本文主要是介绍《Spark快速大数据分析》——读书笔记(4),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第4章 键值对操作
键值对RDD通常用来进行聚合计算。我们一般要先通过一些初试ETL(抽取、转化、装载)操作来将数据转化为键值对形式。
本章也会讨论用来让用户控制键值对RDD在各节点上分布情况的高级特性:分区。
4.1 动机
pair RDD(包含键值对类型的RDD)提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
4.2 创建Pair RDD
当需要把一个普通的RDD转为pair RDD时,可以调用map()函数来实现,传递的函数需要返回键值对。
例4-1:在Python中使用第一个单词作为键创建出一个pair RDD
pairs=lines.map(lambda x: (x.split(" ")[0], x))java和Scala版本的略。
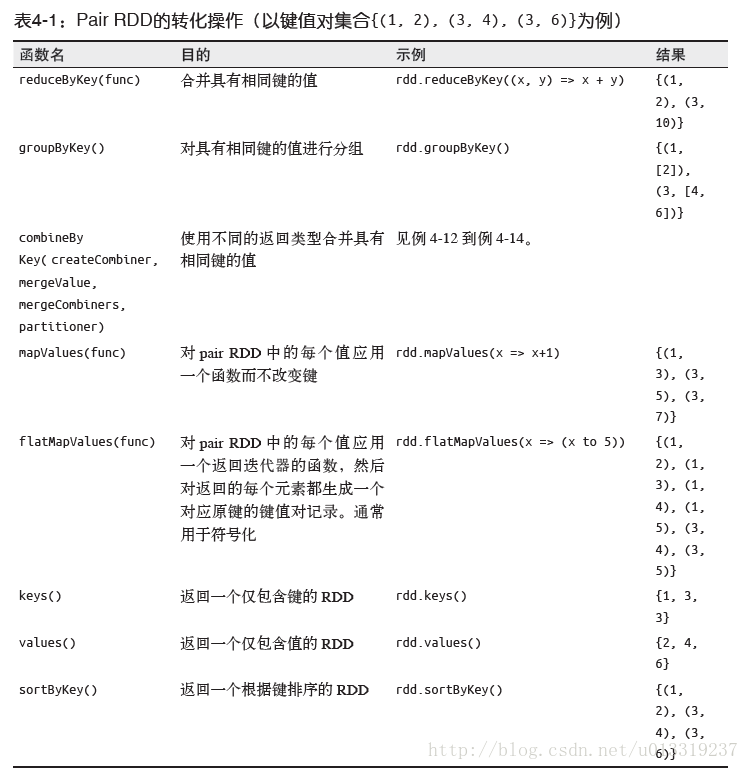
4.3 Pair RDD的转化操作
Pair RDD可以使用所有标准RDD上的可用的转化操作。3.4节中介绍的所有关于传递函数的规则也都是用于pair RDD。


例4-4:用Python对第二个元素进行筛选
result=pairs.filter(lambda keyValue:len(keyValue[1])<20)mapValues(func)函数功能类似于map{case (x, y) : (x, func(y))}可以只访问值部分。
4.3.1 聚合操作
基础RDD上的fold()、combine()、reduce()等是行动操作,Spark中对键进行聚合的聚合操作返回RDD是转化操作。
reduceByKey()和reduce()类似;它们都接收一个函数,并使用该函数对值进行合并。它返回一个由各键和对应键归约出来的结果值组成的新的RDD。
foldByKey()与fold()类似;它们都使用一个与RDD和合并函数中的数据类型相同的零值作为初始值。
例4-7:在Python中使用reduceByKey()和mapValues()计算每个键对应的平均值
rdd.mapValues(lambda x:(x, 1)).reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))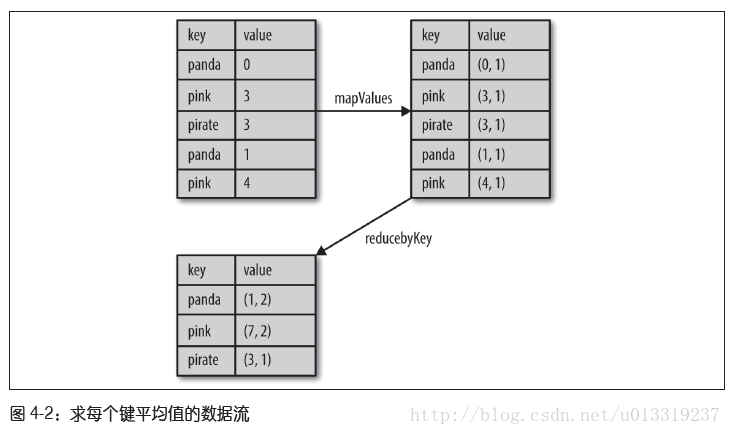
分布式单词计数问题,可以使用flatMap()来生成以单词为键,以数字1为值的pair RDD,然后利用reduceByKey()对所有单词进行计数。
例4-9:用Python 实现单词计数
rdd=sc.textFile("s3://...")
words=rdd.flatMap(lambda x:x.split(" "))
result=words.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)combineByKey()是最为常用的基于键进行聚合的函数。和aggregate()一样,combineByKey()可以让用户返回与输入数据的类型不同的返回值。
combineByKey()有多个参数分别对应聚合操作的各个阶段。
例4-12:在Python中使用combineByKey()求每个键对应的平均值
sumCount=nums.combineByKey((lambda x:(x,1)),(lambda x,y:(x[0]+y,x[1]+1)),(lambda x,y:(x[0]+y[0],x[1]+y[1])))
sumCount.map(lambda key, xy:(key, xy[0]/xy[1])).collectAsMap()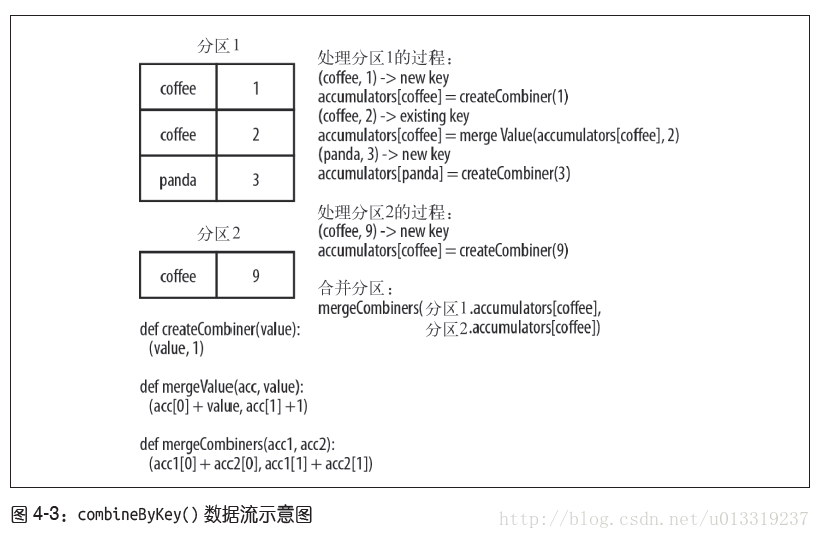
有很多函数可以进行基于键的数据合并,在Spark中使用这些专用的聚合函数,始终要比手动将数据分组再规约快很多。
并行度调优
我们讨论了所有的转化操作的分发方式(这个是什么?),但是还没探讨Spark是怎么确定如何分割工作的。每个RDD都有固定数目的分区,分区树决定了在RDD上执行操作时的并行度。
Spark有默认值,但是也可以调整分区数,进而对并行度调优获取更好的性能表现。
例4-15:在Python中自定义reduceByKey()的并行度
data=[("a",3),("b",4),("a",1)]
sc.parallelize(data).reduceByKey(lambda x,y:x+y)
sc.parallelize(data).reduceByKey(lambda x,y:x+y,10)除分组操作和聚合操作之外,Spark提供了repartition()函数,它吧数据通过网络进行混洗,并创建出新的分区集合。但代价较大。
coalesce()是优化版的repartition()函数。
4.3.2 数据分组
groupByKey()使用RDD中的键对数据进行分组。对于类型K的键和类型V的值的RDD,得到的结果是[K, Iterable[V]]。
groupBy()可以用在未成对的数据上,也可以根据键相同以外的条件进行分组。它可以接受一个函数,对源RDD中的每个元素使用该函数,将返回结果作为键在进行分组。
cogroup()函数对多个共享一个键的RDD进行分组。对两个键的类型均为K而值类型分别为V和W的RDD进行cogroup()时,得到的结果RDD类型为[(K,(Iterable[V],Iterable[W]))]。cogroup()不仅可以用于实现连接操作,还可以用来求键的交集,除此之外,cogroup()还能同时应用于三个及以上的RDD。
4.3.3 连接
连接方式:右外连接、左外连接、交叉连接以及内连接。
普通的join操作符表示内连接。
还有leftOuterJoin(other)和rightOuterJoin(other)
4.3.4 数据排序
sortByKey()接受ascending参数,表示是否让结果按升序排序。还可以支持自定义的比较函数。
例4-19:在Python中以字符串顺序对证书进行自定义排序
rdd.sortByKey(ascending=True, numPartitions=None,keyfunc=lambda x:str(x))4.4 Pair RDD的行动操作
和转化操作一样,所有基础RDD支持的传统行动操作也都在pair RDD上可用,也有一些额外的行动操作。

4.5 数据分区(进阶)
Spark程序可以通过控制RDD分区方式来减少通信开销。
Spark中所有的键值对RDD都可以进行分区,系统会根据一个针对键的函数对元素进行分组。尽管Spark没有给出显示控制每个键具体落在哪一个工作节点上的方法,但Spark可以确保同一组的键出现在同一个节点上。
join()操作会对两个表所有键的哈希值计算出来,如果需要对每个表重复地进行join()操作,partitionBy()转化操作可以将表转为哈希分区,避免重复的对表进行哈希值计算和跨节点数据混洗。注意,parititionBy()是一个转化操作,需要对结果进行持久化。
事实上,许多其他Spark操作会自动为结果RDD设定已知的分区方式信息,而且除join()外还有很多操作也会利用到已有的分区信息。比如,sortByKey()和groupByKey()会分别生成范围分区的RDD和哈希分区的RDD。另一方面,诸如map()这样的操作会导致新的RDD失去父RDD的分区信息,因为这样的操作理论上可能会修改每条记录的键。
4.5.1 获取RDD的分区方式
在Scala和Java中,可以使用RDD的partitioner属性(Java中使用partitioner()方法)来获取RDD的分区方式。它会返回一个scala.Option对象,这是Scala中用来存放可能存在的对象的容器类,可以对其调用isDefined()来检查其中是否有值,调用get()来获取其中的值。
Python中没有提供查询分区方式的方法,但是Spark内部仍会里所有已有的分区信息。
4.5.2 从分区中获益的操作
Spark的许多操作都引入了将数据根据键跨节点进行混洗的过程。这些操作都会从数据分区中获益。如:cogroup()、groupwith()、join()、leftOuterJoin()、rightOuterJoin、groupByKey()、reduceByKey()、combineByKey()以及lookup()。
对于像reduceByKey()这样只作用于单个RDD的操作,运行在未分区的RDD上的时候会导致每个键的所有对应值都在每台机器上进行本地运算,只需要吧本地最终归约出的结果传回主节点,网络开销本来就不大。而对于cogroup()和join() 这样的二元操作,预先进行数据分区会导致其中至少一个RDD不发生数据混洗。如果两个RDD使用同样的分区方式,并且他们还缓存在同样的机器上,或者其中一个RDD还没有被计算出来(这里不懂!),那么跨节点的数据混洗就不会发生了。
4.5.3 影响分区方式的操作
Spark内部知道各操作会如何影响分区方式,并将会对数据进行分区的操作的结果RDD自动设置为对应的分区器。
所有会为生成的结果RDD设好分区方式的操作:cogroup()、groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、reduceByKey()、combineByKey()、partitionBy()、sort()、mapValues()(如果父RDD有分区方式的话)、flatMapValues()(如果父RDD有分区方式的话),以及filter()(如果父RDD有分区方式的话)。
最后,对于二元操作,输出数据的分区方式取决于父RDD 的分区方式。默认情况下,结果会采用哈希分区,分区的数量和操作的并行度一样。不过,如果其中的一个父RDD 已经设置过分区方式,那么结果就会采用那种分区方式;如果两个父RDD 都设置过分区方式,结果RDD 会采用第一个父RDD 的分区方式。
4.5.4 示例:PageRank
4.5.5 自定义分区方式
虽然Spark提供的HashPartitioner与RangePartitioner已经能满足大多数用例,Spark还允许你提供一个自定义的Partitioner对象来控制RDD的分区方式。
要实现自定义的分区器,需要继承org.apache.spark.Partitioner类并实现下面三个方法:
- numPartitions:Int:返回创建出来的分区数。
- getPartition(key:Any):Int:返回给定键的分区编号(0到numPartitions-1)
- equals():Java判断相等性的标准方法。Spark需要该方法检查分区器对象是否和其他分区器示例相同,这样Spark才可以判断两个RDD的分区方式是否相同。
Java和Scala中自定义Partitioner的方法与Scala中的做法非常相似:只需要扩展spark.Partitioner类并且实现必要的方法即可。
Python中不需要扩展Partitioner类,而是吧一个特定的哈希函数作为一个额外的参数传给RDD.partitionBy()函数。
例4-27:Python自定义分区方式
import urlparse
def hash_domain(url)return hash(urlparse.urlparse(url).netloc)
rdd.partitionBy(20,hash_domain)注意,这里你所传过去的哈希函数会被与其他RDD 的分区函数区分开来。如果你想要对多个RDD 使用相同的分区方式,就应该使用同一个函数对象,比如一个全局函数,而不是为每个RDD 创建一个新的函数对象。
4.6 总结
本章学习了如何使用Spark提供的专门的函数来操作键值对数据。
这篇关于《Spark快速大数据分析》——读书笔记(4)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





