本文主要是介绍让PDF格式为LLM应用做好准备:探索Marker开源工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在如今的大数据时代,高质量的数据可谓是LLM(大语言模型)应用成功与否的关键因素。然而,大多数文本数据通常以PDF格式存在。这不仅适用于企业文档,也包括个人文件。然而,对于LLM而言,处理PDF文件极其困难。PDF本质上是一种破碎的格式,具有复杂的结构。文档中嵌套了不同数据类型的元素,并且没有统一的布局,这使得从PDF中提取数据变得十分繁琐。此外,不同的编码、字体、格式、表格和图像等问题也给处理PDF文件带来了额外的挑战。
在将PDF文件转换为适合LLM处理的格式时,人们探索了多种方法。例如,有些方法将PDF转换为纯文本以便于解析,然后使用机器学习模型检测PDF布局,再使用光学字符识别(OCR)模型检测PDF中的文本。然而,这些过程都相当繁琐且容易出错。
相比之下,使用Markdown格式处理LLM要容易得多,因为可以轻松将其转换为纯文本。Markdown可以保留原始格式,包括标题、标题、图像和表格等元素,并且LLM可以有效地处理这些结构化的Markdown元素。
Marker:将PDF转换为结构化Markdown的开源工具
本文将向您展示一款开源工具Marker,它可以将复杂的PDF文件转换为结构化的Markdown格式。如果您需要将PDF文件转换为Markdown格式,有一些付费选项,例如Mathplix,可以将PDF转换为Markdown或提取可读文本。如果您更倾向于使用开源选项,可以选择Meta的NuGet项目,但它主要侧重于学术文档。
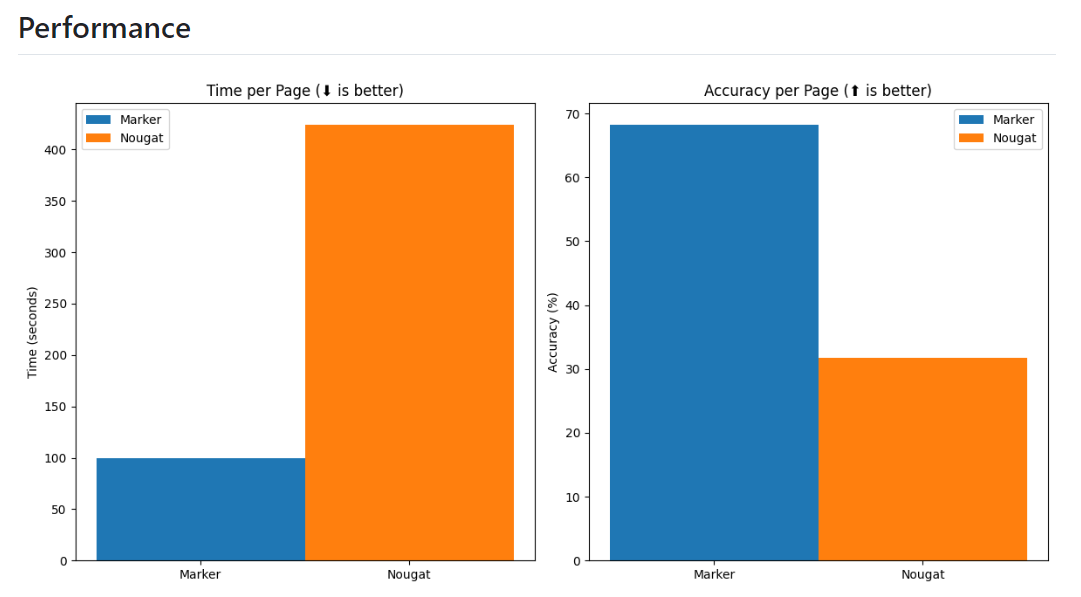
相比NuGet,Marker的性能更优。例如,一页文本使用Marker大约需要100秒,而NuGet需要400秒左右。此外,Marker的准确性几乎是NuGet的两倍。以下是一个将《Think Python》这本书使用NuGet和Marker转换的示例。NuGet在转换过程中忽略了前几页和目录,而Marker能够准确保留所有内容,包括目录和章节。
Marker的特点与局限
Marker支持各种文档类型,特别是书籍和科学论文,但我也测试了简历等其他类型文档,效果也很不错。它支持所有语言,尽管我不确定作者所说的“所有语言”具体指什么。Marker可以去除页眉、页脚和其他多余的元素,并且能够格式化表格和代码块,同时提取和保存图像。它还可以将大多数公式转换为LaTeX格式,具体取决于公式的复杂程度。更棒的是,它可以在GPU、CPU或Apple Silicon上运行。
当然,Marker也有一些局限性。由于PDF格式本身就较为复杂,Marker无法将所有公式100%转换为LaTeX,表格也不总是完全正确地格式化。此外,空白字符有时不会得到完全尊重,行间跨度也可能不会总是正确连接。但在我的测试中,它能够处理大多数PDF文件。
安装和使用Marker
下面是如何开始使用Marker将您的PDF文件转换为结构化Markdown的步骤。
创建新的虚拟环境
首先,我们将创建一个新的Conda环境,并命名为Marker。如果已经有同名环境,可以选择删除现有环境并重新创建。
conda create --name marker python=3.9 conda activate marker
安装PyTorch
安装新的虚拟环境后,还需要安装PyTorch。根据操作系统的不同,安装命令会有所不同。以下是Mac系统的安装命令:
pip install torch torchvision torchaudio
如果您使用的是Linux或Windows,请参考PyTorch官网的安装说明。
安装Marke
接下来,使用以下命令安装Marker:
pip install marker-pdf
如果需要进行OCR,可以选择安装ocrmypdf,这是一个可选包:
pip install ocrmypdf
转换单个PDF文件
安装完成后,可以使用marker_single命令转换单个PDF文件。以下是具体命令格式:
marker_single --pdf_path path/to/your/file.pdf --output_path path/to/output/folder
还可以添加一些可选参数,例如批处理倍数、最大转换页数和文档语言等。
示例与性能对比
以下是几个不同类型文档的转换示例,包括科学论文、简历和其他文档。Marker不仅能够提取图像,还能生成包含元数据的JSON文件,并且能够正确解析大多数表格和公式。
科学论文
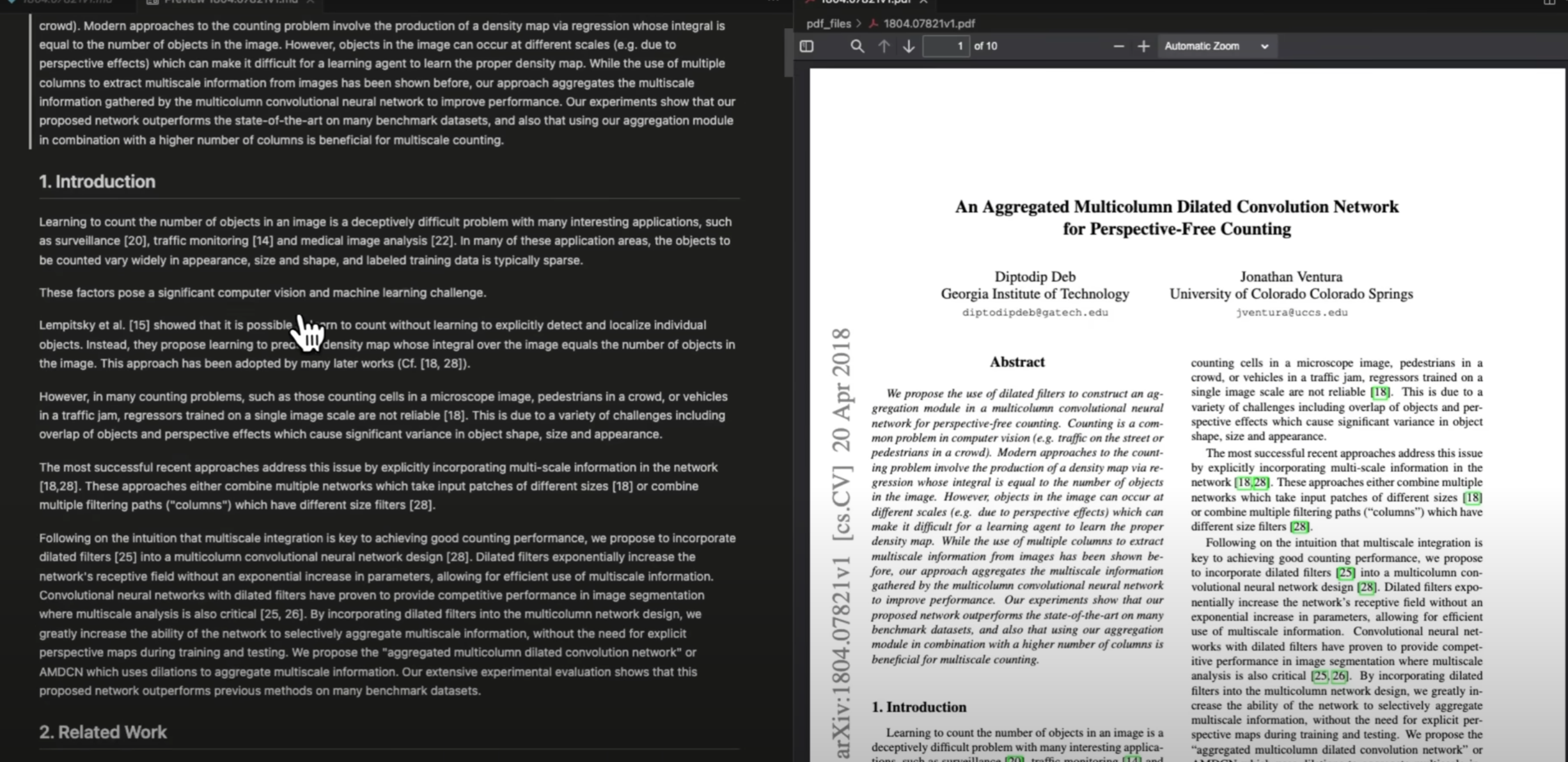
以一个科学论文为例,Marker能够准确提取标题、作者、摘要和图像,并且能够正确格式化表格和公式。生成的Markdown文件结构清晰,保留了原始文档的相对位置。
简历
在简历文档的转换中,Marker同样表现出色,能够正确提取所有信息并生成结构化的Markdown文件。
综合评价
总的来说,Marker作为一个开源工具,能够有效地将复杂的PDF文件转换为结构化的Markdown格式,极大地简化了LLM应用的数据准备过程。
结语
随着数据在LLM应用中的重要性不断提升,像Marker这样的工具为我们提供了便捷的解决方案。希望本文能帮助您更好地理解和使用Marker,将PDF文件转换为结构化Markdown格式。
关注我,每天带你开发一个AI应用,每周二四六直播,欢迎多多交流。

这篇关于让PDF格式为LLM应用做好准备:探索Marker开源工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







