本文主要是介绍leetcode --- Longest Common Prefix,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最长公共前缀(Longest Common Prefix)
题目:Write a function to find the longest common prefix string amongst an array of strings.
给出一个字符串数组,找出数组元素的最长公共前缀。看到这个题的第一反应是用字典树(Tire tree)来解决,但是马上又把这个想法推翻了,原因很简单,这些数组元素,也就是数组中的字符串的字符没有范围规定,是大写字母?小写字母?*这类特殊字符,当然也可以这样做,但是建立字典树的空间就会很大很大,需要包括所有的打印字符。比较朴素的方法就是对每个字符串就行匹配,得出公共前缀。
例如: abc abce abcfgh .....
首先要确定一点,最长公共前缀不可能超过数组中长度最短的字符串长度len,然后在这个长度内对比所有字符串,当有任一个字符和其他字符不相等时,返回。Code如下:
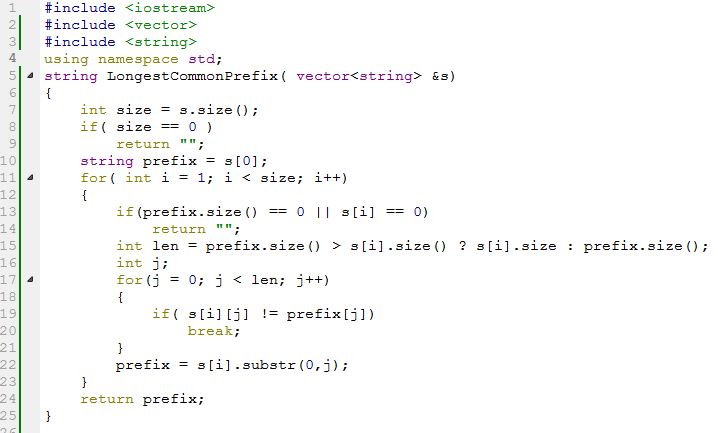
·字典树
前面提到了字典树,它是一种字符串处理中一种比较常见的数据结构,它的基本机构如下:

·建立字典树
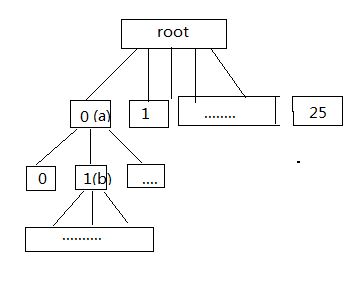
特别地,字典树的root节点是不包含任何信息的,给定一个字符串s,例如"abcd",首先计算每个字符在next[]的index,这里,a_index=a-'a',那么a在next[]的索引位置为0,如果这个位置为NULL,则为该位置分配空间并赋值,如果该位置不为NULL,那么修改该位置的信息,这里我们假设struct Tire中的count为简单的计数,创建字典树的代码如下:

建立字典树的结构大致如下图:
·查找
字典树的查找,按照字典树的结构从上到下查找,比如给定一个字符串数组,查询有多少个字符串一'a'开头,代码如下:

·释放字典树空间

以上便是字典树的操作,针对不同情况,增加或删除节点的某些信息,在查找时,针对需要查找的内容从上到下查找,便能得出结果,例如在Longest Common Prefix的问题中,如果数组中的字符串组成限制在小写或大写字符中,那么从上到下查找,当一个节点的next数组有2个及以上的索引位置不为空时,查找便结束,前面查找到的长度len就是公共字符串长度,随便去字符串数组中的一个字符串s,那么s.substr[0,len]就是公共前缀。
字典树的建立、查找、删除都是和字符串长度密切相关,故,这些操作的时间复杂度应该是O(s.size())=O(n)。
这篇关于leetcode --- Longest Common Prefix的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







