreadContainer.add(new Thread(new LoopRunnable("ScheduleFrequentJob", PowerScheduleService.SCHEDULE_RATE, powerScheduleService::scheduleFrequentJob), "Thread-ScheduleFrequentJob"));// 数据清理coreThreadContainer.add(new Thread(new LoopRunnable("CleanWorkerData", PowerScheduleService.SCHEDULE_RATE, powerScheduleService::cleanData), "Thread-CleanWorkerData"));// 状态检查coreThreadContainer.add(new Thread(new LoopRunnable("CheckRunningInstance", InstanceStatusCheckService.CHECK_INTERVAL, instanceStatusCheckService::checkRunningInstance), "Thread-CheckRunningInstance"));coreThreadContainer.add(new Thread(new LoopRunnable("CheckWaitingDispatchInstance", InstanceStatusCheckService.CHECK_INTERVAL, instanceStatusCheckService::checkWaitingDispatchInstance), "Thread-CheckWaitingDispatchInstance"));coreThreadContainer.add(new Thread(new LoopRunnable("CheckWaitingWorkerReceiveInstance", InstanceStatusCheckService.CHECK_INTERVAL, instanceStatusCheckService::checkWaitingWorkerReceiveInstance), "Thread-CheckWaitingWorkerReceiveInstance"));coreThreadContainer.add(new Thread(new LoopRunnable("CheckWorkflowInstance", InstanceStatusCheckService.CHECK_INTERVAL, instanceStatusCheckService::checkWorkflowInstance), "Thread-CheckWorkflowInstance"));coreThreadContainer.forEach(Thread::start);
}可以看到,其中初始化了一堆的定时任务。从中挑几个定时任务来分析下:
2.3.1 ScheduleCronJob/ScheduleDailyTimeIntervalJob
/*** PowerScheduleService:*/
public void scheduleNormalJob(TimeExpressionType timeExpressionType) {long start = System.currentTimeMillis();// 调度 CRON 表达式 JOBtry {//获取在PowerJob控制台配置的appId,也就是服务id(PowerJob会使用数据库来存储服务、实例等相关数据。在进行一些操作前,会先落库,然后再执行。以此避免相关操作丢失的情况出现)final List<Long> allAppIds = appInfoRepository.listAppIdByCurrentServer(transportService.defaultProtocol().getAddress());if (CollectionUtils.isEmpty(allAppIds)) {log.info("[NormalScheduler] current server has no app's job to schedule.");return;}scheduleNormalJob0(timeExpressionType, allAppIds);} catch (Exception e) {log.error("[NormalScheduler] schedule cron job failed.", e);}long cost = System.currentTimeMillis() - start;log.info("[NormalScheduler] {} job schedule use {} ms.", timeExpressionType, cost);if (cost > SCHEDULE_RATE) {log.warn("[NormalScheduler] The database query is using too much time({}ms), please check if the database load is too high!", cost);}
}/*** 第14行代码处:* 调度普通服务端计算表达式类型(CRON、DAILY_TIME_INTERVAL)的任务** @param timeExpressionType 表达式类型* @param appIds appIds*/
private void scheduleNormalJob0(TimeExpressionType timeExpressionType, List<Long> appIds) {long nowTime = System.currentTimeMillis();long timeThreshold = nowTime + 2 * SCHEDULE_RATE;//分组执行Lists.partition(appIds, MAX_APP_NUM).forEach(partAppIds -> {try {// 查询条件:任务开启 + 使用CRON表达调度时间 + 指定appId + 即将需要调度执行//获取在PowerJob控制台配置的执行任务List<JobInfoDO> jobInfos = jobInfoRepository.findByAppIdInAndStatusAndTimeExpressionTypeAndNextTriggerTimeLessThanEqual(partAppIds, SwitchableStatus.ENABLE.getV(), timeExpressionType.getV(), timeThreshold);if (CollectionUtils.isEmpty(jobInfos)) {return;}// 1. 批量写日志表Map<Long, Long> jobId2InstanceId = Maps.newHashMap();log.info("[NormalScheduler] These {} jobs will be scheduled: {}.", timeExpressionType.name(), jobInfos);jobInfos.forEach(jobInfo -> {//实例表进行落库(任务和实例的关系为:每执行一次任务会生成一个实例)Long instanceId = instanceService.create(jobInfo.getId(), jobInfo.getAppId(), jobInfo.getJobParams(), null, null, jobInfo.getNextTriggerTime()).getInstanceId();jobId2InstanceId.put(jobInfo.getId(), instanceId);});instanceInfoRepository.flush();// 2. 推入时间轮中等待调度执行(对时间轮代码的分析请查看https://blog.csdn.net/weixin_30342639/article/details/132732836)jobInfos.forEach(jobInfoDO -> {Long instanceId = jobId2InstanceId.get(jobInfoDO.getId());//获取下次执行时间long targetTriggerTime = jobInfoDO.getNextTriggerTime();long delay = 0;if (targetTriggerTime < nowTime) {log.warn("[Job-{}] schedule delay, expect: {}, current: {}", jobInfoDO.getId(), targetTriggerTime, System.currentTimeMillis());} else {//计算距离下次执行时间所需要延迟的时间delay = targetTriggerTime - nowTime;}//任务实例推入时间轮,等待被执行InstanceTimeWheelService.schedule(instanceId, delay, () -> dispatchService.dispatch(jobInfoDO, instanceId, Optional.empty(), Optional.empty()));});// 3. 计算下一次调度时间(忽略5S内的重复执行,即CRON模式下最小的连续执行间隔为 SCHEDULE_RATE ms)jobInfos.forEach(jobInfoDO -> {try {//重新计算下次执行时间,并落库//这里会用到策略模式,不同类型的任务(Cron/固定频率/每日固定间隔)会有不同的计算方式,具体不再深入分析,感兴趣可自行查看refreshJob(timeExpressionType, jobInfoDO);} catch (Exception e) {log.error("[Job-{}] refresh job failed.", jobInfoDO.getId(), e);}});jobInfoRepository.flush();} catch (Exception e) {log.error("[NormalScheduler] schedule {} job failed.", timeExpressionType.name(), e);}});
}在上面第76行代码处,当任务推入到时间轮之后(对时间轮代码的分析请查看《较真儿学源码系列-PowerJob时间轮源码分析》),等到需要被执行的时候,会调用到DispatchService.dispatch方法来派发任务:
/*** DispatchService:* 将任务从Server派发到Worker(TaskTracker)* 只会派发当前状态为等待派发的任务实例* *************************************************** 2021-02-03 modify by Echo009* 1、移除参数 当前运行次数、工作流实例ID、实例参数* 更改为从当前任务实例中获取获取以上信息* 2、移除运行次数相关的(runningTimes)处理逻辑* 迁移至 {@link InstanceManager#updateStatus} 中处理* **************************************************** @param jobInfo 任务的元信息* @param instanceId 任务实例ID* @param instanceInfoOptional 任务实例信息,可选* @param overloadOptional 超载信息,可选*/
@UseCacheLock(type = "processJobInstance", key = "#jobInfo.getMaxInstanceNum() > 0 || T(tech.powerjob.common.enums.TimeExpressionType).FREQUENT_TYPES.contains(#jobInfo.getTimeExpressionType()) ? #jobInfo.getId() : #instanceId", concurrencyLevel = 1024)
public void dispatch(JobInfoDO jobInfo, Long instanceId, Optional<InstanceInfoDO> instanceInfoOptional, Optional<Holder<Boolean>> overloadOptional) {// 允许从外部传入实例信息,减少 io 次数// 检查当前任务是否被取消//获取实例InstanceInfoDO instanceInfo = instanceInfoOptional.orElseGet(() -> instanceInfoRepository.findByInstanceId(instanceId));Long jobId = instanceInfo.getJobId();//...// 任务信息已经被删除if (jobInfo.getId() == null) {log.warn("[Dispatcher-{}|{}] cancel dispatch due to job(id={}) has been deleted!", jobId, instanceId, jobId);instanceManager.processFinishedInstance(instanceId, instanceInfo.getWfInstanceId(), FAILED, "can't find job by id " + jobId);return;}Date now = new Date();String dbInstanceParams = instanceInfo.getInstanceParams() == null ? "" : instanceInfo.getInstanceParams();log.info("[Dispatcher-{}|{}] start to dispatch job: {};instancePrams: {}.", jobId, instanceId, jobInfo, dbInstanceParams);// 查询当前运行的实例数long current = System.currentTimeMillis();Integer maxInstanceNum = jobInfo.getMaxInstanceNum();// 秒级任务只派发到一台机器,具体的 maxInstanceNum 由 TaskTracker 控制if (TimeExpressionType.FREQUENT_TYPES.contains(jobInfo.getTimeExpressionType())) {maxInstanceNum = 1;}//...// 获取当前最合适的 worker 列表List<WorkerInfo> suitableWorkers = workerClusterQueryService.getSuitableWorkers(jobInfo);//...// 判断是否超载,在所有可用 worker 超载的情况下直接跳过当前任务suitableWorkers = filterOverloadWorker(suitableWorkers);//...//获取worker ipList<String> workerIpList = suitableWorkers.stream().map(WorkerInfo::getAddress).collect(Collectors.toList());// 构造任务调度请求ServerScheduleJobReq req = constructServerScheduleJobReq(jobInfo, instanceInfo, workerIpList);// 发送请求(不可靠,需要一个后台线程定期轮询状态)//只取第一个workerWorkerInfo taskTracker = suitableWorkers.get(0);String taskTrackerAddress = taskTracker.getAddress();URL workerUrl = ServerURLFactory.dispatchJob2Worker(taskTrackerAddress);transportService.tell(taskTracker.getProtocol(), workerUrl, req);log.info("[Dispatcher-{}|{}] send schedule request to TaskTracker[protocol:{},address:{}] successfully: {}.", jobId, instanceId, taskTracker.getProtocol(), taskTrackerAddress, req);// 修改状态//修改实例表状态instanceInfoRepository.update4TriggerSucceed(instanceId, WAITING_WORKER_RECEIVE.getV(), current, taskTrackerAddress, now, instanceInfo.getStatus());// 装载缓存instanceMetadataService.loadJobInfo(instanceId, jobInfo);
}/*** InstanceManager:* 第31行代码处:* 收尾完成的任务实例** @param instanceId 任务实例ID* @param wfInstanceId 工作流实例ID,非必须* @param status 任务状态,有 成功/失败/手动停止* @param result 执行结果*/
public void processFinishedInstance(Long instanceId, Long wfInstanceId, InstanceStatus status, String result) {log.info("[Instance-{}] process finished, final status is {}.", instanceId, status.name());// 上报日志数据//时间轮延迟执行HashedWheelTimerHolder.INACCURATE_TIMER.schedule(() -> instanceLogService.sync(instanceId), 60, TimeUnit.SECONDS);// workflow 特殊处理if (wfInstanceId != null) {// 手动停止在工作流中也认为是失败(理论上不应该发生)workflowInstanceManager.move(wfInstanceId, instanceId, status, result);}// 告警if (status == InstanceStatus.FAILED) {alert(instanceId, result);}// 主动移除缓存,减小内存占用instanceMetadataService.invalidateJobInfo(instanceId);
}/*** InstanceLogService:* 第96行代码处:* 将本地的任务实例运行日志同步到 mongoDB 存储,在任务执行结束后异步执行** @param instanceId 任务实例ID*/
@Async(PJThreadPool.BACKGROUND_POOL)
public void sync(Long instanceId) {Stopwatch sw = Stopwatch.createStarted();try {// 先持久化到本地文件File stableLogFile = genStableLogFile(instanceId);// 将文件推送到 MongoDBif (gridFsManager.available()) {try {gridFsManager.store(stableLogFile, GridFsManager.LOG_BUCKET, genMongoFileName(instanceId));log.info("[InstanceLog-{}] push local instanceLogs to mongoDB succeed, using: {}.", instanceId, sw.stop());} catch (Exception e) {log.warn("[InstanceLog-{}] push local instanceLogs to mongoDB failed.", instanceId, e);}}} catch (Exception e) {log.warn("[InstanceLog-{}] sync local instanceLogs failed.", instanceId, e);}// 删除本地数据库数据try {instanceId2LastReportTime.remove(instanceId);CommonUtils.executeWithRetry0(() -> localInstanceLogRepository.deleteByInstanceId(instanceId));log.info("[InstanceLog-{}] delete local instanceLog successfully.", instanceId);} catch (Exception e) {log.warn("[InstanceLog-{}] delete local instanceLog failed.", instanceId, e);}
}/*** WorkerClusterQueryService:* 第50行代码处:* get worker for job** @param jobInfo job* @return worker cluster info, sorted by metrics desc*/
public List<WorkerInfo> getSuitableWorkers(JobInfoDO jobInfo) {//获取该集群所有的机器信息List<WorkerInfo> workers = Lists.newLinkedList(getWorkerInfosByAppId(jobInfo.getAppId()).values());workers.removeIf(workerInfo -> filterWorker(workerInfo, jobInfo));DispatchStrategy dispatchStrategy = DispatchStrategy.of(jobInfo.getDispatchStrategy());switch (dispatchStrategy) {case RANDOM://随机的方式就是打乱顺序Collections.shuffle(workers);break;case HEALTH_FIRST://健康优先的方式需要计算下得分,按得分高低排序workers.sort((o1, o2) -> o2.getSystemMetrics().calculateScore() - o1.getSystemMetrics().calculateScore());break;default:// do nothing}// 限定集群大小(0代表不限制)if (!workers.isEmpty() && jobInfo.getMaxWorkerCount() > 0 && workers.size() > jobInfo.getMaxWorkerCount()) {workers = workers.subList(0, jobInfo.getMaxWorkerCount());}return workers;
}/*** SystemMetrics:* 第171行代码处:* Calculate score, based on CPU and memory info.** @return score*/
public int calculateScore() {if (score > 0) {return score;}// Memory is vital to TaskTracker, so we set the multiplier factor as 2.//未使用内存指标的权重为2double memScore = (jvmMaxMemory - jvmUsedMemory) * 2;// Calculate the remaining load of CPU. Multiplier is set as 1.//剩余可用cpu数的权重为1double cpuScore = cpuProcessors - cpuLoad;// Windows can not fetch CPU load, set cpuScore as 1.//Windows系统拿不到cpu使用数,所以cpu得分设置为1if (cpuScore > cpuProcessors) {cpuScore = 1;}//最终得分就是内存得分+cpu得分score = (int) (memScore + cpuScore);return score;
}/*** ServerURLFactory:* 第69行代码处:*/
public static URL dispatchJob2Worker(String address) {return simileBuild(address, ServerType.WORKER, WORKER_PATH, WTT_HANDLER_RUN_JOB);
}在上面第216行代码处会将请求跳转到WorkerActor.onReceiveServerScheduleJobReq方法:
/*** WorkerActor:*/
@Handler(path = WTT_HANDLER_RUN_JOB)
public void onReceiveServerScheduleJobReq(ServerScheduleJobReq req) {taskTrackerActor.onReceiveServerScheduleJobReq(req);
}/*** TaskTrackerActor:* 服务器任务调度处理器*/
@Handler(path = WTT_HANDLER_RUN_JOB)
public void onReceiveServerScheduleJobReq(ServerScheduleJobReq req) {log.debug("[TaskTrackerActor] server schedule job by request: {}.", req);Long instanceId = req.getInstanceId();// 区分轻量级任务模型以及重量级任务模型//单机执行的OpenApi/Corn/工作流是轻量级任务,其他的是重量级任务if (isLightweightTask(req)) {final LightTaskTracker taskTracker = LightTaskTrackerManager.getTaskTracker(instanceId);if (taskTracker != null) {log.warn("[TaskTrackerActor] LightTaskTracker({}) for instance(id={}) already exists.", taskTracker, instanceId);return;}// 判断是否已经 overloadif (LightTaskTrackerManager.currentTaskTrackerSize() >= workerRuntime.getWorkerConfig().getMaxLightweightTaskNum() * LightTaskTrackerManager.OVERLOAD_FACTOR) {// ignore this requestlog.warn("[TaskTrackerActor] this worker is overload,ignore this request(instanceId={}),current size = {}!", instanceId, LightTaskTrackerManager.currentTaskTrackerSize());return;}if (LightTaskTrackerManager.currentTaskTrackerSize() >= workerRuntime.getWorkerConfig().getMaxLightweightTaskNum()) {log.warn("[TaskTrackerActor] this worker will be overload soon,current size = {}!", LightTaskTrackerManager.currentTaskTrackerSize());}// 创建轻量级任务//在轻量级本地缓存中添加TaskTrackerLightTaskTrackerManager.atomicCreateTaskTracker(instanceId, ignore -> LightTaskTracker.create(req, workerRuntime));} else {HeavyTaskTracker taskTracker = HeavyTaskTrackerManager.getTaskTracker(instanceId);if (taskTracker != null) {log.warn("[TaskTrackerActor] HeavyTaskTracker({}) for instance(id={}) already exists.", taskTracker, instanceId);return;}// 判断是否已经 overloadif (HeavyTaskTrackerManager.currentTaskTrackerSize() >= workerRuntime.getWorkerConfig().getMaxHeavyweightTaskNum()) {// ignore this requestlog.warn("[TaskTrackerActor] this worker is overload,ignore this request(instanceId={})! current size = {},", instanceId, HeavyTaskTrackerManager.currentTaskTrackerSize());return;}// 原子创建,防止多实例的存在//在重量级本地缓存中添加TaskTrackerHeavyTaskTrackerManager.atomicCreateTaskTracker(instanceId, ignore -> HeavyTaskTracker.create(req, workerRuntime));}
}由上可以看到,派发任务就是往TaskTracker里添加一条本地缓存。
这里出现了TaskTracker,TaskTracker、ProcessorTracker和Processor的概念直接参考PowerJob作者写过的文章:

这里我们继续分析下上面第51行代码处的HeavyTaskTracker.create方法:
/*** HeavyTaskTracker:* 静态方法创建 TaskTracker** @param req 服务端调度任务请求* @return API/CRON -> CommonTaskTracker, FIX_RATE/FIX_DELAY -> FrequentTaskTracker*/
public static HeavyTaskTracker create(ServerScheduleJobReq req, WorkerRuntime workerRuntime) {try {TimeExpressionType timeExpressionType = TimeExpressionType.valueOf(req.getTimeExpressionType());switch (timeExpressionType) {case FIXED_RATE:case FIXED_DELAY:return new FrequentTaskTracker(req, workerRuntime);default://这里我们分析下CommonTaskTracker构造器的实现return new CommonTaskTracker(req, workerRuntime);}} catch (Exception e) {reportCreateErrorToServer(req, workerRuntime, e);}return null;
}/*** CommonTaskTracker:* 第17行代码处:*/
protected CommonTaskTracker(ServerScheduleJobReq req, WorkerRuntime workerRuntime) {super(req, workerRuntime);
}/*** HeavyTaskTracker:*/
protected HeavyTaskTracker(ServerScheduleJobReq req, WorkerRuntime workerRuntime) {// 初始化成员变量super(req, workerRuntime);// 赋予时间表达式类型instanceInfo.setTimeExpressionType(TimeExpressionType.valueOf(req.getTimeExpressionType()).getV());// 保护性操作instanceInfo.setThreadConcurrency(Math.max(1, instanceInfo.getThreadConcurrency()));this.ptStatusHolder = new ProcessorTrackerStatusHolder(instanceId, req.getMaxWorkerCount(), req.getAllWorkerAddress());this.taskPersistenceService = workerRuntime.getTaskPersistenceService();// 构建缓存taskId2BriefInfo = CacheBuilder.newBuilder().maximumSize(1024).build();// 构建分段锁//SegmentLock是自己实现的ReentrantLock数组(使用数组是为了提高并发度)segmentLock = new SegmentLock(UPDATE_CONCURRENCY);// 子类自定义初始化操作initTaskTracker(req);log.info("[TaskTracker-{}] create TaskTracker successfully.", instanceId);
}/*** CommonTaskTracker:* 第53行代码处:** @param req 服务器调度任务实例运行请求*/
@Override
protected void initTaskTracker(ServerScheduleJobReq req) {// CommonTaskTrackerTimingPool 缩写String poolName = String.format("ctttp-%d", req.getInstanceId()) + "-%d";ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat(poolName).build();this.scheduledPool = Executors.newScheduledThreadPool(2, factory);// 持久化根任务persistenceRootTask();// 开启定时状态检查int delay = Integer.parseInt(System.getProperty(PowerJobDKey.WORKER_STATUS_CHECK_PERIOD, "13"));scheduledPool.scheduleWithFixedDelay(new StatusCheckRunnable(), 3, delay, TimeUnit.SECONDS);// 如果是 MR 任务,则需要启动执行器动态检测装置ExecuteType executeType = ExecuteType.valueOf(req.getExecuteType());if (executeType == ExecuteType.MAP || executeType == ExecuteType.MAP_REDUCE) {scheduledPool.scheduleAtFixedRate(new WorkerDetector(), 1, 1, TimeUnit.MINUTES);}// 最后启动任务派发器,否则会出现 TaskTracker 还未创建完毕 ProcessorTracker 已开始汇报状态的情况scheduledPool.scheduleWithFixedDelay(new Dispatcher(), 10, 5000, TimeUnit.MILLISECONDS);
}/*** 第73行代码处:* 持久化根任务,只有完成持久化才能视为任务开始running(先持久化,再报告server)*/
private void persistenceRootTask() {TaskDO rootTask = new TaskDO();rootTask.setStatus(TaskStatus.WAITING_DISPATCH.getValue());rootTask.setInstanceId(instanceInfo.getInstanceId());rootTask.setTaskId(ROOT_TASK_ID);rootTask.setFailedCnt(0);rootTask.setAddress(workerRuntime.getWorkerAddress());//这里需要留意下,根任务的名称为OMS_ROOT_TASK(ROOT_TASK_NAME)rootTask.setTaskName(TaskConstant.ROOT_TASK_NAME);rootTask.setCreatedTime(System.currentTimeMillis());rootTask.setLastModifiedTime(System.currentTimeMillis());rootTask.setLastReportTime(-1L);rootTask.setSubInstanceId(instanceId);if (taskPersistenceService.save(rootTask)) {log.info("[TaskTracker-{}] create root task successfully.", instanceId);} else {log.error("[TaskTracker-{}] create root task failed.", instanceId);throw new PowerJobException("create root task failed for instance: " + instanceId);}
}在上面第77行代码处、第82行代码处和第86行代码处的initTaskTracker方法中,分别开启了三个定时任务,这里我们主要分析下StatusCheckRunnable和Dispatcher(WorkerDetector放在《较真儿学源码系列-PowerJob MapReduce源码分析》中分析):
2.3.1.1 StatusCheckRunnable
/*** StatusCheckRunnable:*/
@Override
public void run() {try {innerRun();} catch (Exception e) {log.warn("[TaskTracker-{}] status checker execute failed, please fix the bug (@tjq)!", instanceId, e);}
}/*** 第7行代码处:*/
@SuppressWarnings("squid:S3776")
private void innerRun() {//获取任务实例产生的各个Task状态,用于分析任务实例执行情况InstanceStatisticsHolder holder = getInstanceStatisticsHolder(instanceId);long finishedNum = holder.succeedNum + holder.failedNum;long unfinishedNum = holder.waitingDispatchNum + holder.workerUnreceivedNum + holder.receivedNum + holder.runningNum;log.debug("[TaskTracker-{}] status check result: {}", instanceId, holder);//组装上报参数TaskTrackerReportInstanceStatusReq req = new TaskTrackerReportInstanceStatusReq();req.setAppId(workerRuntime.getAppId());req.setJobId(instanceInfo.getJobId());req.setInstanceId(instanceId);req.setWfInstanceId(instanceInfo.getWfInstanceId());req.setTotalTaskNum(finishedNum + unfinishedNum);req.setSucceedTaskNum(holder.succeedNum);req.setFailedTaskNum(holder.failedNum);req.setReportTime(System.currentTimeMillis());req.setStartTime(createTime);req.setSourceAddress(workerRuntime.getWorkerAddress());boolean success = false;String result = null;// 2. 如果未完成任务数为0,判断是否真正结束,并获取真正结束任务的执行结果if (unfinishedNum == 0) {// 数据库中一个任务都没有,说明根任务创建失败,该任务实例失败if (finishedNum == 0) {finished.set(true);result = SystemInstanceResult.TASK_INIT_FAILED;} else {ExecuteType executeType = ExecuteType.valueOf(instanceInfo.getExecuteType());switch (executeType) {// STANDALONE 只有一个任务,完成即结束case STANDALONE:finished.set(true);List<TaskDO> allTask = taskPersistenceService.getAllTask(instanceId, instanceId);if (CollectionUtils.isEmpty(allTask) || allTask.size() > 1) {result = SystemInstanceResult.UNKNOWN_BUG;log.warn("[TaskTracker-{}] there must have some bug in TaskTracker.", instanceId);} else {result = allTask.get(0).getResult();success = allTask.get(0).getStatus() == TaskStatus.WORKER_PROCESS_SUCCESS.getValue();}break;case MAP://...break;default://...}}}// 3. 检查任务实例整体是否超时if (isTimeout()) {finished.set(true);success = false;result = SystemInstanceResult.INSTANCE_EXECUTE_TIMEOUT;}// 4. 执行完毕,报告服务器if (finished.get()) {req.setResult(result);// 上报追加的工作流上下文信息req.setAppendedWfContext(appendedWfContext);req.setInstanceStatus(success ? InstanceStatus.SUCCEED.getV() : InstanceStatus.FAILED.getV());reportFinalStatusThenDestroy(workerRuntime, req);return;}// 5. 未完成,上报状态req.setInstanceStatus(InstanceStatus.RUNNING.getV());TransportUtils.ttReportInstanceStatus(req, workerRuntime.getServerDiscoveryService().getCurrentServerAddress(), workerRuntime.getTransporter());// 6.1 定期检查 -> 重试派发后未确认的任务long currentMS = System.currentTimeMillis();if (holder.workerUnreceivedNum != 0) {taskPersistenceService.getTaskByStatus(instanceId, TaskStatus.DISPATCH_SUCCESS_WORKER_UNCHECK, 100).forEach(uncheckTask -> {long elapsedTime = currentMS - uncheckTask.getLastModifiedTime();if (elapsedTime > DISPATCH_TIME_OUT_MS) {TaskDO updateEntity = new TaskDO();updateEntity.setStatus(TaskStatus.WAITING_DISPATCH.getValue());// 特殊任务只能本机执行if (!TaskConstant.LAST_TASK_NAME.equals(uncheckTask.getTaskName())) {updateEntity.setAddress(RemoteConstant.EMPTY_ADDRESS);}// 失败次数 + 1updateEntity.setFailedCnt(uncheckTask.getFailedCnt() + 1);taskPersistenceService.updateTask(instanceId, uncheckTask.getTaskId(), updateEntity);log.warn("[TaskTracker-{}] task(id={},name={}) try to dispatch again due to unreceived the response from ProcessorTracker.",instanceId, uncheckTask.getTaskId(), uncheckTask.getTaskName());}});}// 6.2 定期检查 -> 重新执行被派发到宕机ProcessorTracker上的任务List<String> disconnectedPTs = ptStatusHolder.getAllDisconnectedProcessorTrackers();if (!disconnectedPTs.isEmpty()) {log.warn("[TaskTracker-{}] some ProcessorTracker disconnected from TaskTracker,their address is {}.", instanceId, disconnectedPTs);if (taskPersistenceService.updateLostTasks(instanceId, disconnectedPTs, true)) {ptStatusHolder.remove(disconnectedPTs);log.warn("[TaskTracker-{}] removed these ProcessorTracker from StatusHolder: {}", instanceId, disconnectedPTs);}}
}上报到服务端的逻辑这里就不再看了(更新instance_info实例表数据)。整体上来说,StatusCheckRunnable的作用就是检查任务的执行情况,并上报到服务端。
2.3.1.2 Dispatcher
/*** Dispatcher:*/
@Override
public void run() {if (finished.get()) {return;}Stopwatch stopwatch = Stopwatch.createStarted();// 1. 获取可以派发任务的 ProcessorTrackerList<String> availablePtIps = ptStatusHolder.getAvailableProcessorTrackers();// 2. 没有可用 ProcessorTracker,本次不派发if (availablePtIps.isEmpty()) {log.debug("[TaskTracker-{}] no available ProcessorTracker now.", instanceId);return;}// 3. 避免大查询,分批派发任务long currentDispatchNum = 0;//这里需要留意下,最大分发次数=可用ProcessorTracker数量*实例并发度*2long maxDispatchNum = availablePtIps.size() * instanceInfo.getThreadConcurrency() * 2L;AtomicInteger index = new AtomicInteger(0);// 4. 循环查询数据库,获取需要派发的任务while (maxDispatchNum > currentDispatchNum) {//每次最多查询100个任务int dbQueryLimit = Math.min(DB_QUERY_LIMIT, (int) maxDispatchNum);//获取等待调度器调度的任务List<TaskDO> needDispatchTasks = taskPersistenceService.getTaskByStatus(instanceId, TaskStatus.WAITING_DISPATCH, dbQueryLimit);currentDispatchNum += needDispatchTasks.size();needDispatchTasks.forEach(task -> {// 获取 ProcessorTracker 地址,如果 Task 中自带了 Address,则使用该 AddressString ptAddress = task.getAddress();if (StringUtils.isEmpty(ptAddress) || RemoteConstant.EMPTY_ADDRESS.equals(ptAddress)) {//否则,从可用ProcessorTracker中取余获取一个ptAddress = availablePtIps.get(index.getAndIncrement() % availablePtIps.size());}//分发任务dispatchTask(task, ptAddress);});// 数量不足 或 查询失败,则终止循环if (needDispatchTasks.size() < dbQueryLimit) {break;}}log.debug("[TaskTracker-{}] dispatched {} tasks,using time {}.", instanceId, currentDispatchNum, stopwatch.stop());
}/*** ProcessorTrackerStatusHolder:* 第14行代码处:* 获取可用 ProcessorTracker 的IP地址*/
public List<String> getAvailableProcessorTrackers() {List<String> result = Lists.newLinkedList();address2Status.forEach((address, ptStatus) -> {if (ptStatus.available()) {result.add(address);}});return result;
}/*** ProcessorTrackerStatus:* 第66行代码处:* 是否可用*/
public boolean available() {// 未曾派发过,默认可用if (!dispatched) {return true;}// 已派发但未收到响应,则不可用if (!connected) {return false;}// 长时间未收到心跳消息,则不可用if (isTimeout()) {return false;}// 留有过多待处理任务,则不可用if (remainTaskNum >= DISPATCH_THRESHOLD) {return false;}// TODO:后续考虑加上机器健康度等信息return true;
}/*** 第91行代码处:* 是否超时(超过一定时间没有收到心跳)*/
public boolean isTimeout() {if (dispatched) {//系统当前时间-上次活跃时间>心跳超时时间return System.currentTimeMillis() - lastActiveTime > HEARTBEAT_TIMEOUT_MS;}// 未曾派发过任务的机器,不用处理return false;
}/*** HeavyTaskTracker:* 第45行代码处:* 派发任务到 ProcessorTracker** @param task 需要被执行的任务* @param processorTrackerAddress ProcessorTracker的地址(IP:Port)*/
protected void dispatchTask(TaskDO task, String processorTrackerAddress) {// 1. 持久化,更新数据库(如果更新数据库失败,可能导致重复执行,先不处理)TaskDO updateEntity = new TaskDO();updateEntity.setStatus(TaskStatus.DISPATCH_SUCCESS_WORKER_UNCHECK.getValue());// 写入处理该任务的 ProcessorTrackerupdateEntity.setAddress(processorTrackerAddress);boolean success = taskPersistenceService.updateTask(instanceId, task.getTaskId(), updateEntity);if (!success) {log.warn("[TaskTracker-{}] dispatch task(taskId={},taskName={}) failed due to update task status failed.", instanceId, task.getTaskId(), task.getTaskName());return;}// 2. 更新 ProcessorTrackerStatus 状态ptStatusHolder.getProcessorTrackerStatus(processorTrackerAddress).setDispatched(true);// 3. 初始化缓存taskId2BriefInfo.put(task.getTaskId(), new TaskBriefInfo(task.getTaskId(), TaskStatus.DISPATCH_SUCCESS_WORKER_UNCHECK, -1L));// 4. 任务派发TaskTrackerStartTaskReq startTaskReq = new TaskTrackerStartTaskReq(instanceInfo, task, workerRuntime.getWorkerAddress());TransportUtils.ttStartPtTask(startTaskReq, processorTrackerAddress, workerRuntime.getTransporter());log.debug("[TaskTracker-{}] dispatch task(taskId={},taskName={}) successfully.", instanceId, task.getTaskId(), task.getTaskName());
}/*** TransportUtils:* 第146行代码处:*/
public static void ttStartPtTask(TaskTrackerStartTaskReq req, String address, Transporter transporter) {final URL url = easyBuildUrl(ServerType.WORKER, WPT_PATH, WPT_HANDLER_START_TASK, address);transporter.tell(url, req);
}/*** ProcessorTrackerActor:* 第157行代码处:* 处理来自TaskTracker的task执行请求** @param req 请求*/
@Handler(path = RemoteConstant.WPT_HANDLER_START_TASK, processType = ProcessType.NO_BLOCKING)
public void onReceiveTaskTrackerStartTaskReq(TaskTrackerStartTaskReq req) {Long instanceId = req.getInstanceInfo().getInstanceId();// 创建 ProcessorTracker 一定能成功ProcessorTracker processorTracker = ProcessorTrackerManager.getProcessorTracker(instanceId,req.getTaskTrackerAddress(),() -> new ProcessorTracker(req, workerRuntime));TaskDO task = new TaskDO();task.setTaskId(req.getTaskId());task.setTaskName(req.getTaskName());task.setTaskContent(req.getTaskContent());task.setFailedCnt(req.getTaskCurrentRetryNums());task.setSubInstanceId(req.getSubInstanceId());processorTracker.submitTask(task);
}/*** ProcessorTracker:* 提交任务到线程池执行* 1.0版本:TaskTracker有任务就dispatch,导致 ProcessorTracker 本地可能堆积过多的任务,造成内存压力。为此 ProcessorTracker 在线程* 池队列堆积到一定程度时,会将数据持久化到DB,然后通过异步线程定时从数据库中取回任务,重新提交执行。* 联动:数据库的SPID设计、TaskStatus段落设计等,全部取消...* last commitId: 341953aceceafec0fbe7c3d9a3e26451656b945e* 2.0版本:ProcessorTracker定时向TaskTracker发送心跳消息,心跳消息中包含了当前线程池队列任务个数,TaskTracker根据ProcessorTracker* 的状态判断能否继续派发任务。因此,ProcessorTracker本地不会堆积过多任务,故删除 持久化机制 ╥﹏╥...!** @param newTask 需要提交到线程池执行的任务*/
public void submitTask(TaskDO newTask) {// 一旦 ProcessorTracker 出现异常,所有提交到此处的任务直接返回失败,防止形成死锁// 死锁分析:TT创建PT,PT创建失败,无法定期汇报心跳,TT长时间未收到PT心跳,认为PT宕机(确实宕机了),无法选择可用的PT再次派发任务,死锁形成,GG斯密达 T_Tif (lethal) {ProcessorReportTaskStatusReq report = new ProcessorReportTaskStatusReq().setInstanceId(instanceId).setSubInstanceId(newTask.getSubInstanceId()).setTaskId(newTask.getTaskId()).setStatus(TaskStatus.WORKER_PROCESS_FAILED.getValue()).setResult(lethalReason).setReportTime(System.currentTimeMillis());TransportUtils.ptReportTask(report, taskTrackerAddress, workerRuntime);return;}boolean success = false;// 1. 设置值并提交执行newTask.setInstanceId(instanceInfo.getInstanceId());newTask.setAddress(taskTrackerAddress);HeavyProcessorRunnable heavyProcessorRunnable = new HeavyProcessorRunnable(instanceInfo, taskTrackerAddress, newTask, processorBean, omsLogger, statusReportRetryQueue, workerRuntime);try {threadPool.submit(heavyProcessorRunnable);success = true;} catch (RejectedExecutionException ignore) {log.warn("[ProcessorTracker-{}] submit task(taskId={},taskName={}) to ThreadPool failed due to ThreadPool has too much task waiting to process, this task will dispatch to other ProcessorTracker.",instanceId, newTask.getTaskId(), newTask.getTaskName());} catch (Exception e) {log.error("[ProcessorTracker-{}] submit task(taskId={},taskName={}) to ThreadPool failed.", instanceId, newTask.getTaskId(), newTask.getTaskName(), e);}// 2. 回复接收成功if (success) {ProcessorReportTaskStatusReq reportReq = new ProcessorReportTaskStatusReq();reportReq.setInstanceId(instanceId);reportReq.setSubInstanceId(newTask.getSubInstanceId());reportReq.setTaskId(newTask.getTaskId());reportReq.setStatus(TaskStatus.WORKER_RECEIVED.getValue());reportReq.setReportTime(System.currentTimeMillis());TransportUtils.ptReportTask(reportReq, taskTrackerAddress, workerRuntime);log.debug("[ProcessorTracker-{}] submit task(taskId={}, taskName={}) success, current queue size: {}.",instanceId, newTask.getTaskId(), newTask.getTaskName(), threadPool.getQueue().size());}
}可以看到,在最后,Dispatcher会创建出一个HeavyProcessorRunnable的线程来执行,里面存放着需要执行的任务实例、执行地址、执行处理器等信息。接下来看下其实现:
/*** HeavyProcessorRunnable:*/
@Override
@SuppressWarnings("squid:S2142")
public void run() {// 切换线程上下文类加载器(否则用的是 Worker 类加载器,不存在容器类,在序列化/反序列化时会报 ClassNotFoundException)Thread.currentThread().setContextClassLoader(processorBean.getClassLoader());try {innerRun();} catch (InterruptedException ignore) {// ignore} catch (Throwable e) {reportStatus(TaskStatus.WORKER_PROCESS_FAILED, e.toString(), null, null);log.error("[ProcessorRunnable-{}] execute failed, please contact the author(@KFCFans) to fix the bug!", task.getInstanceId(), e);} finally {ThreadLocalStore.clear();}
}/*** 第10行代码处:*/
public void innerRun() throws InterruptedException {//获取执行处理器final BasicProcessor processor = processorBean.getProcessor();String taskId = task.getTaskId();Long instanceId = task.getInstanceId();log.debug("[ProcessorRunnable-{}] start to run task(taskId={}&taskName={})", instanceId, taskId, task.getTaskName());//缓存ThreadLocalStore.setTask(task);ThreadLocalStore.setRuntimeMeta(workerRuntime);// 0. 构造任务上下文WorkflowContext workflowContext = constructWorkflowContext();TaskContext taskContext = constructTaskContext();taskContext.setWorkflowContext(workflowContext);// 1. 上报执行信息reportStatus(TaskStatus.WORKER_PROCESSING, null, null, null);ProcessResult processResult;ExecuteType executeType = ExecuteType.valueOf(instanceInfo.getExecuteType());// 2. 根任务 & 广播执行 特殊处理if (TaskConstant.ROOT_TASK_NAME.equals(task.getTaskName()) && executeType == ExecuteType.BROADCAST) {// 广播执行:先选本机执行 preProcess,完成后 TaskTracker 再为所有 Worker 生成子 TaskhandleBroadcastRootTask(instanceId, taskContext);return;}// 3. 最终任务特殊处理(一定和 TaskTracker 处于相同的机器)if (TaskConstant.LAST_TASK_NAME.equals(task.getTaskName())) {handleLastTask(taskId, instanceId, taskContext, executeType);return;}// 4. 正式提交运行try {//这里的process方法也就是我们自己写的业务方法processResult = processor.process(taskContext);if (processResult == null) {processResult = new ProcessResult(false, "ProcessResult can't be null");}} catch (Throwable e) {log.warn("[ProcessorRunnable-{}] task(id={},name={}) process failed.", instanceId, taskContext.getTaskId(), taskContext.getTaskName(), e);processResult = new ProcessResult(false, e.toString());}//上报执行结果reportStatus(processResult.isSuccess() ? TaskStatus.WORKER_PROCESS_SUCCESS : TaskStatus.WORKER_PROCESS_FAILED, suit(processResult.getMsg()), null, workflowContext.getAppendedContextData());
}Dispatcher的作用就是分发任务,并执行任务。也就是会有一个单独的线程(HeavyProcessorRunnable),会定时从任务表中拿取任务,然后执行我们自己实现的process方法,并会在执行前和执行后上报执行信息。
2.3.2 CheckRunningInstance
/*** InstanceStatusCheckService:* 检查运行中的实例* RUNNING 超时:TaskTracker down,断开与 server 的心跳连接*/
public void checkRunningInstance() {Stopwatch stopwatch = Stopwatch.createStarted();// 查询 DB 获取该 Server 需要负责的 AppGroup//获取appIdList<Long> allAppIds = appInfoRepository.listAppIdByCurrentServer(transportService.defaultProtocol().getAddress());if (CollectionUtils.isEmpty(allAppIds)) {log.info("[InstanceStatusChecker] current server has no app's job to check");return;}try {// 检查 RUNNING 状态的任务(一定时间没收到 TaskTracker 的状态报告,视为失败)Lists.partition(allAppIds, MAX_BATCH_NUM_APP).forEach(this::handleRunningInstance);} catch (Exception e) {log.error("[InstanceStatusChecker] RunningInstance status check failed.", e);}log.info("[InstanceStatusChecker] RunningInstance status check using {}.", stopwatch.stop());
}/*** 第17行代码处:*/
private void handleRunningInstance(List<Long> partAppIds) {// 3. 检查 RUNNING 状态的任务(一定时间没收到 TaskTracker 的状态报告,视为失败)long threshold = System.currentTimeMillis() - RUNNING_TIMEOUT_MS;//查找修改时间距离现在超过1分钟的实例List<BriefInstanceInfo> failedInstances = instanceInfoRepository.selectBriefInfoByAppIdInAndStatusAndGmtModifiedBefore(partAppIds, InstanceStatus.RUNNING.getV(), new Date(threshold), PageRequest.of(0, MAX_BATCH_NUM_INSTANCE));while (!failedInstances.isEmpty()) {// collect job idSet<Long> jobIds = failedInstances.stream().map(BriefInstanceInfo::getJobId).collect(Collectors.toSet());// query job info and mapMap<Long, JobInfoDO> jobInfoMap = jobInfoRepository.findByIdIn(jobIds).stream().collect(Collectors.toMap(JobInfoDO::getId, e -> e));log.warn("[InstanceStatusCheckService] find some instances have not received status report for a long time : {}", failedInstances.stream().map(BriefInstanceInfo::getInstanceId).collect(Collectors.toList()));failedInstances.forEach(instance -> {Optional<JobInfoDO> jobInfoOpt = Optional.ofNullable(jobInfoMap.get(instance.getJobId()));if (!jobInfoOpt.isPresent()) {final Optional<InstanceInfoDO> opt = instanceInfoRepository.findById(instance.getId());opt.ifPresent(e -> updateFailedInstance(e, SystemInstanceResult.REPORT_TIMEOUT));return;}TimeExpressionType timeExpressionType = TimeExpressionType.of(jobInfoOpt.get().getTimeExpressionType());SwitchableStatus switchableStatus = SwitchableStatus.of(jobInfoOpt.get().getStatus());// 如果任务已关闭,则不进行重试,将任务置为失败即可;秒级任务也直接置为失败,由派发器重新调度if (switchableStatus != SwitchableStatus.ENABLE || TimeExpressionType.FREQUENT_TYPES.contains(timeExpressionType.getV())) {final Optional<InstanceInfoDO> opt = instanceInfoRepository.findById(instance.getId());opt.ifPresent(e -> updateFailedInstance(e, SystemInstanceResult.REPORT_TIMEOUT));return;}// CRON 和 API一样,失败次数 + 1,根据重试配置进行重试if (instance.getRunningTimes() < jobInfoOpt.get().getInstanceRetryNum()) {//更新实例表状态为等待派发dispatchService.redispatchAsync(instance.getInstanceId(), InstanceStatus.RUNNING.getV());} else {final Optional<InstanceInfoDO> opt = instanceInfoRepository.findById(instance.getId());opt.ifPresent(e -> updateFailedInstance(e, SystemInstanceResult.REPORT_TIMEOUT));}});threshold = System.currentTimeMillis() - RUNNING_TIMEOUT_MS;//重新查找修改时间距离现在超过1分钟的实例,并循环failedInstances = instanceInfoRepository.selectBriefInfoByAppIdInAndStatusAndGmtModifiedBefore(partAppIds, InstanceStatus.RUNNING.getV(), new Date(threshold), PageRequest.of(0, MAX_BATCH_NUM_INSTANCE));}}3 客户端
3.1 PowerJobSpringWorker
客户端的启动类同样没有什么逻辑,查看下初始化类PowerJobSpringWorker:
/*** PowerJobSpringWorker:*/
@Override
public void afterPropertiesSet() throws Exception {powerJobWorker = new PowerJobWorker(config);powerJobWorker.init();
}/*** PowerJobWorker:*/
public void init() throws Exception {if (!initialized.compareAndSet(false, true)) {log.warn("[PowerJobWorker] please do not repeat the initialization");return;}Stopwatch stopwatch = Stopwatch.createStarted();log.info("[PowerJobWorker] start to initialize PowerJobWorker...");PowerJobWorkerConfig config = workerRuntime.getWorkerConfig();CommonUtils.requireNonNull(config, "can't find PowerJobWorkerConfig, please set PowerJobWorkerConfig first");try {//打印bannerPowerBannerPrinter.print();// 校验 appNameif (!config.isEnableTestMode()) {assertAppName();} else {log.warn("[PowerJobWorker] using TestMode now, it's dangerous if this is production env.");}// 初始化元数据String workerAddress = NetUtils.getLocalHost() + ":" + config.getPort();workerRuntime.setWorkerAddress(workerAddress);// 初始化 线程池final ExecutorManager executorManager = new ExecutorManager(workerRuntime.getWorkerConfig());workerRuntime.setExecutorManager(executorManager);// 初始化 ProcessorLoader//动态加载类的工厂,可以不依赖于Spring的实现ProcessorLoader processorLoader = buildProcessorLoader(workerRuntime);workerRuntime.setProcessorLoader(processorLoader);// 初始化 actorTaskTrackerActor taskTrackerActor = new TaskTrackerActor(workerRuntime);ProcessorTrackerActor processorTrackerActor = new ProcessorTrackerActor(workerRuntime);WorkerActor workerActor = new WorkerActor(workerRuntime, taskTrackerActor);// 初始化通讯引擎EngineConfig engineConfig = new EngineConfig().setType(config.getProtocol().name()).setServerType(ServerType.WORKER).setBindAddress(new Address().setHost(NetUtils.getLocalHost()).setPort(config.getPort())).setActorList(Lists.newArrayList(taskTrackerActor, processorTrackerActor, workerActor));//之前服务端启动的时候也会执行PowerJobRemoteEngine.start方法EngineOutput engineOutput = remoteEngine.start(engineConfig);workerRuntime.setTransporter(engineOutput.getTransporter());// 连接 serverServerDiscoveryService serverDiscoveryService = new ServerDiscoveryService(workerRuntime.getAppId(), workerRuntime.getWorkerConfig());serverDiscoveryService.start(workerRuntime.getExecutorManager().getCoreExecutor());workerRuntime.setServerDiscoveryService(serverDiscoveryService);log.info("[PowerJobWorker] PowerJobRemoteEngine initialized successfully.");// 初始化日志系统OmsLogHandler omsLogHandler = new OmsLogHandler(workerAddress, workerRuntime.getTransporter(), serverDiscoveryService);workerRuntime.setOmsLogHandler(omsLogHandler);// 初始化存储TaskPersistenceService taskPersistenceService = new TaskPersistenceService(workerRuntime.getWorkerConfig().getStoreStrategy());taskPersistenceService.init();workerRuntime.setTaskPersistenceService(taskPersistenceService);log.info("[PowerJobWorker] local storage initialized successfully.");// 初始化定时任务workerRuntime.getExecutorManager().getCoreExecutor().scheduleAtFixedRate(new WorkerHealthReporter(workerRuntime), 0, config.getHealthReportInterval(), TimeUnit.SECONDS);workerRuntime.getExecutorManager().getCoreExecutor().scheduleWithFixedDelay(omsLogHandler.logSubmitter, 0, 5, TimeUnit.SECONDS);log.info("[PowerJobWorker] PowerJobWorker initialized successfully, using time: {}, congratulations!", stopwatch);} catch (Exception e) {log.error("[PowerJobWorker] initialize PowerJobWorker failed, using {}.", stopwatch, e);throw e;}
}/*** 第31行代码处:*/
@SuppressWarnings("rawtypes")
private void assertAppName() {PowerJobWorkerConfig config = workerRuntime.getWorkerConfig();String appName = config.getAppName();Objects.requireNonNull(appName, "appName can't be empty!");String url = "http://%s/server/assert?appName=%s";for (String server : config.getServerAddress()) {String realUrl = String.format(url, server, appName);try {//客户端启动的时候连接一下服务端,看是否能连通String resultDTOStr = CommonUtils.executeWithRetry0(() -> HttpUtils.get(realUrl));ResultDTO resultDTO = JsonUtils.parseObject(resultDTOStr, ResultDTO.class);if (resultDTO.isSuccess()) {Long appId = Long.valueOf(resultDTO.getData().toString());log.info("[PowerJobWorker] assert appName({}) succeed, the appId for this application is {}.", appName, appId);workerRuntime.setAppId(appId);return;} else {log.error("[PowerJobWorker] assert appName failed, this appName is invalid, please register the appName {} first.", appName);throw new PowerJobException(resultDTO.getMessage());}} catch (PowerJobException oe) {throw oe;} catch (Exception ignore) {log.warn("[PowerJobWorker] assert appName by url({}) failed, please check the server address.", realUrl);}}log.error("[PowerJobWorker] no available server in {}.", config.getServerAddress());throw new PowerJobException("no server available!");
}/*** ExecutorManager:* 第41行代码处:*/
public ExecutorManager(PowerJobWorkerConfig workerConfig) {//可用cpu数final int availableProcessors = Runtime.getRuntime().availableProcessors();// 初始化定时线程池ThreadFactory coreThreadFactory = new ThreadFactoryBuilder().setNameFormat("powerjob-worker-core-%d").build();coreExecutor = new ScheduledThreadPoolExecutor(3, coreThreadFactory);ThreadFactory lightTaskReportFactory = new ThreadFactoryBuilder().setNameFormat("powerjob-worker-light-task-status-check-%d").build();// 都是 io 密集型任务lightweightTaskStatusCheckExecutor = new ScheduledThreadPoolExecutor(availableProcessors * 10, lightTaskReportFactory);ThreadFactory lightTaskExecuteFactory = new ThreadFactoryBuilder().setNameFormat("powerjob-worker-light-task-execute-%d").build();// 大部分任务都是 io 密集型lightweightTaskExecutorService = new ThreadPoolExecutor(availableProcessors * 10, availableProcessors * 10, 120L, TimeUnit.SECONDS,new ArrayBlockingQueue<>((workerConfig.getMaxLightweightTaskNum() * 2), true), lightTaskExecuteFactory, new ThreadPoolExecutor.AbortPolicy());}/*** ServerDiscoveryService:* 第68行代码处:*/
public void start(ScheduledExecutorService timingPool) {this.currentServerAddress = discovery();if (StringUtils.isEmpty(this.currentServerAddress) && !config.isEnableTestMode()) {throw new PowerJobException("can't find any available server, this worker has been quarantined.");}// 这里必须保证成功timingPool.scheduleAtFixedRate(() -> {try {this.currentServerAddress = discovery();} catch (Exception e) {log.error("[PowerDiscovery] fail to discovery server!", e);}}, 10, 10, TimeUnit.SECONDS);
}/*** 第159行代码处和第166行代码处:*/
private String discovery() {if (ip2Address.isEmpty()) {config.getServerAddress().forEach(x -> ip2Address.put(x.split(":")[0], x));}String result = null;// 先对当前机器发起请求String currentServer = currentServerAddress;if (!StringUtils.isEmpty(currentServer)) {String ip = currentServer.split(":")[0];// 直接请求当前Server的HTTP服务,可以少一次网络开销,减轻Server负担String firstServerAddress = ip2Address.get(ip);if (firstServerAddress != null) {result = acquire(firstServerAddress);}}for (String httpServerAddress : config.getServerAddress()) {if (StringUtils.isEmpty(result)) {result = acquire(httpServerAddress);} else {break;}}if (StringUtils.isEmpty(result)) {log.warn("[PowerDiscovery] can't find any available server, this worker has been quarantined.");// 在 Server 高可用的前提下,连续失败多次,说明该节点与外界失联,Server已经将秒级任务转移到其他Worker,需要杀死本地的任务if (FAILED_COUNT++ > MAX_FAILED_COUNT) {log.warn("[PowerDiscovery] can't find any available server for 3 consecutive times, It's time to kill all frequent job in this worker.");List<Long> frequentInstanceIds = HeavyTaskTrackerManager.getAllFrequentTaskTrackerKeys();if (!CollectionUtils.isEmpty(frequentInstanceIds)) {frequentInstanceIds.forEach(instanceId -> {HeavyTaskTracker taskTracker = HeavyTaskTrackerManager.removeTaskTracker(instanceId);taskTracker.destroy();log.warn("[PowerDiscovery] kill frequent instance(instanceId={}) due to can't find any available server.", instanceId);});}FAILED_COUNT = 0;}return null;} else {// 重置失败次数FAILED_COUNT = 0;log.debug("[PowerDiscovery] current server is {}.", result);return result;}
}/*** 第192行代码处和第198行代码处*/
@SuppressWarnings("rawtypes")
private String acquire(String httpServerAddress) {String result = null;//构建url参数String url = buildServerDiscoveryUrl(httpServerAddress);try {//请求服务端ServerController.acquireServer方法result = CommonUtils.executeWithRetry0(() -> HttpUtils.get(url));} catch (Exception ignore) {}if (!StringUtils.isEmpty(result)) {try {ResultDTO resultDTO = JsonUtils.parseObject(result, ResultDTO.class);if (resultDTO.isSuccess()) {return resultDTO.getData().toString();}} catch (Exception ignore) {}}return null;
}/*** ServerController:* 第241行代码处:*/
@GetMapping("/acquire")
public ResultDTO<String> acquireServer(ServerDiscoveryRequest request) {return ResultDTO.success(serverElectionService.elect(request));
}/*** ServerElectionService:*/
public String elect(ServerDiscoveryRequest request) {if (!accurate()) {final String currentServer = request.getCurrentServer();// 如果是本机,就不需要查数据库那么复杂的操作了,直接返回成功Optional<ProtocolInfo> localProtocolInfoOpt = Optional.ofNullable(transportService.allProtocols().get(request.getProtocol()));//如果不是精确地请求,并且请求的参数中直接带有当前服务端的地址,则直接返回其地址即可if (localProtocolInfoOpt.isPresent() && localProtocolInfoOpt.get().getAddress().equals(currentServer)) {log.debug("[ServerElectionService] this server[{}] is worker's current server, skip check", currentServer);return currentServer;}}//上面的条件不满足,则走常规的选举流程return getServer0(request);
}/*** 第269行代码处:*/
private boolean accurate() {//accurateSelectServerPercentage默认为50,这里是在随机判断是否是精确的请求return ThreadLocalRandom.current().nextInt(100) < accurateSelectServerPercentage;
}/*** 第280行代码处:*/
private String getServer0(ServerDiscoveryRequest discoveryRequest) {final Long appId = discoveryRequest.getAppId();final String protocol = discoveryRequest.getProtocol();Set<String> downServerCache = Sets.newHashSet();for (int i = 0; i < RETRY_TIMES; i++) {// 无锁获取当前数据库中的ServerOptional<AppInfoDO> appInfoOpt = appInfoRepository.findById(appId);if (!appInfoOpt.isPresent()) {throw new PowerJobException(appId + " is not registered!");}String appName = appInfoOpt.get().getAppName();String originServer = appInfoOpt.get().getCurrentServer();String activeAddress = activeAddress(originServer, downServerCache, protocol);if (StringUtils.isNotEmpty(activeAddress)) {return activeAddress;}// 无可用Server,重新进行Server选举,需要加锁String lockName = String.format(SERVER_ELECT_LOCK, appId);//文件锁boolean lockStatus = lockService.tryLock(lockName, 30000);if (!lockStatus) {try {Thread.sleep(500);} catch (Exception ignore) {}continue;}try {// 可能上一台机器已经完成了Server选举,需要再次判断//双重检查加锁AppInfoDO appInfo = appInfoRepository.findById(appId).orElseThrow(() -> new RuntimeException("impossible, unless we just lost our database."));String address = activeAddress(appInfo.getCurrentServer(), downServerCache, protocol);if (StringUtils.isNotEmpty(address)) {return address;}// 篡位,如果本机存在协议,则作为Server调度该 worker//优先本机调度final ProtocolInfo targetProtocolInfo = transportService.allProtocols().get(protocol);if (targetProtocolInfo != null) {// 注意,写入 AppInfoDO#currentServer 的永远是 default 的地址,仅在返回的时候特殊处理为协议地址appInfo.setCurrentServer(transportService.defaultProtocol().getAddress());appInfo.setGmtModified(new Date());appInfoRepository.saveAndFlush(appInfo);log.info("[ServerElection] this server({}) become the new server for app(appId={}).", appInfo.getCurrentServer(), appId);return targetProtocolInfo.getAddress();}} catch (Exception e) {log.error("[ServerElection] write new server to db failed for app {}.", appName, e);} finally {lockService.unlock(lockName);}}throw new PowerJobException("server elect failed for app " + appId);
}/*** 第309行代码处:* 判断指定server是否存活** @param serverAddress 需要检测的server地址* @param downServerCache 缓存,防止多次发送PING(这个QPS其实还蛮爆表的...)* @param protocol 协议,用于返回指定的地址* @return null or address*/
private String activeAddress(String serverAddress, Set<String> downServerCache, String protocol) {if (downServerCache.contains(serverAddress)) {return null;}if (StringUtils.isEmpty(serverAddress)) {return null;}Ping ping = new Ping();ping.setCurrentTime(System.currentTimeMillis());//构建服务端url参数URL targetUrl = ServerURLFactory.ping2Friend(serverAddress);try {//这里会跳转到FriendActor.onReceivePing方法AskResponse response = transportService.ask(Protocol.HTTP.name(), targetUrl, ping, AskResponse.class).toCompletableFuture().get(PING_TIMEOUT_MS, TimeUnit.MILLISECONDS);if (response.isSuccess()) {// 检测通过的是远程 server 的暴露地址,需要返回 worker 需要的协议地址final JSONObject protocolInfo = JsonUtils.parseObject(response.getData(), JSONObject.class).getJSONObject(protocol);if (protocolInfo != null) {downServerCache.remove(serverAddress);final String protocolAddress = protocolInfo.toJavaObject(ProtocolInfo.class).getAddress();log.info("[ServerElection] server[{}] is active, it will be the master, final protocol address={}", serverAddress, protocolAddress);return protocolAddress;} else {log.warn("[ServerElection] server[{}] is active but don't have target protocol", serverAddress);}}} catch (TimeoutException te) {log.warn("[ServerElection] server[{}] was down due to ping timeout!", serverAddress);} catch (Exception e) {log.warn("[ServerElection] server[{}] was down with unknown case!", serverAddress, e);}downServerCache.add(serverAddress);return null;
}/*** FriendActor:* 第381行代码处:* 处理存活检测的请求*/
@Handler(path = S4S_HANDLER_PING, processType = ProcessType.NO_BLOCKING)
public AskResponse onReceivePing(Ping ping) {return AskResponse.succeed(transportService.allProtocols());
}/*** PowerTransportService:*/
@Override
public Map<String, ProtocolInfo> allProtocols() {//这里就是从protocolName2Info缓存中取数据return protocolName2Info;
}由上可知,在客户端启动的时候,会通过选举的方式来选出一台服务器作为自己的server(也可能不选举,直接选择当前的服务端),并且会定时发送心跳数据来进行保活。
在上面第85行代码处和第86行代码处,客户端启动的时候也会有两个定时任务,查看其实现:
3.1.1 WorkerHealthReporter
WorkerHealthReporter是用来给客户端健康度定时上报用的:
/*** WorkerHealthReporter:*/
@Override
public void run() {// 没有可用Server,无法上报String currentServer = workerRuntime.getServerDiscoveryService().getCurrentServerAddress();if (StringUtils.isEmpty(currentServer)) {log.warn("[WorkerHealthReporter] no available server,fail to report health info!");return;}SystemMetrics systemMetrics;if (workerRuntime.getWorkerConfig().getSystemMetricsCollector() == null) {systemMetrics = SystemInfoUtils.getSystemMetrics();} else {systemMetrics = workerRuntime.getWorkerConfig().getSystemMetricsCollector().collect();}WorkerHeartbeat heartbeat = new WorkerHeartbeat();heartbeat.setSystemMetrics(systemMetrics);heartbeat.setWorkerAddress(workerRuntime.getWorkerAddress());heartbeat.setAppName(workerRuntime.getWorkerConfig().getAppName());heartbeat.setAppId(workerRuntime.getAppId());heartbeat.setHeartbeatTime(System.currentTimeMillis());heartbeat.setVersion(PowerJobWorkerVersion.getVersion());heartbeat.setProtocol(workerRuntime.getWorkerConfig().getProtocol().name());heartbeat.setClient("KingPenguin");heartbeat.setTag(workerRuntime.getWorkerConfig().getTag());// 上报 Tracker 数量heartbeat.setLightTaskTrackerNum(LightTaskTrackerManager.currentTaskTrackerSize());heartbeat.setHeavyTaskTrackerNum(HeavyTaskTrackerManager.currentTaskTrackerSize());// 是否超载if (workerRuntime.getWorkerConfig().getMaxLightweightTaskNum() <= LightTaskTrackerManager.currentTaskTrackerSize() || workerRuntime.getWorkerConfig().getMaxHeavyweightTaskNum() <= HeavyTaskTrackerManager.currentTaskTrackerSize()) {heartbeat.setOverload(true);}// 获取当前加载的容器列表heartbeat.setContainerInfos(OmsContainerFactory.getDeployedContainerInfos());// 发送请求if (StringUtils.isEmpty(currentServer)) {return;}// loglog.info("[WorkerHealthReporter] report health status,appId:{},appName:{},isOverload:{},maxLightweightTaskNum:{},currentLightweightTaskNum:{},maxHeavyweightTaskNum:{},currentHeavyweightTaskNum:{}",heartbeat.getAppId(),heartbeat.getAppName(),heartbeat.isOverload(),workerRuntime.getWorkerConfig().getMaxLightweightTaskNum(),heartbeat.getLightTaskTrackerNum(),workerRuntime.getWorkerConfig().getMaxHeavyweightTaskNum(),heartbeat.getHeavyTaskTrackerNum());TransportUtils.reportWorkerHeartbeat(heartbeat, currentServer, workerRuntime.getTransporter());
}/*** SystemInfoUtils:* 第17行代码处:*/
public static SystemMetrics getSystemMetrics() {SystemMetrics metrics = new SystemMetrics();//赋值cpu指标fillCPUInfo(metrics);//赋值内存指标fillMemoryInfo(metrics);//赋值磁盘指标fillDiskInfo(metrics);// 在Worker完成分数计算,减小Server压力metrics.calculateScore();return metrics;
}/*** TransportUtils:* 第58行代码处:*/
public static void reportWorkerHeartbeat(WorkerHeartbeat req, String address, Transporter transporter) {//绑定url调用信息final URL url = easyBuildUrl(ServerType.SERVER, S4W_PATH, S4W_HANDLER_WORKER_HEARTBEAT, address);transporter.tell(url, req);
}其中SystemInfoUtils.getSystemMetrics方法是在获取系统的一些指标数据(调用的都是Java的底层Api,这里就不再详细查看了),并且计算健康度的得分(之前在第2.3.1小节中已经查看过该方法的实现了)。基于此,我们就知道了控制台首页的worker指标数据是怎么来的了:
在上面第88行代码处向服务端发送了心跳数据,接下来就来看下服务端是如何处理的:
/*** AbWorkerRequestHandler:*/
@Override
@Handler(path = S4W_HANDLER_WORKER_HEARTBEAT, processType = ProcessType.NO_BLOCKING)
public void processWorkerHeartbeat(WorkerHeartbeat heartbeat) {long startMs = System.currentTimeMillis();WorkerHeartbeatEvent event = new WorkerHeartbeatEvent().setAppName(heartbeat.getAppName()).setAppId(heartbeat.getAppId()).setVersion(heartbeat.getVersion()).setProtocol(heartbeat.getProtocol()).setTag(heartbeat.getTag()).setWorkerAddress(heartbeat.getWorkerAddress()).setDelayMs(startMs - heartbeat.getHeartbeatTime()).setScore(heartbeat.getSystemMetrics().getScore());processWorkerHeartbeat0(heartbeat, event);//默认实现是写入日志进行监控monitorService.monitor(event);
}/*** WorkerRequestHandlerImpl:* 第17行代码处:*/
@Override
protected void processWorkerHeartbeat0(WorkerHeartbeat heartbeat, WorkerHeartbeatEvent event) {WorkerClusterManagerService.updateStatus(heartbeat);
}/*** WorkerClusterManagerService:* 更新状态** @param heartbeat Worker的心跳包*/
public static void updateStatus(WorkerHeartbeat heartbeat) {Long appId = heartbeat.getAppId();String appName = heartbeat.getAppName();ClusterStatusHolder clusterStatusHolder = APP_ID_2_CLUSTER_STATUS.computeIfAbsent(appId, ignore -> new ClusterStatusHolder(appName));clusterStatusHolder.updateStatus(heartbeat);
}/*** ClusterStatusHolder:* 更新 worker 机器的状态** @param heartbeat 心跳请求*/
public void updateStatus(WorkerHeartbeat heartbeat) {String workerAddress = heartbeat.getWorkerAddress();long heartbeatTime = heartbeat.getHeartbeatTime();WorkerInfo workerInfo = address2WorkerInfo.computeIfAbsent(workerAddress, ignore -> {WorkerInfo wf = new WorkerInfo();wf.refresh(heartbeat);return wf;});long oldTime = workerInfo.getLastActiveTime();//过期心跳数据,不处理if (heartbeatTime < oldTime) {log.warn("[ClusterStatusHolder-{}] receive the expired heartbeat from {}, serverTime: {}, heartTime: {}", appName, heartbeat.getWorkerAddress(), System.currentTimeMillis(), heartbeat.getHeartbeatTime());return;}workerInfo.refresh(heartbeat);List<DeployedContainerInfo> containerInfos = heartbeat.getContainerInfos();if (!CollectionUtils.isEmpty(containerInfos)) {containerInfos.forEach(containerInfo -> {Map<String, DeployedContainerInfo> infos = containerId2Infos.computeIfAbsent(containerInfo.getContainerId(), ignore -> Maps.newConcurrentMap());infos.put(workerAddress, containerInfo);});}
}/*** WorkerInfo:* 第57行代码处和第67行代码处:* 刷新服务端记录的客户端的数据*/
public void refresh(WorkerHeartbeat workerHeartbeat) {address = workerHeartbeat.getWorkerAddress();lastActiveTime = workerHeartbeat.getHeartbeatTime();protocol = workerHeartbeat.getProtocol();client = workerHeartbeat.getClient();tag = workerHeartbeat.getTag();systemMetrics = workerHeartbeat.getSystemMetrics();containerInfos = workerHeartbeat.getContainerInfos();lightTaskTrackerNum = workerHeartbeat.getLightTaskTrackerNum();heavyTaskTrackerNum = workerHeartbeat.getHeavyTaskTrackerNum();if (workerHeartbeat.isOverload()) {overloading = true;lastOverloadTime = workerHeartbeat.getHeartbeatTime();log.warn("[WorkerInfo] worker {} is overload!", getAddress());} else {overloading = false;}
}3.1.2 LogSubmitter
/*** LogSubmitter:*/
@Override
public void run() {boolean lockResult = reportLock.tryLock();if (!lockResult) {return;}try {final String currentServerAddress = serverDiscoveryService.getCurrentServerAddress();// 当前无可用 Serverif (StringUtils.isEmpty(currentServerAddress)) {if (!logQueue.isEmpty()) {logQueue.clear();log.warn("[OmsLogHandler] because there is no available server to report logs which leads to queue accumulation, oms discarded all logs.");}return;}List<InstanceLogContent> logs = Lists.newLinkedList();while (!logQueue.isEmpty()) {try {//从日志队列头部取数据InstanceLogContent logContent = logQueue.poll(100, TimeUnit.MILLISECONDS);logs.add(logContent);//批处理if (logs.size() >= BATCH_SIZE) {WorkerLogReportReq req = new WorkerLogReportReq(workerAddress, Lists.newLinkedList(logs));// 不可靠请求,WEB日志不追求极致TransportUtils.reportLogs(req, currentServerAddress, transporter);logs.clear();}} catch (Exception ignore) {break;}}if (!logs.isEmpty()) {WorkerLogReportReq req = new WorkerLogReportReq(workerAddress, logs);TransportUtils.reportLogs(req, currentServerAddress, transporter);}} finally {reportLock.unlock();}
}/*** TransportUtils:* 第36行代码处和第47行代码处:*/
public static void reportLogs(WorkerLogReportReq req, String address, Transporter transporter) {final URL url = easyBuildUrl(ServerType.SERVER, S4W_PATH, S4W_HANDLER_REPORT_LOG, address);transporter.tell(url, req);
}上面第61行代码处会将请求发送到服务端的AbWorkerRequestHandler.processWorkerLogReport方法中:
/*** AbWorkerRequestHandler:*/
@Override
@Handler(path = S4W_HANDLER_REPORT_LOG, processType = ProcessType.NO_BLOCKING)
public void processWorkerLogReport(WorkerLogReportReq req) {WorkerLogReportEvent event = new WorkerLogReportEvent().setWorkerAddress(req.getWorkerAddress()).setLogNum(req.getInstanceLogContents().size());try {processWorkerLogReport0(req, event);event.setStatus(WorkerLogReportEvent.Status.SUCCESS);} catch (RejectedExecutionException re) {event.setStatus(WorkerLogReportEvent.Status.REJECTED);} catch (Throwable t) {event.setStatus(WorkerLogReportEvent.Status.EXCEPTION);log.warn("[WorkerRequestHandler] process worker report failed!", t);} finally {//日志监控monitorService.monitor(event);}
}/*** WorkerRequestHandlerImpl:* 第12行代码处:*/
@Override
protected void processWorkerLogReport0(WorkerLogReportReq req, WorkerLogReportEvent event) {// 这个效率应该不会拉垮吧...也就是一些判断 + Map#get 吧...instanceLogService.submitLogs(req.getWorkerAddress(), req.getInstanceLogContents());
}/*** InstanceLogService:* 提交日志记录,持久化到本地数据库中** @param workerAddress 上报机器地址* @param logs 任务实例运行时日志*/
@Async(value = PJThreadPool.LOCAL_DB_POOL)
public void submitLogs(String workerAddress, List<InstanceLogContent> logs) {List<LocalInstanceLogDO> logList = logs.stream().map(x -> {instanceId2LastReportTime.put(x.getInstanceId(), System.currentTimeMillis());LocalInstanceLogDO y = new LocalInstanceLogDO();BeanUtils.copyProperties(x, y);y.setWorkerAddress(workerAddress);return y;}).collect(Collectors.toList());try {//插入到local_instance_log表中CommonUtils.executeWithRetry0(() -> localInstanceLogRepository.saveAll(logList));} catch (Exception e) {log.warn("[InstanceLogService] persistent instance logs failed, these logs will be dropped: {}.", logs, e);}
}原创不易,未得准许,请勿转载,翻版必究
这篇关于较真儿学源码系列-PowerJob启动流程源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



