本文主要是介绍Docker数据卷和Dockerfile,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、什么是Docker数据卷
前言:

在下载的镜像中,我们不能够去改变它内部的一些配置,因为docker的镜像文件是已经配置好的,无法改变,我们只能改变镜像启动后的容器里面的内容,但是又因为,容器本来就是一个临时的,当容器停止了,那么我们内部的一些存储的数据也将会丢失,那么docker官方为了能够解决这个临时性的问题而产生了数据卷(volume)这个组件。
Docker 数据卷(Volumes)是 Docker 中用于持久化和共享数据的机制。数据卷使得 Docker 容器可以在容器生命周期之外持久化数据,并且方便在不同容器之间共享数据。具体来说,Docker 数据卷的特点和功能包括:
-
持久化数据:
- 数据卷可以将数据从容器内部持久化到宿主机上的文件系统中,这样即使容器被删除,数据仍然存在。
-
容器之间共享数据:
- 数据卷可以被多个容器挂载和使用,允许容器之间共享数据。比如,可以用来共享配置文件、数据库数据等。

- 数据卷可以被多个容器挂载和使用,允许容器之间共享数据。比如,可以用来共享配置文件、数据库数据等。
-
独立于容器生命周期:
- 数据卷的生命周期独立于容器。即便容器被删除或重建,数据卷中的数据仍然保留,用户可以在新创建的容器中继续使用这些数据。
-
易于备份和恢复:
- 数据卷可以被备份和恢复,通常通过宿主机的文件系统进行。这使得数据的备份和恢复变得相对简单。
-
数据管理:
- 可以通过 Docker 命令进行数据卷的管理,包括创建、删除、列出等操作。例如,
docker volume create用于创建数据卷,docker volume rm用于删除数据卷。
- 可以通过 Docker 命令进行数据卷的管理,包括创建、删除、列出等操作。例如,
-
性能和安全性:
- 数据卷存储在宿主机的文件系统上,通常性能较好。与容器内的临时文件相比,数据卷也提供了更好的数据持久性和安全性。
2、数据卷的指令
1)创建数据卷:
docker volume create 名称使用这种方式创建的数据卷可也被docker volume管理,如查看,删除等。新建的数据卷被保存在/var/lib/docker/volumes目录下。
2)查看数据卷:
docker volume ls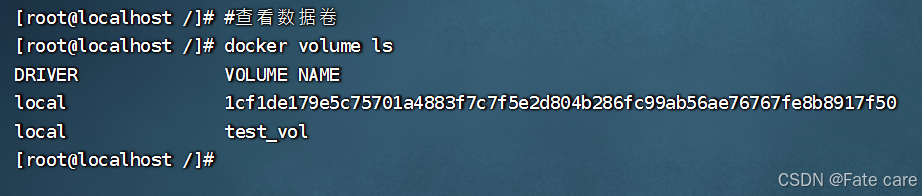
3)查看数据卷的详细信息:
docker volume inspect 数据卷的名称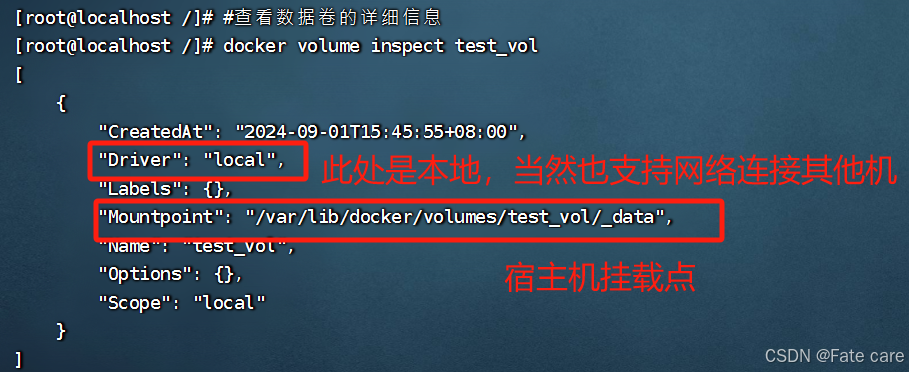
4)删除数据卷:
docker volume rm 数据卷名称
3、数据卷的使用
3.1、数据卷挂载
1)创建数据卷
docker volume create 数据卷名称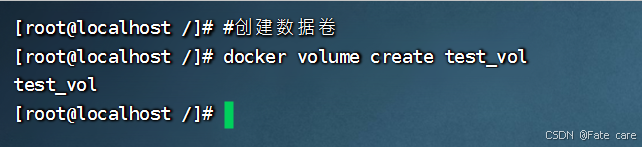
2)将数据卷挂载到容器
docker run -it --name 定义容器名称 --mount source=数据卷名称,target=容器挂载点(也就是在容器中所存在的文件夹) ubuntu:18.04(需要启动的镜像)
当然也存在简写方式
docker run -it --name 容器名称 -v 数据卷名称:容器对应的文件夹 镜像名称验证是否挂载成功

切换到宿主机中,查看数据卷中文件是否存在
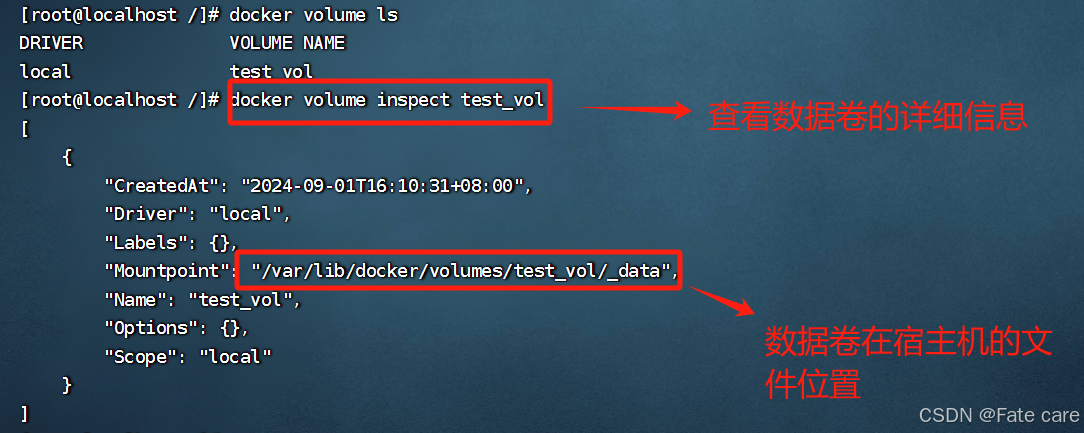
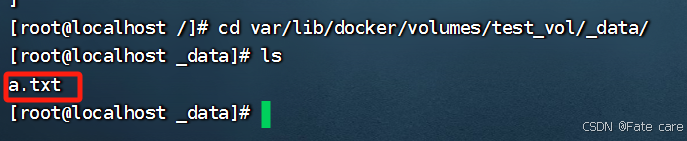
3.2、直接挂载宿主机文件
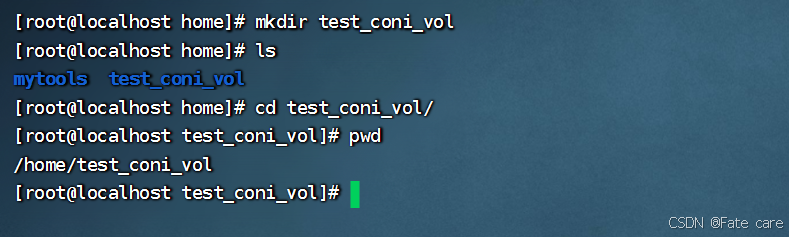
1)在宿主机随别创建一个文件
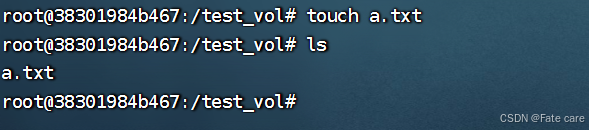
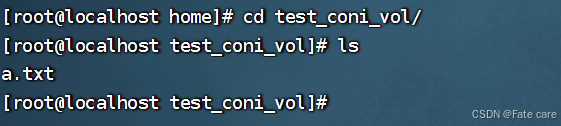
2)运行一个容器将它和宿主机创建的文件相互绑定

如果是创建只读的数据卷的话,在指令的test_vol后面加上:ro
如果是创建只读的数据卷的话,在指令的test_vol后面加上:ro
如果是创建只读的数据卷的话,在指令的test_vol后面加上:ro
3.3、数据卷容器
1)创建一个数据卷容器
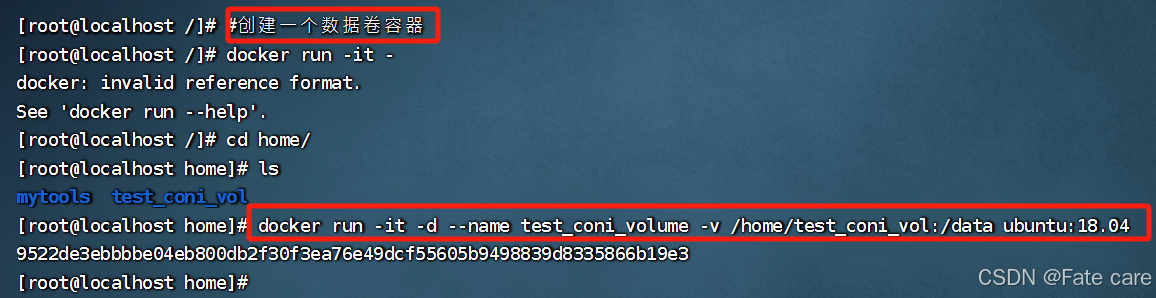
2)创建一个容器挂载数据卷容器

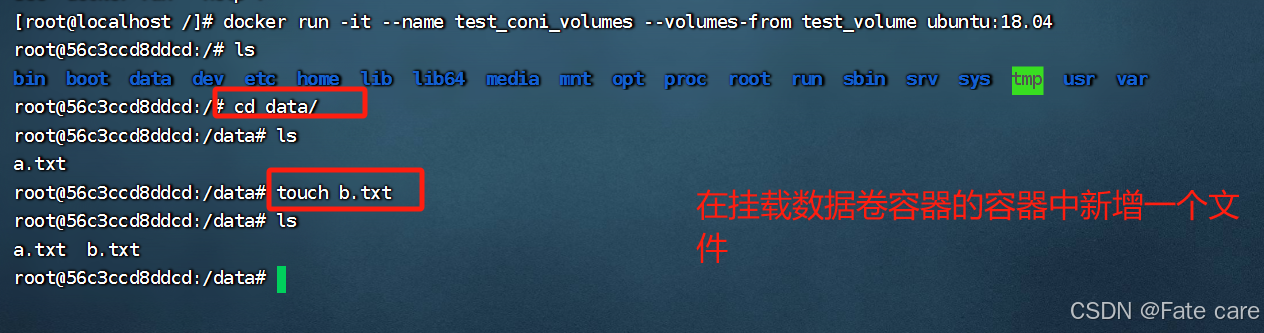

3.4、数据卷容器的备份与恢复
3.4.1)数据卷容器备份
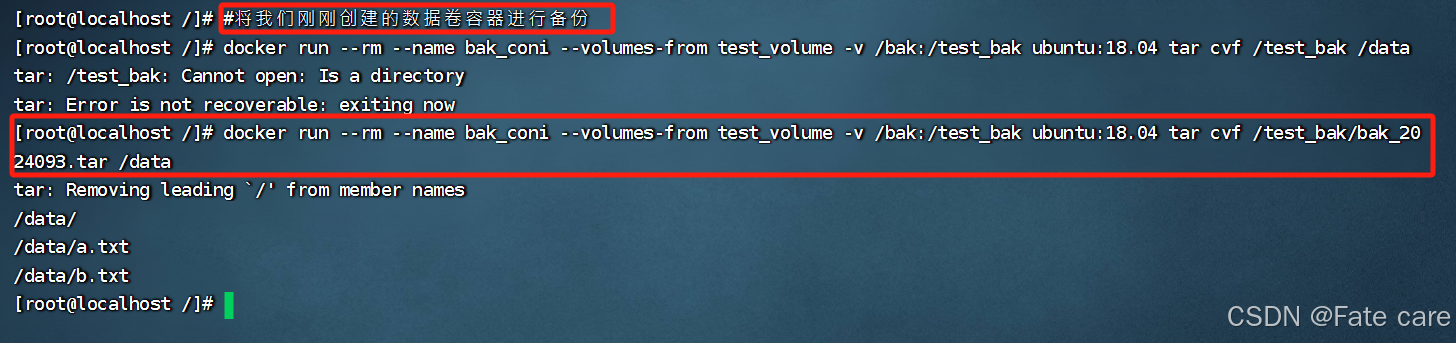
然后在宿主机中查看是否存在/bak文件夹

这样说明备份成功!
3.4.2)数据卷容器恢复

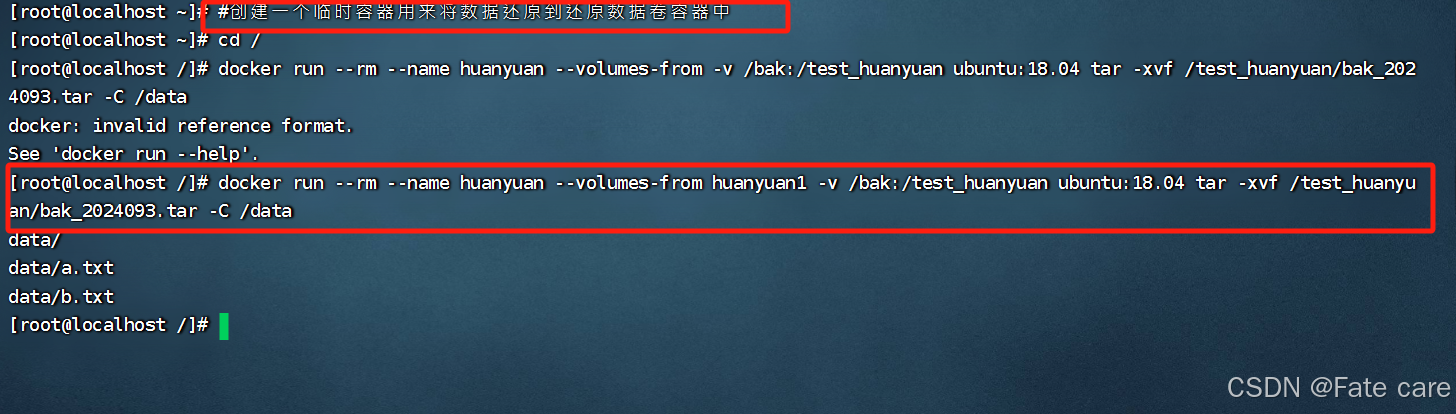
进入haunyuan1容器查看数据是否恢复

4、什么是Dockerfile
Dockerfile 是一种用于定义 Docker 镜像的文本文件。它包含了一系列的指令,用于自动化构建 Docker 镜像的过程。这些指令可以包括:
- 基础镜像的指定(如
FROM ubuntu:20.04) - 安装软件包(如
RUN apt-get update && apt-get install -y nginx) - 复制文件(如
COPY . /app) - 设置环境变量(如
ENV PATH /app/bin:$PATH) - 运行命令(如
CMD ["nginx", "-g", "daemon off;"])
通过 Dockerfile,可以将应用程序及其所有依赖项打包成一个可移植的镜像,这样就可以在不同的环境中一致地运行这些应用程序。
5、Dockerfile基本指令
在 Dockerfile 中,常用的基本指令包括:
-
FROM
指定基础镜像。例如:FROM ubuntu:20.04 -
RUN
在镜像构建过程中执行命令,通常用于安装软件包。RUN apt-get update && apt-get install -y nginx -
COPY
将文件或目录从宿主机复制到镜像中。COPY ./src /app/src -
ADD
类似于 COPY,但它还支持从 URL 下载文件以及解压 tar 文件。ADD https://example.com/file.tar.gz /app/ -
WORKDIR
设置工作目录,后续的命令将在该目录下执行。WORKDIR /app -
CMD
指定容器启动时执行的默认命令和参数。CMD ["nginx", "-g", "daemon off;"] -
ENTRYPOINT
设置容器启动时执行的命令,并且 CMD 中的参数会传递给 ENTRYPOINT。ENTRYPOINT ["python3", "app.py"] -
ENV
设置环境变量。ENV APP_ENV=production -
EXPOSE
指定容器在运行时监听的端口,但这不会实际发布端口。EXPOSE 80 -
VOLUME
创建一个挂载点,以便容器可以将数据持久化到宿主机。VOLUME ["/data"] -
USER
指定运行容器时使用的用户。USER appuser -
ARG
定义在构建时可以传递的变量。ARG VERSION=1.0
这些指令可以组合使用来创建一个自定义的 Docker 镜像。
6、Dockerfile示例
前提:
想要构建基本镜像,必须要有Dockerfile文件,而且文件没有拓展名!!!
想要构建基本镜像,必须要有Dockerfile文件,而且文件没有拓展名!!!
想要构建基本镜像,必须要有Dockerfile文件,而且文件没有拓展名!!!
1)准备好所有的文件创建jdk镜像

2)Dockerfile文件内容如下
#1、指定基本镜像
FROM ubuntu:18.04
#2、指明该镜像的作者和其他电子邮件
MAINTAINER ZY "ZY@QQ.COM"
#3、指定镜像的工作目录
WORKDIR /test/zy
#4、将jdk复制到镜像中
ADD jdk-8u151-linux-x64.tar.gz /test/zy
#5、配置环境变量
ENV JAVA_HOME=/test/zy/jdk1.8.0_151
ENV PATH=${JAVA_HOME}/bin:$PATH
#6、容器启动时运行的命令
#CMD ["java","-version"]
3)执行Dockerfile文件进行构建镜像
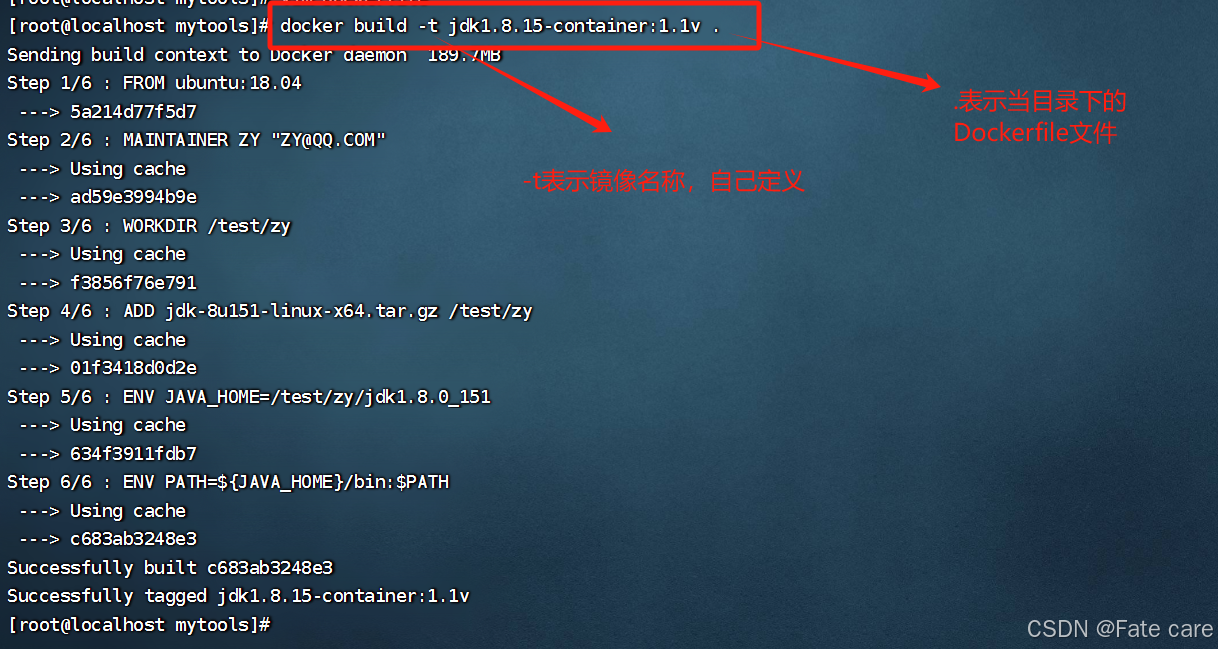
4)查看镜像

完结了!!!!!!!!!!!!!!!!!!!!!!!!!!
这篇关于Docker数据卷和Dockerfile的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





