本文主要是介绍AIGC时代算法工程师的面试秘籍(第二十一式2024.8.19-9.1) |【三年面试五年模拟】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试经验,力求让读者在获得心仪offer的同时,增强技术基本面。也欢迎大家提出宝贵的优化建议,一起交流学习💪
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
WeThinkIn最新福利放送:大家只需关注WeThinkIn公众号,后台回复“简历资源”,即可获取包含Rocky独家简历模版在内的60套精选的简历模板资源,希望能给大家在AIGC时代带来帮助。
Rocky最新发布Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章:https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期阅读《三年面试五年模拟》文章的时候了!本周期共更新了60多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的60+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第二十一式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年8月19号-2024年9月1号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
《三年面试五年模拟》系列将陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
目录先行
AI绘画基础:
-
FLUX.1系列模型有哪些创新点?
-
什么是图像的位数?
AI视频基础:
-
Sora模型的整体架构是什么样的?
-
CogVideoX模型的整体架构是什么样的?
深度学习基础:
-
什么是GELU激活函数?
-
T5LayerNorm和LayerNorm的区别是什么?
机器学习基础:
-
机器学习中的Embeddings特征的本质是什么?
-
AI行业主要有哪些核心的数据模态?
Python编程基础:
-
介绍一下如何使用Python中的fastapi构建AI服务
-
介绍一下Python中常用的标准库以及功能
模型部署基础:
-
大模型推理框架介绍
-
Int8和FP8有哪些区别?
计算机基础:
-
在计算机中有哪些常用的读写操作,每个读写操作的性能是什么样的?
-
在AI行业中两个服务器之间的通信有哪些注意事项?
开放性问题:
-
我们如何降低下一个Transformer式技术价值的错判率?
-
未来会有新的技术替代Transformer吗?哪种技术的概率最大?
AI绘画基础
【一】FLUX.1系列模型有哪些创新点?
FLUX.1系列模型是基于Stable Diffuson 3进行了升级优化,是目前性能最强的开源AI绘画大模型,其主要的创新点如下所示:
- FLUX.1系列模型将VAE的通道数扩展至64,比SD3的VAE通道数足足增加了4倍(16)。
- 目前公布的两个FLUX.1系列模型都是经过指引蒸馏的产物,这样我们就无需使用Classifier-Free Guidance技术,只需要把指引强度当成一个约束条件输入进模型,就能在推理过程中得到带指定指引强度的输出。
- FLUX.1系列模型继承了Stable Diffusion 3 的噪声调度机制,对于分辨率越高的图像,把越多的去噪迭代放在了高噪声的时刻上。但和Stable Diffusion 3不同的是,FLUX.1不仅在训练时有这种设计,采样时也使用了这种技巧。
- FLUX.1系列模型中在DiT架构中设计了双流DiT结构和单流DiT结构,同时加入了二维旋转式位置编码 (RoPE) 策略。
- FLUX.1系列模型在单流的DiT中引入了并行注意力层的设计,注意力层和MLP并联执行,执行速度有所提升。
【二】什么是图像的位数?
图像的位数(bit depth) 是一个非常重要的概念,它指的是图像中每个像素所使用的二进制位数(bit)来表示颜色或灰度值。位数越高,每个像素可以表达的颜色或灰度级别就越多,图像的色彩表现力也越丰富。
1. 不同位数图像的类型
根据图像的位数,图像可以分为以下几种常见类型:
a. 1位图像(1-bit image)
- 每个像素1位:1位图像每个像素只能用1个二进制位来表示,因此它只能表示2种状态:0或1。
- 颜色表示:通常是黑白图像。0表示黑色,1表示白色。
- 应用场景:这种图像常用于简单的图形设计或文本图像(如条形码、QR码)。
b. 8位图像(8-bit image)
- 每个像素8位:8位图像每个像素有8个二进制位,因此可以表示 (2^8 = 256) 种颜色或灰度级别。
- 灰度图像:在灰度图像中,8位图像表示从0(黑色)到255(白色)之间的256个灰度级别。
- 应用场景:常用于单通道灰度图像,或具有256种颜色的彩色图像(通常为调色板图像,使用特定的颜色表)。
c. 24位图像(24-bit image)
- 每个像素24位:24位图像每个像素有24个二进制位,通常分为三个8位的部分,每个部分表示一个颜色通道:红色(Red)、绿色(Green)和蓝色(Blue)。
- 颜色表示:每个通道的8位可以表示256种颜色,因此总共可以表示 (256 \times 256 \times 256 = 16,777,216) 种颜色,即通常所说的“真彩色”。
- 应用场景:这种图像被广泛用于显示器、摄影、网页设计等需要丰富颜色表现的场景。
d. 32位图像(32-bit image)
- 每个像素32位:32位图像在24位图像的基础上,增加了8位的透明度通道(Alpha通道),即RGBA模式。
- 透明度表示:Alpha通道用来表示像素的透明度,0表示完全透明,255表示完全不透明。
- 应用场景:用于需要处理透明图像的场景,比如图像合成、视频编辑、图形设计等。
e. 更高位数的图像(例如48位、64位图像)
- 更高位数:48位图像通常意味着每个通道有16位(即总共有3个通道×16位=48位),而64位图像则通常用于高动态范围(HDR)图像,每个通道有16位或32位。
- 高色深:这种图像可以表示更丰富的颜色梯度,非常适合需要高度精确颜色表现的专业图形设计、医学成像或科学数据可视化等领域。
2. 位数对图像质量的影响
- 颜色范围(Color Range):随着图像位数的增加,图像可以表现的颜色或灰度范围变得更广。例如,8位图像的每个通道只能表示256种颜色,而16位图像的每个通道可以表示65536种颜色。
- 色带效应(Banding Effect):低位数图像在颜色渐变区域可能出现色带效应(即明显的颜色分界线),这是因为颜色过渡不够平滑。高位数图像可以减少这种效应,提供更平滑的色彩渐变。
- 文件大小:图像的位数越高,每个像素所需的存储空间也就越大,因此图像文件的大小也会随之增加。例如,同样大小的图像,32位图像比24位图像的文件大小要大得多。
- 计算和处理复杂度:高位数图像在处理和计算时需要更多的资源,特别是在图像编辑、渲染等涉及大量像素操作的场景中。
AI视频基础
【一】Sora模型的整体架构是什么样的?
虽然Sora模型暂未开源,但是Rocky相信2024年之后的主流AI视频大模型的架构都将在Sora模型架构的基础上进行扩展创新,是AI视频领域从业者必须要熟悉的“核心基础架构” 。
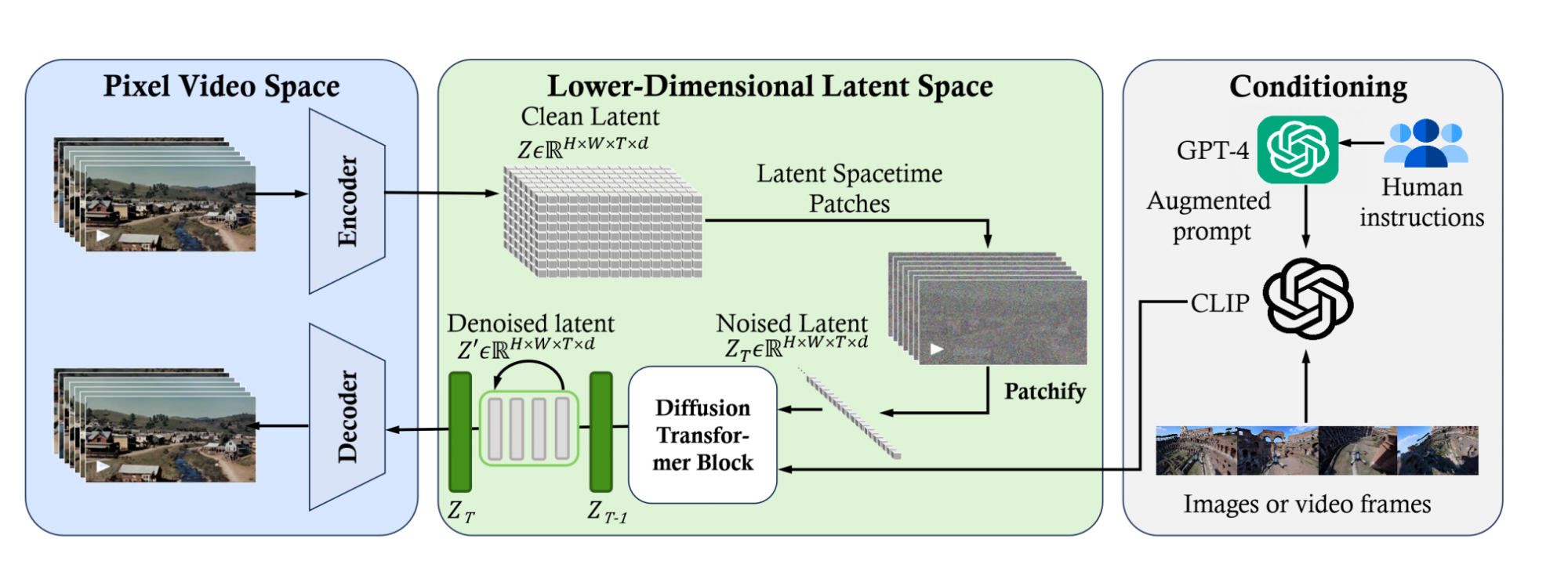
Sora模型是AI视频领域第一个基于DiT架构(diffusion transformer)的大模型,具有灵活的采样维度,如上图所示。Sora主要包括三个部分:
- 3D VAE模型:3D VAE Encoder能在时间和空间维度上将输入的原始视频映射到Latent空间中。同时3D VAE Decoder能将扩散模型生成的视频Latent特征进行重建,获得像素级视频内容。
- 基于DiT的扩散模型架构:使用类似于ViT(视觉转换器)的处理方式将视频的Latent特征进行Patch化,并进行扩散过程输出去噪后的视频Latent特征。
- 一个类似CLIP模型架构的条件接收机制:接收经过大型语言模型(LLM)增强的用户输入Prompt和视觉信息的Prompt,用以引导扩散模型生成具有特定风格或者主题的视频内容。
【二】CogVideoX模型的整体架构是什么样的?
CogVideoX是基于DiT架构的AI视频大模型,可以说DiT架构已经经过考验,成为AI视频领域的核心基底模型。
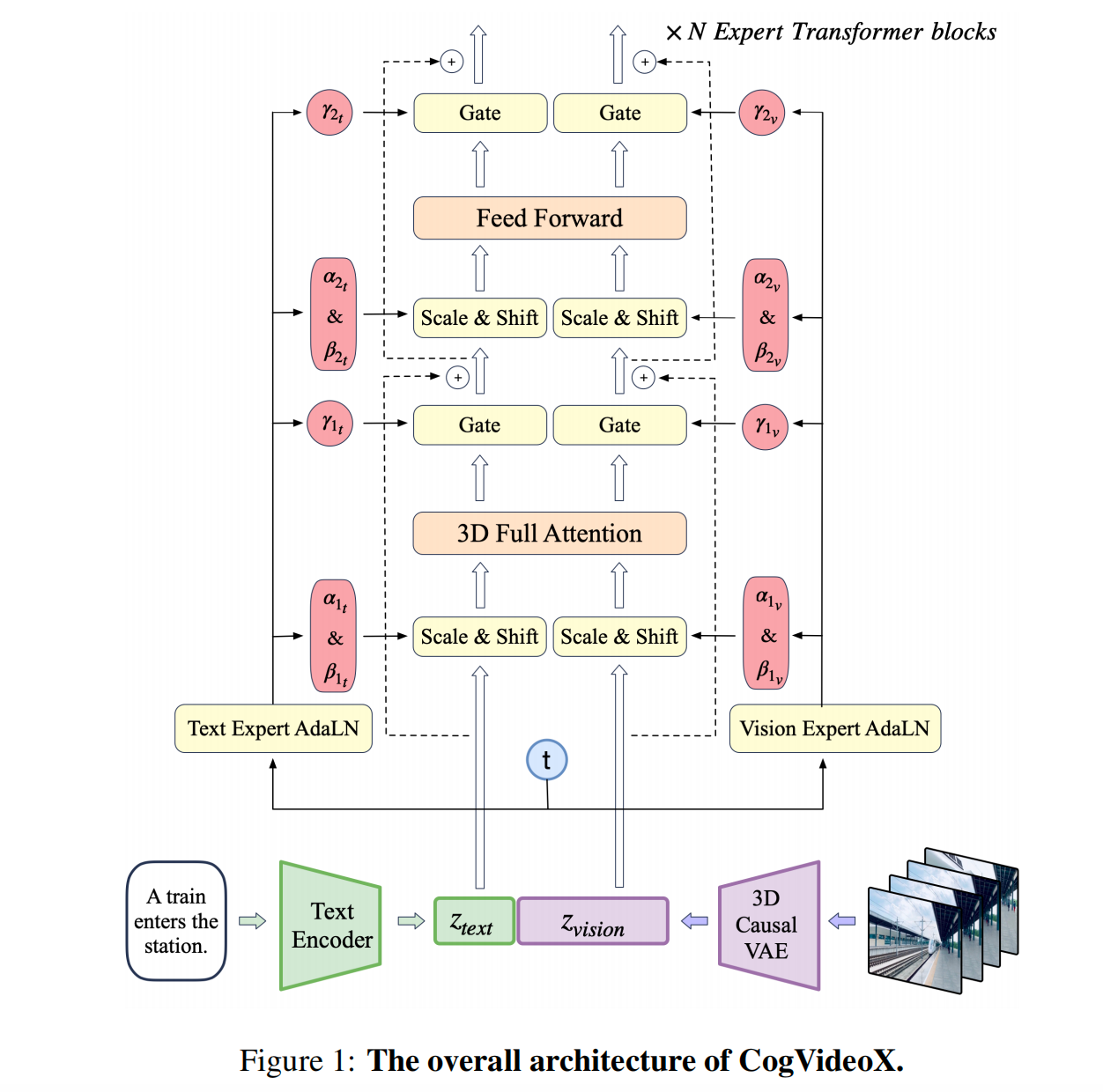
CogVideoX主要包括三个部分:
- 3D Causal VAE模型:3D Causal VAE Encoder能在时间和空间维度上将输入的原始视频映射到Latent空间中。同时3D Causal VAE Decoder能将扩散模型生成的视频Latent特征进行重建,获得像素级视频内容。
- DiT Expert模型:将视频信息的Latent特征和文本信息的Embeddings特征进行Concat后,再Patch化,并进行扩散过程输出去噪后的视频Latent特征。
- Text Encoder模型:Text Encoder模型将输入的文本Prompt编码成Text Embeddings,作为条件注入DiT Expert模型中。CogVideoX中选用T5-XXL作为Text Encoder,Text Encoder具备较强的文本信息提取能力。
目前CogVideoX-2B的输入Prompt提示词上限为226个tokens,可以生成的视频长度为6秒,帧率为8帧/秒,生成视频分辨率为720*480。
深度学习基础
【一】什么是GELU激活函数?
首先我们看一下GELU激活函数的公式:
G E L U ( x ) = 0.5 × x × ( 1 + tanh ( 2 π × ( x + 0.044715 × x 3 ) ) ) GELU(x) = 0.5 \times x \times \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}} \times \left(x + 0.044715 \times x^3\right)\right)\right) GELU(x)=0.5×x×(1+tanh(π2×(x+0.044715×x3)))
了解了GELU激活函数的计算机制后,我们再将其与经典的ReLU激活函数、Sigmoid激活函数进行比较,能够更好的理解GELU激活函数的优势,下面是三者的对比图:
其中 x 代表输入的网络权重参数。
假设我们设置输入值为 x=1.0,最终可以得到GELU激活函数的输出值为:
G E L U ( 1.0 ) = 0.5 × 1.0 × ( 1 + 0.683675 ) = 0.5 × 1.0 × 1.683675 ≈ 0.8418375 GELU(1.0) = 0.5 \times 1.0 \times (1 + 0.683675) = 0.5 \times 1.0 \times 1.683675 \approx 0.8418375 GELU(1.0)=0.5×1.0×(1+0.683675)=0.5×1.0×1.683675≈0.8418375
了解了GELU激活函数的计算机制后,我们再将其与经典的ReLU激活函数、Sigmoid激活函数进行比较,能够更好的理解GELU激活函数的优势,下面是三者的对比图:
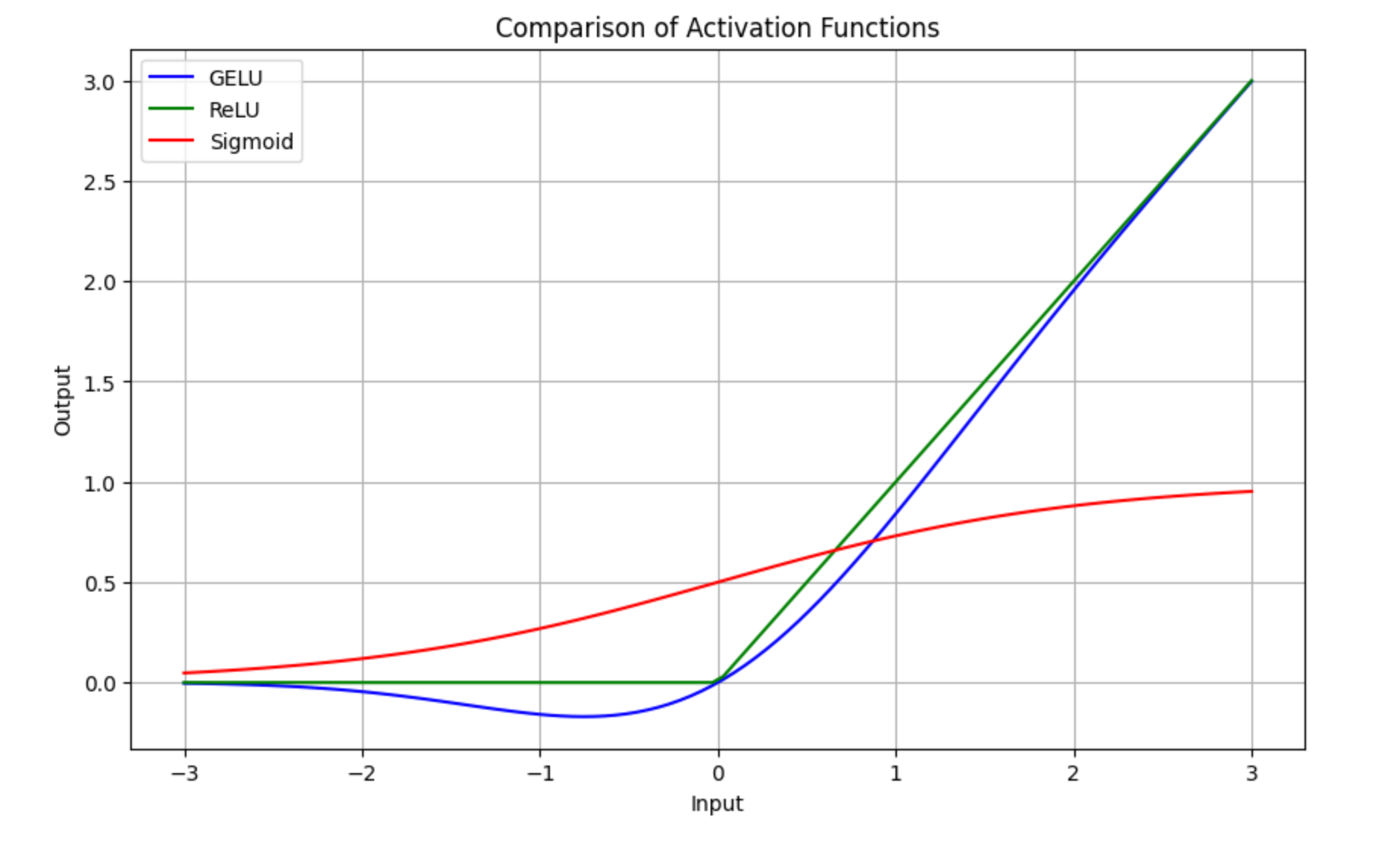
从上图可以看出:
- ReLU激活函数在输入为正数时,输出与输入相同;在输入为负数时,输出为0。它非常简单但会完全忽略负值的输入。
- Sigmoid激活函数输出在 0 到 1 之间平滑过渡,适合在某些分类任务中使用,但可能会导致梯度消失问题。
- GELU激活函数比 ReLU 更平滑,并且在负值附近不会直接剪切到 0。它让负值小幅保留,避免了完全忽略负输入,同时保留了 ReLU 在正值区间的主要优点。
总的来说,GELU是一种更平滑的激活函数,能更好地保留输入的细微信息,尤其是在处理负值时。通过结合多种非线性运算(如 tanh 和多项式),GELU 提供了比 ReLU 更平滑和复杂的输出,有助于AI模型在训练过程中更好地捕捉数据中的复杂特征与模式。
【二】T5LayerNorm和LayerNorm的区别是什么?
比起标准的层归一化(Layer Normalization),T5LayerNorm主要特点是只对网络的权重参数进行缩放(scale),而不进行偏移(shift)。T5LayerNorm的主要公式如下:
T5LayerNorm ( x ) = x Var ( x ) + ϵ × weight \text{T5LayerNorm}(x) = \frac{x}{\sqrt{\text{Var}(x) + \epsilon}} \times \text{weight} T5LayerNorm(x)=Var(x)+ϵx×weight
- x x x 是输入的张量。
- Var ( x ) \text{Var}(x) Var(x) 是 x x x 的方差,计算方式是对每个元素平方后求平均值。
- ϵ \epsilon ϵ 是一个小常数,用于防止除零错误,确保数值稳定性。
- weight \text{weight} weight 是一个可训练的参数,用来缩放输出。
总的来说,T5LayerNorm的关键在于:
- 只进行缩放,不进行偏移:它不像LayerNorm那样先减去均值再缩放,它只根据输入数据的方差进行缩放。
- 处理方式简洁但有效:通过对输入数据的平方均值进行归一化,T5LayerNorm保持了简洁性,并且这种归一化方式在处理较高维度的输入时非常高效。
- 适应高维数据:T5LayerNorm特别适用于AIGC大模型中的高维数据输入,因为它能够在保持数值稳定性的同时,减少不必要的计算量。
正是上述的这些特点使得T5LayerNorm成为AI视频大模型中非常实用的归一化方法。
机器学习基础
【一】机器学习中的Embeddings特征的本质是什么?
在机器学习中,Embedding特征的本质是将高维、稀疏或类别特征映射到一个低维的、密集的向量空间中,同时保留并捕捉特征之间的语义关系。它通过优化输入表示,使得机器学习模型能够更加有效地学习数据中的模式和关系。
1. 特征向量化
Embedding 是一种特征向量化的过程。原始的输入数据(如单词、物品ID、用户ID等)通常是离散的、类别性的,并且维度可能非常高。例如,假设我们有一个包含数百万个单词的词汇表,每个单词可以看作是一个独立的类别。如果直接使用这些类别作为输入,模型将难以有效处理,因为这些类别通常用独热编码(one-hot encoding)表示,这会导致极高维度且非常稀疏的输入向量。
Embedding通过将这些高维的类别特征映射到低维的向量空间中,使得原本稀疏的、离散的表示变成了密集的、连续的向量。这些向量通常具有较低的维度,并且能够捕捉类别之间的语义相似性。
2. 语义信息的捕捉
Embedding 的一个关键特性是它可以捕捉到类别之间的语义关系。在文本处理中,类似的单词会在Embedding空间中靠得更近,例如“猫”和“狗”可能会具有相似的向量表示,因为它们在语义上是相近的。这种语义关系可以通过模型在训练数据上学习到,并在Embedding空间中反映出来。
3. 模型输入的优化
Embedding特征为模型提供了更加紧凑且有意义的输入表示,使得模型能够更好地学习和泛化。通过将高维的离散特征压缩到低维的连续空间,模型不仅减少了计算复杂度,还能够更好地捕捉特征之间的隐含关系。
4. 可学习性
Embedding 特征通常是通过模型训练得到的。在训练过程中,Embedding 矩阵的权重会不断更新,以便更好地满足特定任务的目标。这意味着 Embedding 不仅是一种数据预处理方式,更是一种可学习的表示方法,它随着模型的训练不断优化,进而提高模型在特定任务上的性能。
5. 广泛应用
Embedding 特征在多个领域得到了广泛应用,包括自然语言处理(词嵌入)、推荐系统(用户和物品的嵌入)、计算机视觉(图像特征的嵌入)等。在这些应用中,Embedding 帮助模型更好地理解和处理复杂的输入数据,提升了模型的预测能力。
【二】AI行业主要有哪些核心的数据模态?
在AI领域中,数据模态(Data Modalities)指的是不同类型的数据形式。每种模态数据都有其特定的结构和特点,AI模型必须以不同的方式处理它们。以下是一些主要的数据模态的详细解释:
1. 视觉模态(Visual Modality)
- 类型:图像、视频
- 人类信息接收比例:约占人类感知信息的80%左右。
- 描述:
- 图像和视频是人类最重要的感知形式,视觉模态的数据主要用于计算机视觉领域的任务,如图像分类、目标检测、语义分割、人脸识别、目标追踪、图像生成、视频生成、视频分析等。
- 视觉数据的主要特点是高维度、结构化等。
2. 听觉模态(Auditory Modality)
- 类型:声音、语音、音乐
- 人类信息接收比例:约占人类感知信息的10-15%左右。
- 描述:
- 听觉模态包括声音和语音数据,音频信号是随时间变化的一维数据,但其频域特征也非常重要。
- 在AI领域中,听觉模态主要应用于语音识别、语音合成、情感识别、音乐推荐、声纹识别等任务。
3. 语言模态(Textual Modality)
- 类型:文本、自然语言
- 人类信息接收比例:人类直接通过语言获取的信息占比约为7-10%,但如果考虑通过阅读、学习获取的信息,比例会更高。
- 描述:
- 语言模态包括所有形式的书面或口头语言,它是人类交流的核心工具。文本数据通常是离散的、高度结构化的序列数据、代表符号或词汇。
- 在AI领域中,语言模态被用于任务如机器翻译、情感分析、文本生成、问答系统等。
4. 触觉模态(Tactile Modality)
- 类型:压力、振动、温度、纹理
- 人类信息接收比例:约占人类感知信息的1-2%。
- 描述:
- 触觉模态涉及通过皮肤感知物理特性,如压力、温度、质地等。这种感知在机器人、假肢控制、虚拟现实中非常重要。
- 在AI领域中,触觉数据通常来源于传感器阵列,需要进行高分辨率的时空分析。应用包括机器人抓取、材料识别、触觉反馈系统等。触觉模态的处理通常与其他模态结合,如视觉和运动,来提供更丰富的感知和交互能力。
5. 运动模态(Kinematic Modality)
- 类型:位置、速度、加速度、角度、姿态
- 人类信息接收比例:占比很小,但在特定任务如运动控制中非常重要。
- 描述:
- 运动模态涉及对物体或人体的运动轨迹、速度、加速度等的感知。它在运动捕捉、机器人导航、虚拟现实等领域尤为重要。
- 这类数据通常由加速度计、陀螺仪、摄像机等传感器捕获,在应用中经常与其他数据模态结合进行多模态融合分析。
6. 多模态融合(Multimodal Fusion)
- 类型:结合上述多种模态的数据
- 描述:
- 多模态融合是指结合来自不同感知通道的数据,以获得更全面的信息表示。例如,在自动驾驶中,视觉(摄像头)、雷达、激光雷达和运动传感器的数据融合,可以提供更加可靠的环境感知能力。
- 处理多模态数据的挑战在于如何有效地整合不同模态的信息,因为它们的数据结构和特性通常不同。
Python编程基础
【一】介绍一下如何使用Python中的fastapi构建AI服务
使用 FastAPI 构建一个 AI 服务是一个非常强大和灵活的解决方案。FastAPI 是一个快速的、基于 Python 的 Web 框架,特别适合构建 API 和处理异步请求。它具有类型提示、自动生成文档等特性,非常适合用于构建 AI 服务。下面是一个详细的步骤指南,我们可以从零开始构建一个简单的 AI 服务。
1. 构建基本的 FastAPI 应用
首先,我们创建一个 Python 文件(如 main.py),在其中定义基本的 FastAPI 应用。
from fastapi import FastAPIapp = FastAPI()@app.get("/")
def read_root():return {"message": "Welcome to the AI service!"}
这段代码创建了一个基本的 FastAPI 应用,并定义了一个简单的根路径 /,返回一个欢迎消息。
2. 引入 AI 模型
接下来,我们将引入一个简单的 AI 模型,比如一个预训练的文本分类模型。假设我们使用 Hugging Face 的 Transformers 库来加载模型。
在我们的 main.py 中加载这个模型:
from fastapi import FastAPI
from transformers import pipelineapp = FastAPI()# 加载预训练的模型(例如用于情感分析)
classifier = pipeline("sentiment-analysis")@app.get("/")
def read_root():return {"message": "Welcome to the AI service!"}@app.post("/predict/")
def predict(text: str):result = classifier(text)return {"prediction": result}
在这个例子中,我们加载了一个用于情感分析的预训练模型,并定义了一个 POST 请求的端点 /predict/。用户可以向该端点发送文本数据,服务会返回模型的预测结果。
3. 测试我们的 API
使用 Uvicorn 运行我们的 FastAPI 应用:
uvicorn main:app --reload
main:app指定了应用所在的模块(即main.py中的app对象)。--reload使服务器在代码更改时自动重新加载,适合开发环境使用。
启动服务器后,我们可以在浏览器中访问 http://127.0.0.1:8000/ 查看欢迎消息,还可以向 http://127.0.0.1:8000/docs 访问自动生成的 API 文档。
4. 通过 curl 或 Postman 测试我们的 AI 服务
我们可以使用 curl 或 Postman 发送请求来测试 AI 服务。
使用 curl 示例:
curl -X POST "http://127.0.0.1:8000/predict/" -H "Content-Type: application/json" -d "{\"text\":\"I love WeThinkIn!\"}"
我们会收到类似于以下的响应:
{"prediction": [{"label": "POSITIVE","score": 0.9998788237571716}]
}
5. 添加请求数据验证
为了确保输入的数据是有效的,我们可以使用 FastAPI 的 Pydantic 模型来进行数据验证。Pydantic 允许我们定义请求体的结构,并自动进行验证。
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import pipelineapp = FastAPI()classifier = pipeline("sentiment-analysis")class TextInput(BaseModel):text: str@app.get("/")
def read_root():return {"message": "Welcome to the AI service!"}@app.post("/predict/")
def predict(input: TextInput):result = classifier(input.text)return {"prediction": result}
现在,POST 请求 /predict/ 需要接收一个 JSON 对象,格式为:
{"text": "I love WeThinkIn"
}
如果输入数据不符合要求,FastAPI 会自动返回错误信息。
6. 异步处理(可选)
FastAPI 支持异步处理,这在处理 I/O 密集型任务时非常有用。假如我们的 AI 模型需要异步调用,我们可以使用 async 和 await 关键字:
from fastapi import FastAPI
from pydantic import BaseModel
from transformers import pipelineapp = FastAPI()classifier = pipeline("sentiment-analysis")class TextInput(BaseModel):text: str@app.get("/")
async def read_root():return {"message": "Welcome to the AI service!"}@app.post("/predict/")
async def predict(input: TextInput):result = await classifier(input.text)return {"prediction": result}
在这个例子中,我们假设 classifier 可以使用 await 异步调用。
7. 部署我们的 FastAPI 应用
开发完成后,我们可以将应用部署到生产环境。常见的部署方法包括:
-
使用 Uvicorn + Gunicorn 进行生产级部署:
gunicorn -k uvicorn.workers.UvicornWorker main:app -
部署到云平台,如 AWS、GCP、Azure 等。
-
使用 Docker 构建容器化应用,便于跨平台部署。
【二】介绍一下Python中常用的标准库以及功能
Python 提供了丰富的标准库,这些库为我们提供了常用的工具和功能,涵盖了从操作系统交互、文件处理、数据序列化、网络通信到多线程编程等方方面面。这些标准库大大简化了我们的工作,使得开发高效、稳定、易于维护的应用程序变得更加容易。在实际项目中,熟练掌握和合理运用这些标准库,可以显著提高我们的开发效率和代码质量。
1. os
- 功能:
os模块提供了一种与操作系统进行交互的便捷方式。我们可以使用它来处理文件和目录、管理环境变量、执行操作系统命令等。 - 常用功能:
os.path: 用于路径操作(如路径拼接、文件名提取)。os.makedirs(): 创建多层目录。os.getenv(): 获取环境变量。os.system(): 执行系统命令。
2. sys
- 功能:
sys模块提供了与 Python 解释器相关的函数和变量,允许我们与解释器进行交互。 - 常用功能:
sys.argv: 命令行参数列表。sys.exit(): 终止程序运行。sys.path: 模块搜索路径列表,可以动态修改。sys.stdout/sys.stderr: 输出流和错误流的重定向。
3. math
- 功能:
math模块提供了基本的数学函数和常量,如三角函数、对数、指数、平方根、常数(如π)等。 - 常用功能:
math.sqrt(): 计算平方根。math.sin(),math.cos(),math.tan(): 三角函数。math.log(): 计算对数(自然对数和其他基数对数)。math.factorial(): 计算阶乘。
4. datetime
- 功能:
datetime模块用于处理日期和时间,支持日期的算术运算、格式化、解析等操作。 - 常用功能:
datetime.date: 表示日期(年、月、日)。datetime.time: 表示时间(时、分、秒、毫秒)。datetime.datetime: 表示日期和时间的组合。datetime.timedelta: 表示两个日期或时间的差。datetime.strftime(): 格式化日期和时间为字符串。datetime.strptime(): 从字符串解析日期和时间。
5. time
- 功能:
time模块提供了与时间相关的函数,如暂停、获取当前时间等。 - 常用功能:
time.time(): 返回当前时间的时间戳(自1970-01-01以来的秒数)。time.sleep(): 让程序暂停指定的时间(秒)。time.localtime(): 将时间戳转换为本地时间的结构体。time.strftime(): 格式化时间为字符串。
6. random
- 功能:
random模块用于生成伪随机数,并提供了随机选择、打乱顺序等功能。 - 常用功能:
random.random(): 返回0到1之间的随机浮点数。random.randint(a, b): 返回a到b之间的随机整数。random.choice(): 从序列中随机选择一个元素。random.shuffle(): 随机打乱序列顺序。random.sample(): 从序列中随机取样。
7. re
- 功能:
re模块提供了正则表达式的支持,允许你在字符串中进行复杂的模式匹配、查找和替换。 - 常用功能:
re.match(): 从字符串的起始位置进行匹配。re.search(): 在字符串中查找模式的首次出现。re.findall(): 查找字符串中所有符合模式的部分。re.sub(): 替换字符串中符合模式的部分。
8. json
- 功能:
json模块提供了将 Python 对象转换为 JSON 格式,以及将 JSON 数据解析为 Python 对象的功能。 - 常用功能:
json.dump(): 将 Python 对象序列化为 JSON 格式,并写入文件。json.dumps(): 将 Python 对象序列化为 JSON 格式的字符串。json.load(): 从文件中读取 JSON 数据并解析为 Python 对象。json.loads(): 将 JSON 字符串解析为 Python 对象。
9. subprocess
- 功能:
subprocess模块允许我们生成子进程,并与其交互,代替旧的os.system()方法。 - 常用功能:
subprocess.run(): 运行命令并等待其完成。subprocess.Popen(): 启动一个子进程,并可以通过stdin,stdout,stderr与其交互。subprocess.call(): 执行命令并返回状态码。
10. collections
- 功能:
collections模块提供了几个有用的容器数据类型,如Counter,deque,defaultdict,namedtuple等。 - 常用功能:
Counter: 用于计数的字典,可以统计元素出现的次数。deque: 双端队列,支持在两端高效地添加和删除元素。defaultdict: 带有默认值的字典。namedtuple: 定义命名元组,可以像对象一样访问元素。
11. itertools
- 功能:
itertools模块提供了用于操作迭代器的函数,用于高效地处理循环和组合生成器等任务。 - 常用功能:
itertools.chain(): 将多个迭代器连接在一起。itertools.cycle(): 无限循环一个迭代器。itertools.permutations(): 生成序列的所有排列。itertools.combinations(): 生成序列的所有组合。itertools.product(): 生成笛卡尔积。
12. functools
- 功能:
functools模块提供了处理和操作函数的工具,支持部分函数应用、缓存、比较等功能。 - 常用功能:
functools.partial(): 创建一个部分应用的函数。functools.lru_cache(): 通过缓存来优化函数性能。functools.reduce(): 累积地将函数应用于序列的元素。
13. threading
- 功能:
threading模块支持多线程编程,允许我们在 Python 中创建和管理线程。 - 常用功能:
threading.Thread(): 创建并启动一个新线程。threading.Lock(): 实现线程间的互斥锁。threading.Event(): 用于线程间通信的同步原语。threading.Timer(): 延迟执行的线程。
14. multiprocessing
- 功能:
multiprocessing模块提供了支持并行处理的功能,通过在多个进程中分配任务来提高计算效率。 - 常用功能:
multiprocessing.Process(): 创建并启动一个新进程。multiprocessing.Pool(): 创建一个进程池,用于并行处理多个任务。multiprocessing.Queue(): 用于进程间通信的队列。multiprocessing.Manager(): 管理共享状态的服务。
15. shutil
- 功能:
shutil模块提供了高级的文件操作功能,如复制、移动、删除文件和目录。 - 常用功能:
shutil.copy(): 复制文件。shutil.move(): 移动文件或目录。shutil.rmtree(): 删除目录及其所有内容。shutil.make_archive(): 创建压缩文件(zip、tar 等)。
16. glob
- 功能:
glob模块用于匹配文件路径名模式,如查找符合特定模式的文件。 - 常用功能:
glob.glob(): 返回符合特定模式的文件路径列表。glob.iglob(): 返回一个迭代器,生成符合模式的文件路径。
17. csv
- 功能:
csv模块提供了读写 CSV 文件的功能,支持多种格式的 CSV 文件操作。 - 常用功能:
csv.reader(): 读取 CSV 文件内容,返回一个可迭代的 reader 对象。csv.writer(): 写入 CSV 文件内容。csv.DictReader(): 以字典的形式读取 CSV 文件。csv.DictWriter(): 以字典的形式写入 CSV 文件。
18. hashlib
- 功能:
hashlib模块提供了用于生成哈希值和摘要的算法,如 SHA-1、SHA-256、MD5 等。 - 常用功能:
hashlib.sha256(): 生成 SHA-256 哈希值。hashlib.md5(): 生成 MD5 哈希值。hashlib.blake2b(): 生成 Blake2b 哈希值。hashlib.sha512(): 生成 SHA-512 哈希值。
19. http
- 功能:
http模块提供了处理 HTTP 请求和响应的功能,包含服务器和客户端相关的工具。 - 常用功能:
http.client: 用于发起 HTTP 请求。http.server: 用于创建简单的 HTTP 服务器。http.cookies: 用于处理 HTTP Cookies。http.HTTPStatus: 枚举 HTTP 状态码。
20. socket
- 功能:
socket模块提供了低级别的网络通信接口,支持 TCP、UDP、IP 等网络协议的编程。 - 常用功能:
socket.socket(): 创建一个套接字对象。socket.bind(): 绑定套接字到地址。socket.listen(): 监听连接。socket.accept(): 接受连接请求。socket.connect(): 连接到远程套接字。
模型部署基础
【一】大模型推理框架介绍
vLLM
vLLM全称Virtual Large Language Model,由Nvidia开源,旨在降低大模型推理的显存占用。其核心思想是将模型的一部分保存在CPU内存或硬盘上,只将当前计算所需的部分加载到GPU显存中,从而打破GPU显存限制。
vLLM支持PyTorch和FasterTransformer后端,可无缝适配现有模型。使用vLLM,在配备96GB内存+440GB A100的服务器上可运行1750亿参数模型,在配备1.5TB内存+880GB A100的服务器上可运行6万亿参数模型。
TensorRT-LLM
Tensorrt-LLM是Nvidia在TensorRT推理引擎基础上,针对Transformer类大模型推理优化的框架。主要特性包括:
- 支持多种优化技术,如kernel融合、矩阵乘优化、量化感知训练等,可提升推理性能
- 支持多GPU多节点部署,可扩展到万亿规模参数
- 提供Python和C++ API,易于集成和部署
在Nvidia测试中,基于OPT-30B在A100上的推理,Tensorrt-LLM可实现最高32倍加速。
DeepSpeed
DeepSpeed是微软开源的大模型训练加速库,最新的DeepSpeed-Inference也提供了推理加速能力,主要特点包括:
- 通过内存优化、计算优化、通信优化,降低推理延迟和提升吞吐
- 支持多GPU横向扩展,单卡可推理数百亿参数模型
- 提供Transformer、GPT、BERT等模型的推理示例
- 集成Hugging Face transformers库,使用简单
在GPT-NeoX测试中,基于DeepSpeed的推理相比原生PyTorch可实现7.7倍加速。
Text Generation Inference
Text Generation Inference(简称TextGen)是Hugging Face主导的开源推理框架,旨在为自然语言生成模型如GPT、OPT等提供高性能推理。主要特点包括:
- 高度优化的核心代码,支持FP16、int8等多种精度
- 支持多GPU多节点扩展,可推理万亿规模参数
- 良好的用户体验,提供Python高层API,简化开发
- 支持Hugging Face生态中的模型,如GPT2、GPT-Neo、BLOOM等
在OPT-175B基准测试中,TextGen可实现最高17倍推理加速。
Torch Dynamo
Torch Dynamo是PyTorch官方开发的一种动态图优化工具,旨在提高PyTorch模型的执行效率。它通过在运行时捕获和跟踪Python代码的执行,动态地将PyTorch的eager模式(即时模式)代码转换为更高效的图模式代码。这一转换使得 PyTorch模型在执行时能够更加接近静态图框架的性能,同时仍然保持PyTorch动态计算图的灵活性。
Torch Dynamo的核心思想是:
- 捕获 Python 函数的执行:在 Python 代码执行时,Torch Dynamo 会捕获函数的执行,分析其逻辑和计算图结构。
- 动态转换:它将捕获的代码转换为一个静态的、高效的中间表示(IR)。这种表示更容易进行进一步的优化,例如内存管理、算子融合等。
- 执行优化的代码:在转换完成后,优化后的代码会被重新执行,以获得更高的执行性能。
这个过程是透明的,对于用户来说,不需要修改现有的 PyTorch 代码。
FullyShardedDataParallel (FSDP)
FullyShardedDataParallel (FSDP) 是 PyTorch 提供的一种分布式数据并行训练技术,专门设计用于大规模模型的高效训练。它通过将模型的参数、梯度和优化器状态全面分片(sharding),并分布在多个 GPU 上,以优化内存使用,提升训练效率。FSDP 尤其适用于处理超大模型,这些模型通常无法在单个 GPU 内存中完全容纳。
FSDP 的工作原理:
-
全分片:
- 在传统的数据并行方法中,每个 GPU 上通常保存一份完整的模型副本,这样在处理超大模型时,会导致显存的巨大浪费。FSDP 的核心思想是将模型的参数、梯度和优化器状态按需分片,并分布在不同的 GPU 上。
- 在每次前向和后向传播时,FSDP 会动态地将所需的分片参数加载到 GPU 上,并在计算完梯度后重新分片。
-
高效的内存管理:
- 通过分片技术,FSDP 可以极大地减少每个 GPU 所需的显存,从而能够处理更大的模型或在同一显存中容纳更多的模型参数。
- 这种内存优化的机制使得即便是在显存资源受限的环境下,也能进行超大规模模型的训练。
-
与 ZeRO 的关系:
- FSDP 是一种全分片的数据并行方法,与 DeepSpeed 的 ZeRO 优化策略有一些相似之处。ZeRO 也通过将模型参数、梯度和优化器状态分散到多个设备上来减少显存使用。FSDP 可以被视为 ZeRO 的一种 PyTorch 原生实现,它与 PyTorch 的其他分布式训练功能高度集成。
Megatron-LM
Megatron-LM 是由 NVIDIA 开发的一种用于训练超大规模语言模型的深度学习框架。随着语言模型规模的不断扩大,训练这些模型变得越来越具有挑战性,特别是在处理数十亿到数万亿参数的模型时。Megatron-LM 专门设计来解决这些挑战,它通过多种并行化技术(如模型并行、数据并行和流水线并行)实现了高效的大规模模型训练。
Megatron-LM 的工作原理:
-
模型并行(Model Parallelism):
- 在模型并行中,Megatron-LM 将一个巨大的模型分割成多个部分,每个部分分配给不同的 GPU。这种方法允许单个模型跨多个 GPU 进行训练,从而突破单个 GPU 显存的限制。
- 具体实现包括将神经网络层或层内的参数矩阵划分到不同的设备上,并行计算。
-
数据并行(Data Parallelism):
- Megatron-LM 也使用了数据并行技术,即将输入数据批次拆分为多个子批次,每个子批次在不同的 GPU 上独立计算梯度。然后,梯度在所有 GPU 之间进行同步,以确保模型参数的一致更新。
- 数据并行是深度学习中常见的并行化方法,特别是在处理大型数据集时非常有效。
-
流水线并行(Pipeline Parallelism):
- 为了进一步提高并行计算效率,Megatron-LM 引入了流水线并行。这种方法将模型的前向和后向传播过程划分为多个阶段,每个阶段在不同的 GPU 上执行。通过流水线并行,不同阶段可以同时进行,从而减少计算的等待时间,提高 GPU 利用率。
- 流水线并行类似于工厂的流水线作业,不同的计算任务在不同的时刻完成,但最终达成整体的并行加速效果。
-
张量并行(Tensor Parallelism):
- Megatron-LM 还支持张量并行,它进一步将模型的张量操作分解为更小的计算单元,这些单元分布在多个 GPU 上。这种方法特别适合处理超大规模的矩阵乘法等操作。
【二】Int8和FP8有哪些区别?
1. Int8和FP8的基础概念
-
INT8(8-bit Integer):
- INT8 是一种使用8位表示的整数数据类型。整数类型是定点数,没有小数部分,可以是有符号或无符号的。通常在AI领域中,INT8 表示的范围是 -128 到 127(有符号整数)。
- INT8 在AI领域中的应用主要集中在推理阶段,使用定点数代替浮点数可以显著降低内存占用和加速推理过程。
-
FP8(8-bit Floating Point):
- FP8 是一种使用8位表示的浮点数数据类型。与整数不同,浮点数可以表示非常小或非常大的值,通过使用指数和尾数的组合来表示。FP8 的典型表示法包括 1 位符号位、4 位指数位和 3 位尾数位。
- FP8 通常用于训练和推理中,以提供比 INT8 更广泛的动态范围和更精确的小数表示。
2. 表示范围和精度
-
INT8:
- INT8 使用定点数表示法,表示范围是固定的。如果是有符号整数,范围为 -128 到 127。
- 由于它是整数类型,INT8 没有小数部分,这意味着它只能表示离散的整数值。
-
FP8:
- FP8 使用浮点数表示法,表示范围取决于指数的数量。由于 FP8 通常使用 4 位指数,它可以表示更广泛的动态范围,尽管精度较低。
- FP8 可以表示非常小的和非常大的数值,并且可以表示小数部分,但由于只有3位尾数,精度有限。
3. 使用场景和性能
-
INT8:
- 推理阶段的优化:INT8 主要用于AI模型推理阶段的优化。在将模型转换为 INT8 时,通常需要进行量化(quantization)处理。这种量化通过缩小数值的表示范围和精度,使得模型更适合低功耗设备如移动设备或嵌入式系统。
- 性能和存储优势:INT8 可以显著减少内存占用和加快计算速度,尤其是在使用专用硬件(如 NVIDIA TensorRT、Intel DL Boost)时,推理速度可以显著提高。
-
FP8:
- 训练和推理中的使用:FP8 被提出作为在AI训练和推理中一种可能的低精度计算方案。相比 INT8,FP8 在表示动态范围上更有优势,因此在某些情况下可能比 INT8 更适合训练和推理。
- 平衡精度和性能:FP8 在精度和动态范围之间取得了平衡,适用于一些需要在精度和计算性能之间进行权衡的应用。FP8 尤其适合用于混合精度训练中,与 FP16 或 FP32 一起使用,以优化性能。
4. 优势和限制
-
INT8:
- 优势:
- 内存占用小:只需要8位存储空间,极大地减少了内存使用。
- 计算速度快:适用于推理优化,在现有硬件上有良好的支持,特别是在移动设备和嵌入式系统中。
- 限制:
- 精度有限:由于没有小数部分,在处理需要精细数值的场景时可能不适用。
- 量化复杂:从 FP32 转换为 INT8 需要精细的量化策略,以减少精度损失。
- 优势:
-
FP8:
- 优势:
- 更广泛的动态范围:可以表示更大或更小的数值,适用于一些需要小数精度的场景。
- 混合精度训练:可以与其他浮点精度结合使用,平衡性能和精度。
- 限制:
- 精度仍然有限:虽然比 INT8 有小数表示,但由于只有3位尾数,精度在一些场景中可能不足。
- 目前支持有限:FP8 作为一种新兴的精度格式,目前在硬件支持和工具链上还不如 INT8 成熟。
- 优势:
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】在计算机中有哪些常用的读写操作,每个读写操作的性能是什么样的?
在计算机中,读写操作是处理数据的基本操作之一,涉及将数据从一个存储介质(如内存、硬盘、缓存等)读取到另一个存储介质,或将数据从一个存储介质写入到另一个存储介质。在AI行业中,稳健的读写操作往往是AI算法解决方案的关键一环,如果其中的读写操作不恰当,往往会造成AI算法解决方案的性能瓶颈。下面Rocky带大家详细了解一下计算机中的主要读写操作以及它们的性能。
1. 内存读写(Memory Access)
- 操作描述:内存读写指的是从主内存(RAM)中读取数据或向其中写入数据。
- 时间效率:
- 内存访问的时间通常在纳秒级(几十到几百纳秒),这是因为内存是直接连接到CPU的,访问速度非常快。
- 读取操作和写入操作的时间通常是对称的,但这取决于具体的内存架构。
- 空间效率:
- 内存的空间效率取决于其容量和数据的对齐方式。计算机中通常使用字节(byte)为单位的对齐方式,可能会在某些情况下为了性能进行对齐填充(padding),这可能会浪费一些空间。
- 应用场景:内存读写操作广泛应用于几乎所有的计算任务中,因为它是最基础的数据存储与访问方式。
2. 磁盘读写(Disk I/O)
- 操作描述:磁盘读写指的是从磁盘(HDD或SSD)中读取数据或将数据写入磁盘。
- 时间效率:
- HDD:机械硬盘(HDD)的读写时间在毫秒级(通常为5-10毫秒),因为涉及机械部件的寻道和旋转延迟。
- SSD:固态硬盘(SSD)的读写时间在微秒级(几十到几百微秒),因为它没有机械部件,完全依赖电子电路进行数据传输。
- 读取操作通常比写入操作快,特别是在SSD中,因为写入涉及数据擦除和编程操作(即擦写周期)。
- 空间效率:
- 磁盘的空间效率通常较高,尤其是SSD,其数据存储是以页(page)为单位的,HDD则是以扇区(sector)为单位的。
- 磁盘具有较大的存储容量,但也可能存在碎片化的问题,特别是在HDD中,这会降低访问速度。
- 应用场景:磁盘读写操作用于长期数据存储和访问,常见于文件存储、数据库操作、操作系统分页等场景。
3. 缓存读写(Cache Access)
- 操作描述:缓存读写指的是在CPU缓存(L1, L2, L3缓存)中读取或写入数据。缓存是位于CPU和主内存之间的快速存储层。
- 时间效率:
- L1缓存:访问时间在几个纳秒以内,通常是CPU时钟周期的1-3个周期。
- L2缓存:访问时间稍慢,通常在10-20纳秒左右。
- L3缓存:更大且更慢,访问时间通常在几十纳秒左右。
- 缓存的时间效率高,但容量有限,因此缓存命中率(cache hit rate)对性能影响很大。
- 空间效率:
- 缓存的空间效率较低,因为缓存容量相对较小,通常是几MB到几十MB不等。
- 为了提高命中率,缓存使用复杂的管理策略,如LRU(最近最少使用)或LFU(最少使用)等,可能会有一些空间开销。
- 应用场景:缓存读写操作主要用于提升CPU的计算效率,常用于频繁访问的数据。
4. 网络读写(Network I/O)
- 操作描述:网络读写指的是通过网络接口读取数据或将数据写入网络,这包括通过TCP/IP协议进行的通信。
- 时间效率:
- 网络传输的时间效率受多种因素影响,包括带宽、延迟、抖动等。
- 传输延迟通常在毫秒到秒级,例如跨大西洋的通信延迟大约为70-150毫秒。
- 读取和写入操作的时间可能会有差异,具体取决于网络状况和数据传输协议。
- 空间效率:
- 网络读写的空间效率取决于数据包的大小和传输协议的开销。通常会有一些空间用于协议头信息,如IP头、TCP/UDP头等。
- 在大规模传输时,可能会使用压缩技术来提高空间效率。
- 应用场景:网络读写操作广泛用于互联网通信、分布式系统、云计算等场景。
5. 文件读写(File I/O)
- 操作描述:文件读写是指从文件系统中读取文件内容或将数据写入文件。
- 时间效率:
- 文件I/O的时间效率取决于底层存储设备(HDD、SSD)的性能。读取和写入时间通常包括打开文件、寻址、读取/写入数据和关闭文件的时间。
- 大文件的读写可能比小文件更有效率,因为减少了打开/关闭文件的开销,但可能会受到存储碎片化的影响。
- 空间效率:
- 文件系统管理着文件的存储和空间分配,通常会有一些元数据开销,如文件头信息、权限信息等。
- 某些文件系统可能会有碎片化问题,影响空间效率和读取速度。
- 应用场景:文件读写操作是常见的持久化存储方式,广泛应用于所有需要数据存储的场景,如文档管理、日志记录、数据备份等。
6. 数据库读写(Database I/O)
- 操作描述:数据库读写指的是从数据库中读取数据(查询)或将数据写入数据库(插入、更新)。
- 时间效率:
- 数据库的读写操作时间效率取决于数据库类型(如SQL数据库、NoSQL数据库)、查询复杂度、索引情况、底层存储介质等。
- 查询可能涉及磁盘I/O、内存访问、缓存命中等因素,复杂查询可能需要几毫秒到几秒时间。
- 写入操作通常会包括事务管理、日志记录等,可能会比读取稍慢。
- 空间效率:
- 数据库的空间效率取决于数据结构、索引、表设计和压缩技术。关系型数据库通常会有较高的空间开销用于索引和冗余。
- 为了提高访问效率,数据库可能会在磁盘上占用更多的空间(如冗余存储、分片等)。
- 应用场景:数据库读写操作广泛应用于应用程序的持久化存储、数据分析、实时数据处理等场景。
7. GPU读写(GPU Memory Access)
- 操作描述:GPU读写指的是将数据从CPU内存传输到GPU内存(或反向)进行计算,或在GPU内存之间进行数据交换。
- 时间效率:
- CPU与GPU之间的数据传输通常通过PCIe总线,时间在微秒到毫秒级。
- GPU内存(如GDDR6)内部的访问时间非常快,通常在纳秒级,适合大规模并行计算。
- 数据传输(特别是大数据量的传输)可能成为计算中的瓶颈。
- 空间效率:
- GPU内存的空间效率与内存管理策略有关,通常为高效处理大规模并行数据而设计。
- GPU内存通常较为紧凑,内存容量从几GB到几十GB不等,因此管理较为严格,要求数据对齐和最小化冗余。
- 应用场景:GPU读写操作广泛应用于图形渲染、深度学习、科学计算等需要大规模并行计算的场景。
【二】在AI行业中两个服务器之间的通信有哪些注意事项?
在AI行业中,两个服务器之间的通信涉及到大量的数据传输和计算,这对通信的效率、可靠性和安全性提出了更高的要求。我们需要确保AI系统中服务器间通信的高效、安全和可靠,从而支持复杂的AI应用场景,如分布式训练、模型部署和大数据处理等。以下是两个服务器之间通信时需要特别注意的事项,结合AI应用的具体场景进行了详细解释:
1. 数据传输效率
-
大数据传输:AI应用通常需要处理大量的数据集,如训练数据、模型权重等。为了提高传输效率,可以采用以下措施:
- 压缩数据:使用压缩算法(如gzip、lz4)在传输前对数据进行压缩,减少带宽占用。
- 增量传输:对于模型更新,采用差分更新的方式,仅传输变化部分(如参数更新、权重差异),而不是每次传输整个模型。
- 分片传输:将大数据集分割成较小的数据块,以并行方式进行传输,可以显著提高传输速度。
- 异步传输:使用异步通信机制,避免服务器等待数据传输完成后再执行其他任务,从而提高整体效率。
-
带宽利用:在两个服务器之间的数据传输中,带宽是一个关键因素。为了最大化带宽利用率,可以:
- 多线程传输:使用多线程或多通道技术同时传输多个数据块,提升带宽利用率。
- 流量控制:在传输大量数据时,使用流量控制技术防止网络拥塞,并确保传输的稳定性。
2. 数据安全性
- 加密传输:AI模型、训练数据等通常包含敏感信息,因此需要使用强加密机制(如TLS/SSL)进行数据传输,防止数据在传输过程中被截获或篡改。
- 端到端加密:确保从源服务器到目标服务器的整个传输路径都是加密的,不仅是在传输通道中加密,还要保护存储在服务器上的数据。
- 身份验证:确保通信双方是经过验证的服务器,防止中间人攻击或伪装服务器接入网络。
- 双向认证:在AI模型和数据传输过程中,采用双向认证机制(如X.509证书)以确保通信双方的合法性。
3. 容错性和可靠性
- 断点续传:AI行业中的数据传输任务可能非常庞大且耗时较长,通信中断可能导致数据传输失败。使用断点续传技术,在通信中断后重新建立连接时,从中断的地方继续传输数据。
- 冗余传输:为了防止数据丢失,可以在关键数据传输时采用冗余传输,即在传输过程中增加校验机制或在多个路径上同时传输数据,以确保数据传输的完整性和可靠性。
- 备份机制:在传输前后,定期对重要数据进行备份,确保在通信失败或数据损坏时能够快速恢复。
4. 同步与一致性
- 模型和数据的一致性:在AI系统中,多个服务器可能需要共享同一组模型或数据,确保各服务器之间的数据和模型一致性至关重要。可以使用分布式版本控制系统或一致性协议(如Paxos、Raft)来管理。
- 分布式锁:在多台服务器之间共享模型或数据时,使用分布式锁(如Zookeeper、Etcd)来防止并发写操作导致的数据冲突或不一致性。
5. 通信协议与API设计
-
协议选择:选择合适的通信协议对于保证数据传输的性能和可靠性至关重要,如TCP、UDP、HTTP/HTTPS、WebSocket等。
- gRPC:一种高性能、开源的远程过程调用(RPC)框架,支持多语言,是AI行业中常用的跨服务器通信协议。
- RESTful API:基于HTTP的API设计,简单易用,适用于传输频率不高的AI服务通信。
- 消息队列:在需要异步通信或解耦服务器之间的依赖时,使用Kafka、RabbitMQ等消息队列来缓冲数据并确保数据传输的可靠性。
-
API设计:良好的API设计可以提升服务器间通信的效率和易用性。
- 幂等性:确保API在多次调用时具有幂等性,即多次调用产生相同的结果,防止重复操作引发的错误。
- 版本控制:随着AI模型的更新,API接口可能会发生变化,采用版本控制机制确保新旧接口能够兼容。
6. 性能监控与优化
- 实时监控:部署实时监控系统(如Prometheus、Grafana)监控服务器之间的通信状态,包括带宽使用率、数据包丢失率、传输延迟等,及时发现并解决问题。
- 负载均衡:对于多服务器通信,使用负载均衡器(如Nginx、HAProxy)分配通信流量,防止单一服务器负载过重,并提高整体通信效率。
- 缓存:在AI系统中,某些计算结果或中间数据可以在服务器之间缓存,减少重复计算和数据传输,提升效率。
7. 跨地域通信
- 地理分布的延迟:AI服务器可能分布在全球各地,通信延迟和带宽差异是不可避免的。可以使用CDN(内容分发网络)或边缘计算节点来减少延迟,并提高跨地域通信的效率。
- 数据合规性:跨国通信时,需遵循各国的数据隐私法律(如GDPR),确保数据传输过程中的合规性和安全性。
8. 边缘计算与云端通信
- 边缘计算节点:在AI应用中,边缘计算用于处理靠近数据源的计算任务,减少通信延迟和带宽消耗。确保边缘设备与云端服务器之间的通信可靠且高效。
- 混合云架构:在混合云架构中,通信可能在本地服务器和云端服务器之间进行,确保云端和本地的数据同步和一致性至关重要。
9. 数据格式与序列化
- 高效数据格式:选择适当的数据格式传输AI模型和数据,如使用Protocol Buffers、MessagePack等高效的二进制序列化格式,减少数据体积并提高传输速度。
- 版本兼容性:在传输模型和数据时,确保不同版本的模型和数据格式兼容,以避免在反序列化时出现错误。
10. 合法性与合规性
- 数据隐私和安全性:在AI系统中,数据隐私和安全性是重中之重。确保在通信中遵循行业标准和法规(如GDPR),对敏感数据进行适当的加密和匿名化处理。
- 审计和合规:记录通信日志,并定期审计,以确保通信过程符合企业和行业的合规要求。
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】我们如何降低下一个Transformer式技术价值的错判率?
Rocky认为这是一个非常值得我们持续思考的问题,AI行业的技术迭代是永无止尽的,终身学习贯穿AI行业从业者的整个职业生涯,所以需要领悟沉淀一套挖掘预判下一个Transformer式技术的能力与方法论。
【二】未来会有新的技术替代Transformer吗?哪种技术的概率最大?
Rocky认为这是一个非常有价值的问题,就像从CNN走向Transformer一样,我们需要有一定的前置预判能力。
推荐阅读
1、加入AIGCmagic社区知识星球
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、ChatGPT等大模型、AI多模态、数字人、全行业AIGC赋能等50+应用方向,内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AIGC模型、AIGC数据集和源码等。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,前200名限量活动价,终身优惠只需199元/年。大家只需要扫描下面的星球优惠卷即可享受初始居民的最大优惠:


2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
9、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能给个star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
10、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
11、GAN网络核心基础知识、深入浅出解析GAN在AIGC时代的应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
12、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
这篇关于AIGC时代算法工程师的面试秘籍(第二十一式2024.8.19-9.1) |【三年面试五年模拟】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









