本文主要是介绍【redis】认识redis和分布式系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 认识 redis
- redis 的主要功能
- 实现数据库
- 实现缓存
- 实现消息中间件
- 分布式系统
- 单机架构
- 为什么数据多了主机就难以应对 ?
- 分布式系统
认识 redis
redis 的主要功能
用来在内存中存储数据
定义变量不就是在内存中存储数据吗?为什么还需要
redis来向内存中存储数据?这不是绕了一个圈嘛?
- redis 是在分布式系统中才能发挥威力
- 如果只是单机程序,直接通过变量存储数据的方式,是比使用
redis更优的选择
由于我们现在很多的系统都是分布式的系统,在分布式系统中,若想让多个服务器都共享同一份数据,又想这个数据存在于内存中,此时使用 redis 就是一个可选的选择了
对于存储数据来说,直接存在变量中,往往是更快速、更方便的选择,但是若放在分布式系统中,直接定义变量就不行了
- 因为你定义的变量是在你当前服务器进程中的一块空间
- 进程具有隔离性,每个进程之间都是被隔离开的,进程 A 无法读取进程 B 中的数据
- 如果是在分布式系统下,肯定会涉及到多个进程,甚至是在不同的主机上的多个进程,此时你想直接访问其他内存中的变量,这件事就变得困难起来了
redis就是针对上述的功能点进行了封装,既然没法突破进程的隔离性直接进行访问,那就使用“进程间通信“,网络 就是其最主流方案
网络既可以让同一个主机间的进程进行通信,而且还可以让不同主机之间的进程进行通信,因此,redis 就相当于是基于网络,能够把自己内存中的的变量给别的进程、甚至别的主机的进程进行使用
实现数据库
redis 还被一些人当做数据库来使用
常见的
MySQL最大的问题在于:访问的速度比较慢。
在很多互联网产品中,对性能要求是很高的,“慢”有时候就是一个很大的问题
redis 被当做数据库来使用的优点就在于:快,快很多
- 核心在于它是用内存存储数据的,而
MySQL的数据是在硬盘上的 - 计算机访问内存的速度比访问硬盘的速度快几千上万倍
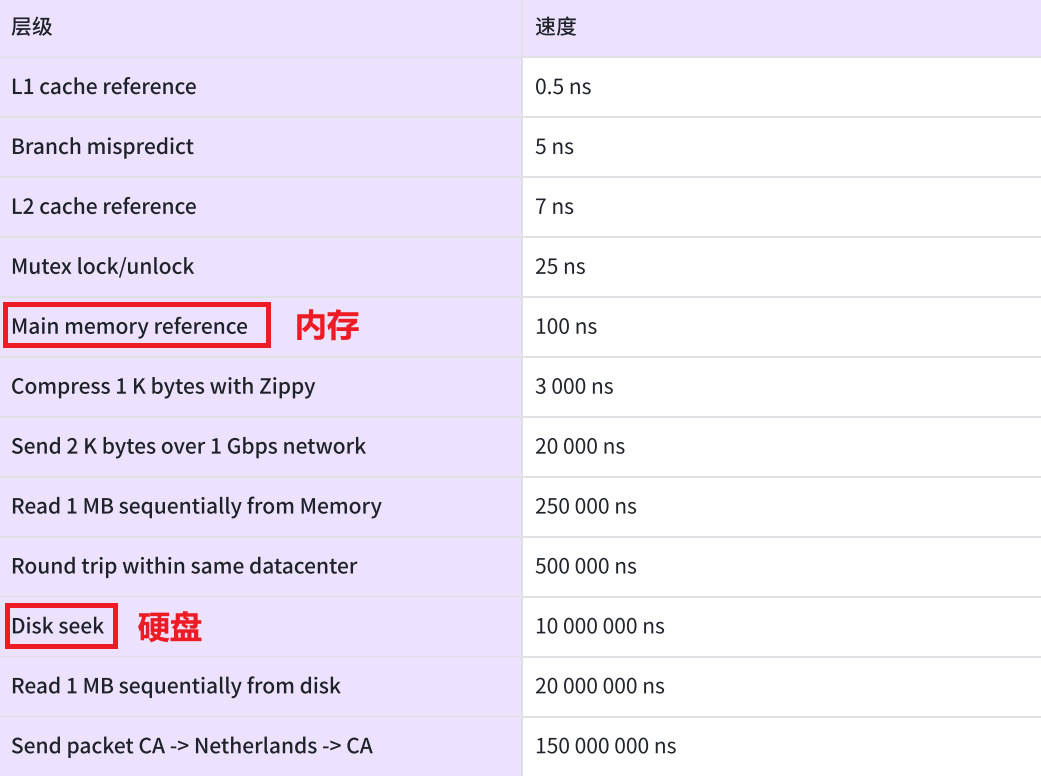
redis 和 MySQL 相比,最大的劣势是:存储空间是有限的
- 虽然有不少的互联网产品,对性能要求是很高的,就需要访问速度很快
- 但更多的互联网产品对于性能的要求没那么高,同时又希望用更低的成本存更多的数据,显然
MySQL是更好的选择,同时MySQL相比于redis来说,提供了更丰富的功能
实现缓存
那有没有存储空间又大,访问速度又快的方案呢?
- 典型的方案就是把
redis和MySQL结合起来 - 把热点数据(经常访问的数据)就用 redis 来存储,把全量数据就用
MySQL来存储 - “二八原则”,20% 的热点数据能满足 80% 的访问需求
这就是缓存的机制,不过这样系统的复杂程度就会大大提高。而且,如果数据发生修改,还会涉及到 redis 和 MySQL 之间的数据同步问题
实现消息中间件
redis 的初心,就是作为一个“消息中间件”(消息队列),实现分布式系统下的生产者消费者模型
但当前很少会直接使用 redis 作为消息中间件,因为业界中有更多更专业的消息中间件可以使用
分布式系统
千万不要把所谓的“分布式”想的太复杂,太高大上…
单机架构
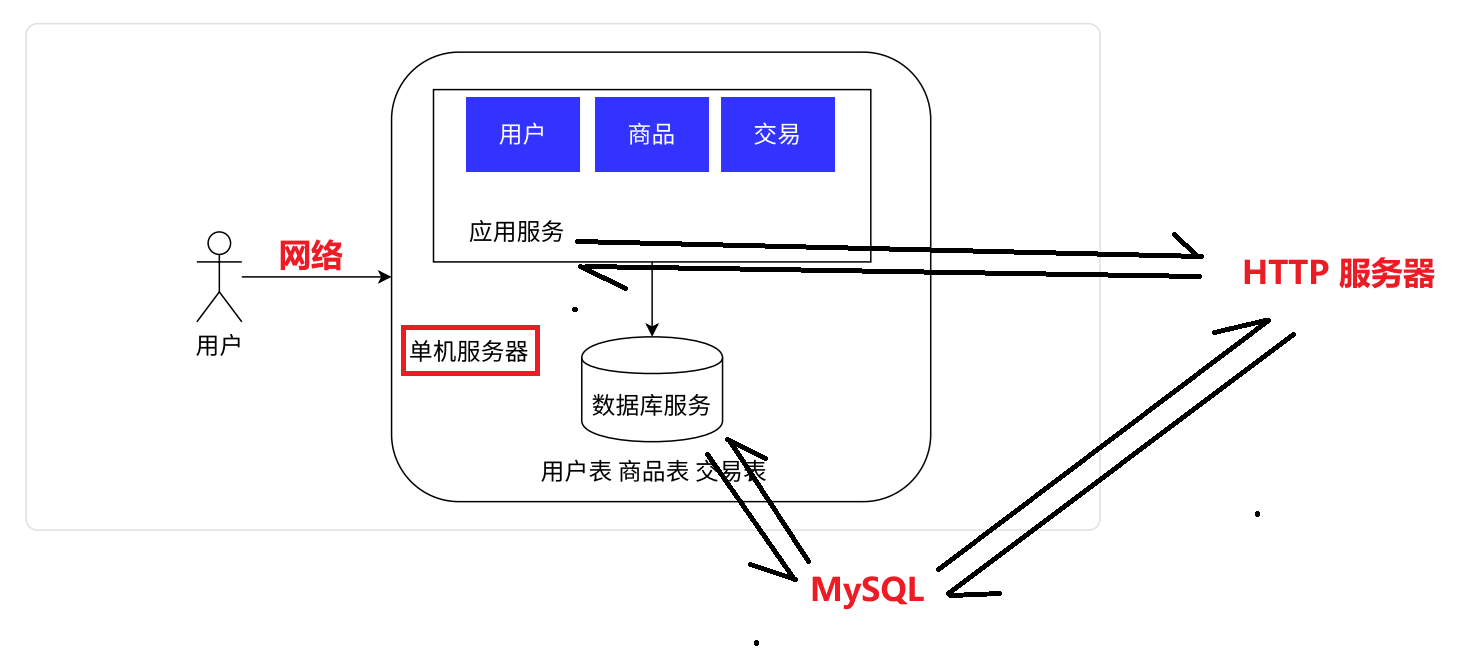
此处假定是一个“电商网站”,用户通过网络访问这个服务器,其分为两个部分:
-
应用服务:我们写的服务器程序
- 就是说用户打开这个网站,页面上要能显示商品信息,点进去能看到详情,能下单… 这些预计的功能就是通过这个“应用服务器/HTTP服务器这样的程序”来支撑的
C++里面的cpp-hyyplibJava里面的Spring- 这俩都是用来写
HTTP服务器的
-
数据库服务:
- 用来存储这个网站中大量的数据
- 可以使用
MySQLMySQL是一个“客户端-服务器“结构的程序,本体是MySQL服务器(存储和组织数据的部分)- 上面的
HTTP应用服务服务器作为客户端,去读写数据库服务
- 当用户现在查看商品列表,那么应用服务器(HTTP 服务器) 就会发送请求给
MySQL服务器,然后 MySQL 查找数据之后将数据返回给应用程序,最后应用程序通过 HTTP 协议,最终将信息返回给用户
绝大部分的公司的产品都是这种单机架构。因为现在的计算机硬件发展速度是非常快的,这就意味着哪怕我们只有一台主机,这一台主机的性能也是非常高的,可以支持非常高的并发,非常大的数据存储
如果业务进一步增长,用户量和数据量都水涨船高,当一台主机难以应付的时候,就需要引入更多的主机,引入更多的硬件资源,就需要使用分布式系统了
为什么数据多了主机就难以应对 ?
一台主机的硬件资源是有上限的,包括但不限于一下几种:
- CPU
- 内存
- 硬盘
- 网络
- …
服务器每次收到一个请求,都是需要消耗上述的一些资源的~~
如果同一时刻处理的请求多了,此时就可能会导致某个硬件资源不够用了,无论是那个方面不够用了,都可能会导致服务器处理请求的时间变长,甚至于处理出错
如果我们真的遇到了这样的服务器不够用的场景,我们可以:
- 开源
- 简单粗暴,直接增加更多的硬件资源(什么不够补什么)
- 不过一个主机上面能增加的硬件资源也是有限的,取决于主板的扩展能力
- 节流(软件上优化)
- 针对程序进行优化,优化代码(各凭本事)
- 通过性能测试,找到是哪个环节出现了瓶颈,再对症下药
- 操作起来很难!对程序员的水平要求比较高
分布式系统
当一台主机扩展到极限了,但是还不够,就只能引入多台主机了
但不是说买来的新的机器直接就可以解决问题,也需要软件上做出对应的调整和适配。当引入多台主机了,我们的系统就可以称为“分布式系统”了
引入分布式系统是万不得已的,系统的复杂程度会大大大提高(指数增长),这样出现 bug 的概率就越高、加班的概率就越大、丢失年终奖的概率也随之提高
这篇关于【redis】认识redis和分布式系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





