本文主要是介绍Redis高级----五种数据结构及其底层实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目前已更新系列:
当前:Redis高级---面试总结5种数据结构的底层实现
Redis高级----主从、哨兵、分片、脑裂原理-CSDN博客
Redis高级---面试总结内存过期策略及其淘汰策略
计算机网络--面试知识总结一
计算机网络-----面试知识总结二
计算机网络--面试总结三(Http与Https)
计算机网络--面试总结四(HTTP、RPC、WebSocket、SSE)-CSDN博客
知识积累之ThreadLocal---InheritableThreadLocal总结
并发编程之----线程池ThreadPoolExecutor,Excutors的使用及其工作原理
String
String是Redis中最常见的数据类型
其有三种编码格式
- 1、其基本编码格式是RAW,是基于动态字符串(SDS)实现的,储存上限是512mb,如果字符个数大于44个时会采用该编码格式,会为其分配一个RedisObject16个字节的内存空间,然后再为其分配一个SDS的内存空间,之后通过RedisObject中的指针指向该SDS

- 2、当字符串的字符个数小于等于44个时会采用EMBSTR的编码方式,此时object head于SDS是一段连续的空间。这是因为字符数小于44个的话,RedisObject对象头+SDS的总的内存大小就小于64字节,刚好符合Redis的分片大小,将二者变为连续的空间好处就是在为该String申请空间时就只用申请一次,减小内核态线程的切换

- 3、当需要储存的字符串是整数类型是,并且大小在Long_MAX范围内,就会采用INT编码格式,即直接将数据保存在RedisObject的ptr指针位置(刚好8个字节),就不再需要SDS了

List
底层结构:在redis3.2之前list的实现主要使用了LinkecList和ZipList来使用的,当数据量数据量小于512个或者大小小于64字节的时候使用的是ZipList,当数据量较大的时候使用的使用LinkedList来进行储存,因为ZipList底层使用的数组来模拟的双向链表的形式。需要连续的空间,申请代价较大
在3.2后引入QuickList后就解决了该问题,所以在3.2后List使用QuickList来作为为他的底层实现

Set
Set是Redis中的单列结合,其特点是
- 不保证元素的有序性
- 保证元素的唯一性(可以判断元素是否存在)
- 可以求交集、并集、差集

要想实现Set的这些特点,那么对查询的效率的要求就比较高
因此我们可以使用HashTable,也就是Redis中的Dict,不过是Dict双列集合(可以存键、值对)
- 为了查询效率和一致性,set采用HT编码(Dict),只是在将Dict中的key来存储元素,value统一为Null,类似于我们java中hashset的实现,底层也是只是用hashmap的key来存储值,value统一为Null
- 当存储的数据都是整数的时候,并且元素数量不超过set-max-intsett-entries时,Set会采用IntSet编码,来节省内存
注意如果一开始set创建时使用的是intset作为底层的数据结构(即一开始初始化时储存的值是整形),那么当我们要存储字符串时,这是后就会将其底层的类型进行改变,改编成使用Dict类型
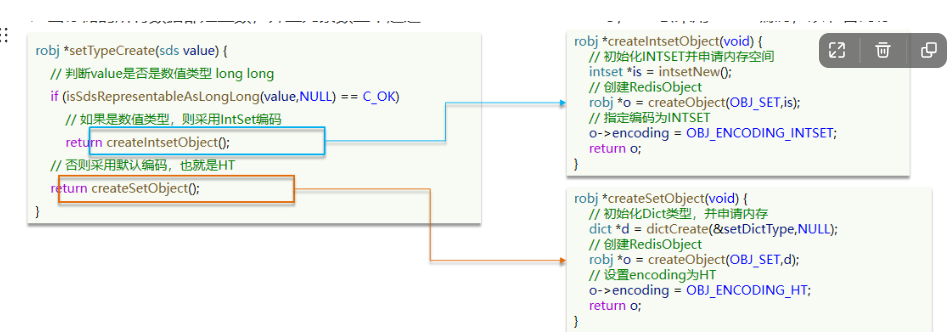

结构如下

Zset
ZSet就是SortedSet,其中每一个元素都需要指定一个score值和member值,根据socre进行排序,同时需要确定member值得唯一性
特点
- 根据score值排序
- member必须唯一
- 可以根据member查询分数

那么根据上面的特点即键唯一,然后能通过键值找到value,同时能按照score排序
- dict:满足key-value形式
- skipList满足排序要求
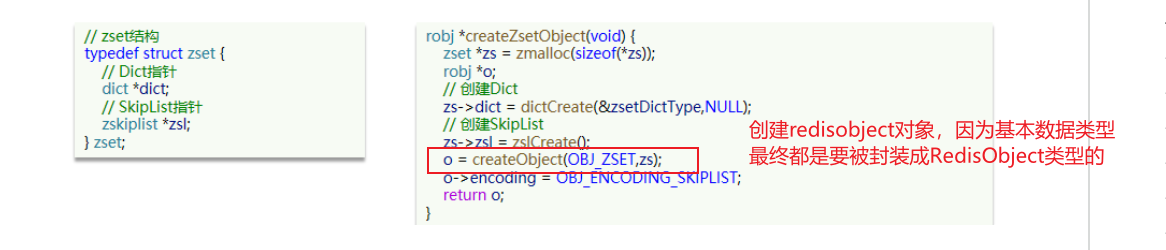

使用这种方式进行存储,查询的效率非常高,但是可能看到,由于它使用了两种数据结构来存储,分别完成排序和key-value得形式,使得内存的暂用非常大,
因此在数据量不大时,HT(hashTable)和SkipList得优势就不明显了,而且更加的消耗内存,因此zset还会使用ZipList节省内存,不过需要满足两个条件
- 元素个数小于zset_max_ziplist_entries,默认值是128
- 每个元素都小于zset_max_ziplist_value字节,默认64字节

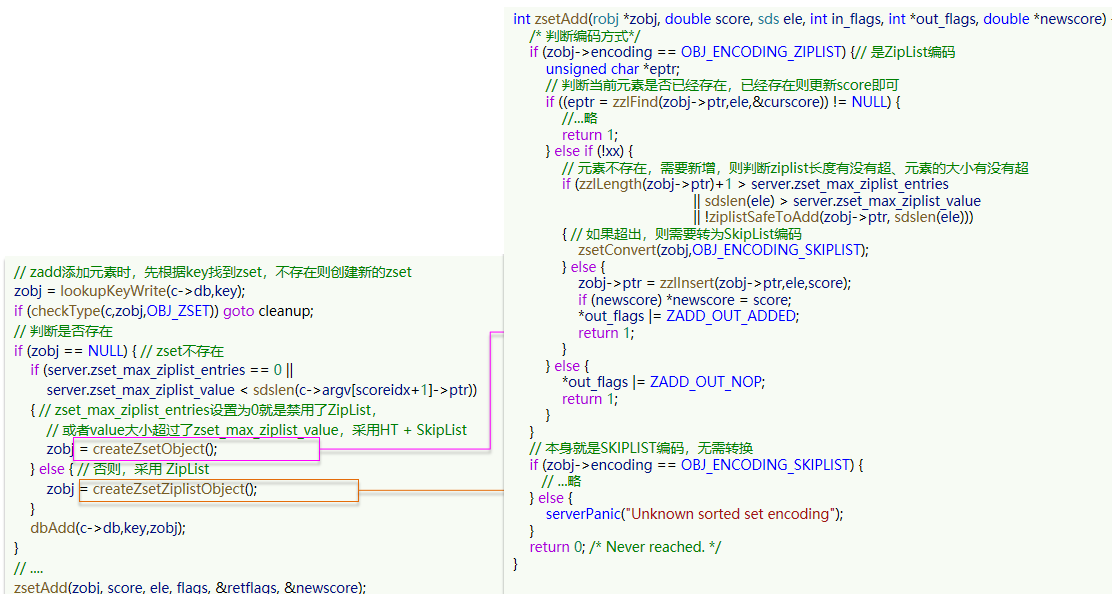
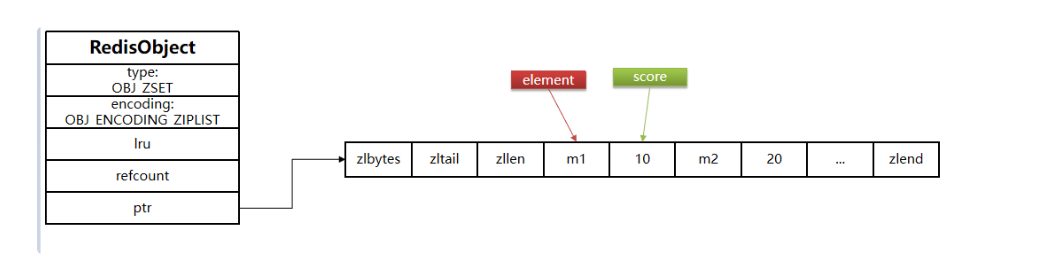
如果使用的时ziplist数据结构来进行存储,那么怎么实现根据score找meberm,和排序得功能?
Redis做了如下处理
- ZipList是连续内存,因此score和element是紧凑在一起的两个entry,element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score升序排列
-
Hash
特点需求
- 都是通过键值存储
- 根据键获取值
- 键必须唯一
需求和ZSet差不多,只是少了排序的功能,因此它的实现可以参照ZSet的底层实现只需要将ZSet部分的SkicpList去掉
- Hash结构默认使用的是ZipList编码,用于节省内存,ZipList中相邻的两个entry分别存放hash中的field和value
- 当数据量比较大时,Hash结构会转化为HT(Dict)编码,触发条件有两个
-
- 当ZipList中的元素个数大于hash_max_ziplist_entried(默认512个)
- 当ZipList中的任意entry大小超过了hash_max_ziplist_value(默认64字节)
-


我靠在这里纠结半天怎么通过key找到field再找value,结果搞忘了,在调用HSetc操作时本来就是没有该key时就创建一个ziplist数据结构,每一个key对应一个压缩列表,然后再从压缩列表中通过filed找到value,傻了
redisDb结构的dict字典保存了数据库中的所有键值对,称为键空间(key space)。所有针对数据库的操作(增删改查),都是操作这个键空间。
注意:这里Redis系列的内容都是之前通过黑马的Redis教程进行学习的,如果不理解或者想理解更加详细可前往小破站学习
这篇关于Redis高级----五种数据结构及其底层实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







