本文主要是介绍JVM体系结构与内存模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在分析JVM体系结构之前,先看下Dalvik-JVM和Java-DVM的区别:
1.DVM基于寄存器JVM基于内存
Dalvik 基于寄存器,而 JVM 基于栈。基于寄存器的虚拟机对于更大的程序来说,在它们编译的时候,花费的时间更短。
2.字节码区别
VM字节码由.class文件组成,每个文件一个class。JVM在运行的时候为每一个类装载字节码。相反的,Dalvik程序只包含一个.dex文件,这个文件包含了程序中所有的类。Java编译器创建了JVM字节码之后,Dalvik的dx编译器删除.class文件,重新把它们编译成Dalvik字节码,然后把它们写进一个.dex文件中。
3.虚拟机实例区别
Dalvik 经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik 应用作为一个独立的Linux 进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
4.其他
有一个特殊的虚拟机进程Zygote,他是虚拟机实例的孵化器。它在系统启动的时候就会产生,它会完成虚拟机的初始化、库的加载、预制类库和初始化的操作。如果系统需要一个新的虚拟机实例,它会迅速复制自身,以最快的速度提供给系统。对于一些只读的系统库,所有虚拟机实例都和Zygote共享一块内存区域。
参考:
Dalvik VM (DVM) 与Java VM (JVM)的区别 - 云淡风轻 - 博客频道 - CSDN.NET
http://blog.csdn.net/x356982611/article/details/21983267
下面开始分析JVM体系结构:
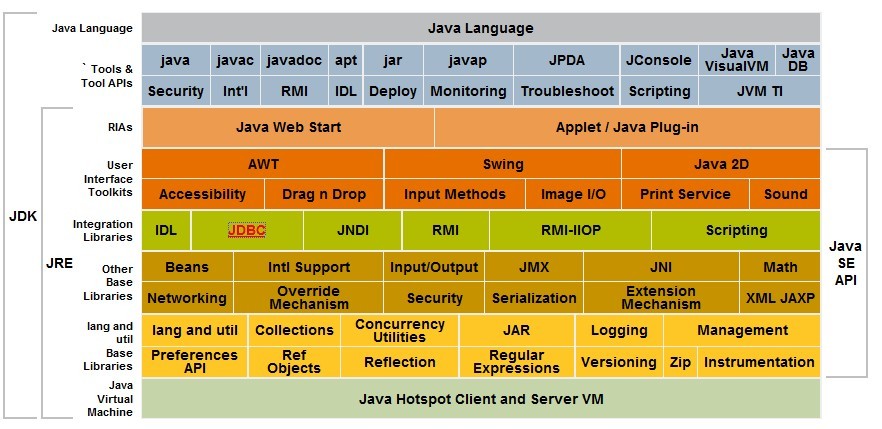
一:Java技术体系模块图:
二:JVM内存区域模型:
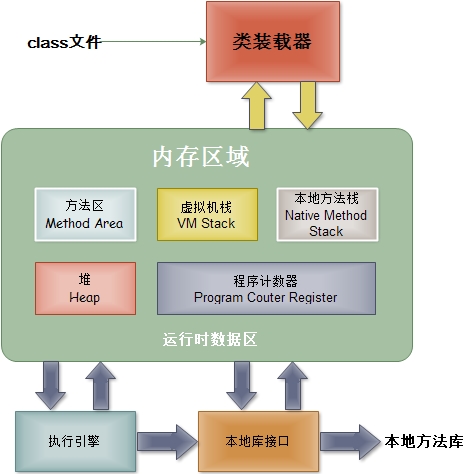
1.方法区
也称"永久代” 、“非堆”, 它用于存储虚拟机加载的类信息、常量、静态变量、是各个线程共享的内存区域。默认最小值为16MB,最大值为64MB。
运行时常量池:是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译器生成的各种符号引用,这部分内容将在类加载后放到方法区的运行时常量池中。
2.虚拟机栈
描述的是java 方法执行的内存模型:每个方法被执行的时候 都会创建一个“栈帧”用于存储局部变量表(包括参数)、操作栈、方法出口等信息。每个方法被调用到执行完的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。声明周期与线程相同,是线程私有的。
局部变量表存放了编译器可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(引用指针,并非对象本身),其中64位长度的long和double类型的数据会占用2个局部变量的空间,其余数据类型只占1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量是完全确定的,在运行期间栈帧不会改变局部变量表的大小空间。
3.本地方法栈
与虚拟机栈基本类似,区别在于虚拟机栈为虚拟机执行的java方法服务,而本地方法栈则是为Native方法服务。
4.堆
也叫做java 堆、GC堆是java虚拟机所管理的内存中最大的一块内存区域,也是被各个线程共享的内存区域,在JVM启动时创建。该内存区域存放了对象实例及数组(所有new的对象)。由于现在收集器都是采用分代收集算法,堆被划分为新生代和老年代。新生代主要存储新创建的对象和尚未进入老年代的对象。老年代存储经过多次新生代GC(Minor GC)任然存活的对象。
新生代:
程序新创建的对象都是从新生代分配内存,新生代由Eden Space和两块相同大小的Survivor Space(通常又称S0和S1或From和To)构成。
老年代:
用于存放经过多次新生代GC任然存活的对象,例如缓存对象,新建的对象也有可能直接进入老年代,主要有两种情况:①.大对象,超过多大时就不在新生代分配,而是直接在老年代分配。②.大的数组对象。
5.程序计数器
是最小的一块内存区域,它的作用是当前线程所执行的字节码的行号指示器,在虚拟机的模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、异常处理、线程恢复等基础功能都需要依赖计数器完成。
三:直接内存
直接内存并不是虚拟机内存的一部分,也不是Java虚拟机规范中定义的内存区域。jdk1.4中新加入的NIO,引入了通道与缓冲区的IO方式,它可以调用Native方法直接分配堆外内存,这个堆外内存就是本机内存,不会影响到堆内存的大小。
四:对象访问
对象访问会涉及到Java栈、Java堆、方法区这三个内存区域。
如下面这句代码:
- Object objectRef = new Object();

Object objectRef = new Object();假设这句代码出现在方法体中,"Object objectRef” 这部分将会反映到Java栈的本地变量中,作为一个reference类型数据出现。而“new Object()”这部分将会反映到Java堆中,形成一块存储Object类型所有实例数据值的结构化内存,根据具体类型以及虚拟机实现的对象内存布局的不同,这块内存的长度是不固定。另外,在java堆中还必须包括能查找到此对象类型数据(如对象类型、父类、实现的接口、方法等)的地址信息,这些数据类型存储在方法区中。
reference类型在java虚拟机规范里面只规定了一个指向对象的引用地址,并没有定义这个引用应该通过那种方式去定位,访问到java堆中的对象位置,因此不同的虚拟机实现的访问方式可能不同,主流的方式有两种:使用句柄和直接指针。(句柄是指向指针的指针)
本文原文链接:http://blog.csdn.net/java2000_wl/article/details/8009362 转载请注明出处!
这篇关于JVM体系结构与内存模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





