本文主要是介绍矿大新闻精准检索-Python,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目简介
在中国矿业大学计算机学院官网新闻中,检索是否含有某个词,并将结果输出到Excel
目标网站:http://cs.cumt.edu.cn/index/xwdt.htm
包含的新闻类型:新闻动态、通知公告、学术交流、学生风采、师生风采和教学科研
项目成果
生成一个Excel文件,四列分别为:新闻类型、新闻标题、新闻链接、含有哪些检索词
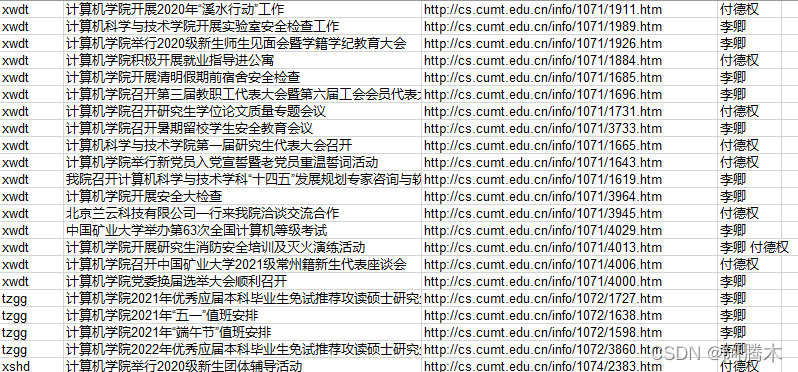
源代码
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
import re
import xlwt# 此处填入所有敏感词
words = ["李卿", "付德权"]
# 新闻类型
# 比如通知公告的列表页为:http://cs.cumt.edu.cn/index/tzgg.htm
# 那么就将tzgg加入typeList列表
typeList = ["xwdt", "tzgg", "xsjl", "xshd", "ssfc", "jxky1"]line = 0
workbook = xlwt.Workbook(encoding="utf-8")
worksheet = workbook.add_sheet("main")def writeLine(type, title, link, words):global line, workbook, worksheetworksheet.write(line, 0, type)worksheet.write(line, 1, title)worksheet.write(line, 2, link)worksheet.write(line, 3, words)line = line + 1def analyse(words, type):print("————————————" + "开始分析:" + type + "——————————————")url = "http://cs.cumt.edu.cn/index/" + type + "/"index = 1while True:url2 = url + str(index) + ".htm"print("\n查找:" + url2)try:response = urllib.request.urlopen(url2)except urllib.error.URLError as e:print("————————————" + "分析完毕:" + type + "——————————————")breakbs = BeautifulSoup(response, "html.parser")liTag = bs.select("a[target='_blank']")for li in liTag:title = li.contents[0]detailUrl = "http://cs.cumt.edu.cn" + li['href'][5:]print(detailUrl)try:detailRes = urllib.request.urlopen(detailUrl, timeout=1)except IOError:continuedetailRes = detailRes.read().decode('utf-8')wordsResult = []flag = Falsefor word in words:pat = re.compile(word)match = pat.search(detailRes)if match is not None:flag = TruewordsResult.append(word + " ")if flag:print(detailUrl + " 含:" + str(words) + " 已写入xls")writeLine(type, title, detailUrl, wordsResult)index = index + 1if __name__ == '__main__':for type in typeList:analyse(words, type)workbook.save("result.xls")
这篇关于矿大新闻精准检索-Python的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




