本文主要是介绍12.torchvision中的数据集使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
torchvision中的数据集使用
需要学习知识:
-
如何把数据集(多张图片)和 transforms 结合在一起。
-
标准数据集如何下载、查看、使用。
进入pytorch官网,可以看到pytorch文档里分了不同的块,如下图,标出了常用的几个模块,后面几个不怎么常用
pytorch网站地址:https://pytorch.org/vision/0.9/
各个模块作用
(1)torchvision.datasets
如:COCO 目标检测、语义分割;MNIST 手写文字;CIFAR 物体识别
(2)torchvision.io
输入输出模块,不常用
(3)torchvision.models
提供一些比较常见的神经网络,有的已经预训练好,比较重要,后面会使用到,如分类模型、语义分割模型、目标检测、视频分类等
(4)torchvision.ops
torchvision提供的一些比较少见的特殊的操作,基本不常用
(5)torchvision.transforms
之前讲解过
(6)torchvision.utils
提供一些常用的小工具,如TensorBoard
本节主要讲解torchvision.datasets,以及它如何跟transforms联合使用

CIFAR10数据集
待会用来示例,它一般是用来进行物体识别的

1.数据集如何下载
#如何使用torchvision提供的标准数据集
import torchvisiontrain_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去。用Ctrl加P查看需要参数。
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
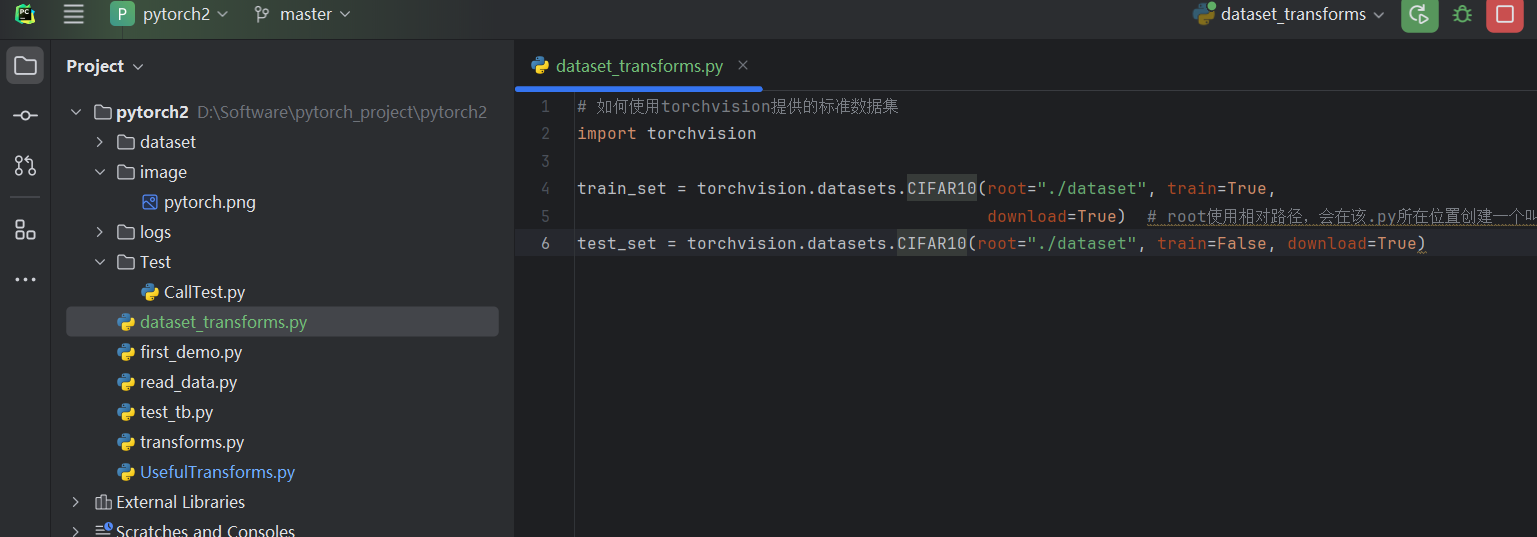
运行结果:
数据集下载过慢时:
获得下载链接后,把下载链接放到迅雷中,会首先下载压缩文件tar.gz,之后会对该压缩文件进行解压,里面会有相应的数据集。采用迅雷下载完毕后,在PyCharm里新建directory,名字也叫dataset,再将下载好的压缩包复制进去,download依然为True,运行后,会自动解压该数据
CIFAR10在迅雷下载完解压到dataset文件夹里,得到cifar-10-batches-py
2.数据集如何查看与使用
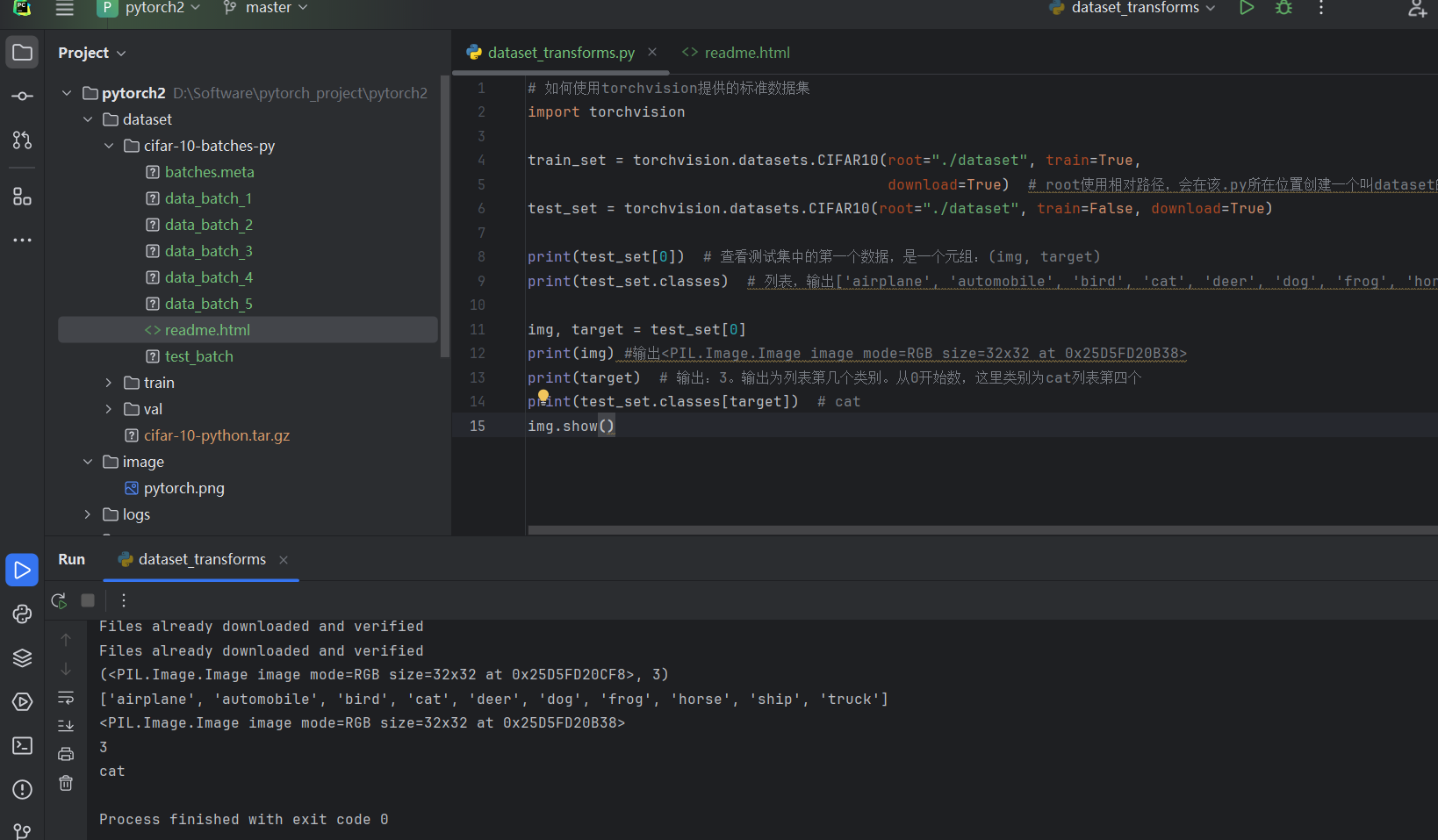
import torchvisiontrain_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)print(test_set[0]) # 查看测试集中的第一个数据,是一个元组:(img, target)
print(test_set.classes) # 列表,输出['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']img, target = test_set[0]
print(img) #输出<PIL.Image.Image image mode=RGB size=32x32 at 0x25D5FD20B38>
print(target) # 输出:3。输出为列表第几个类别。从0开始数,这里类别为cat列表第四个
print(test_set.classes[target]) # cat
img.show()
3.CIFAR10数据集 介绍
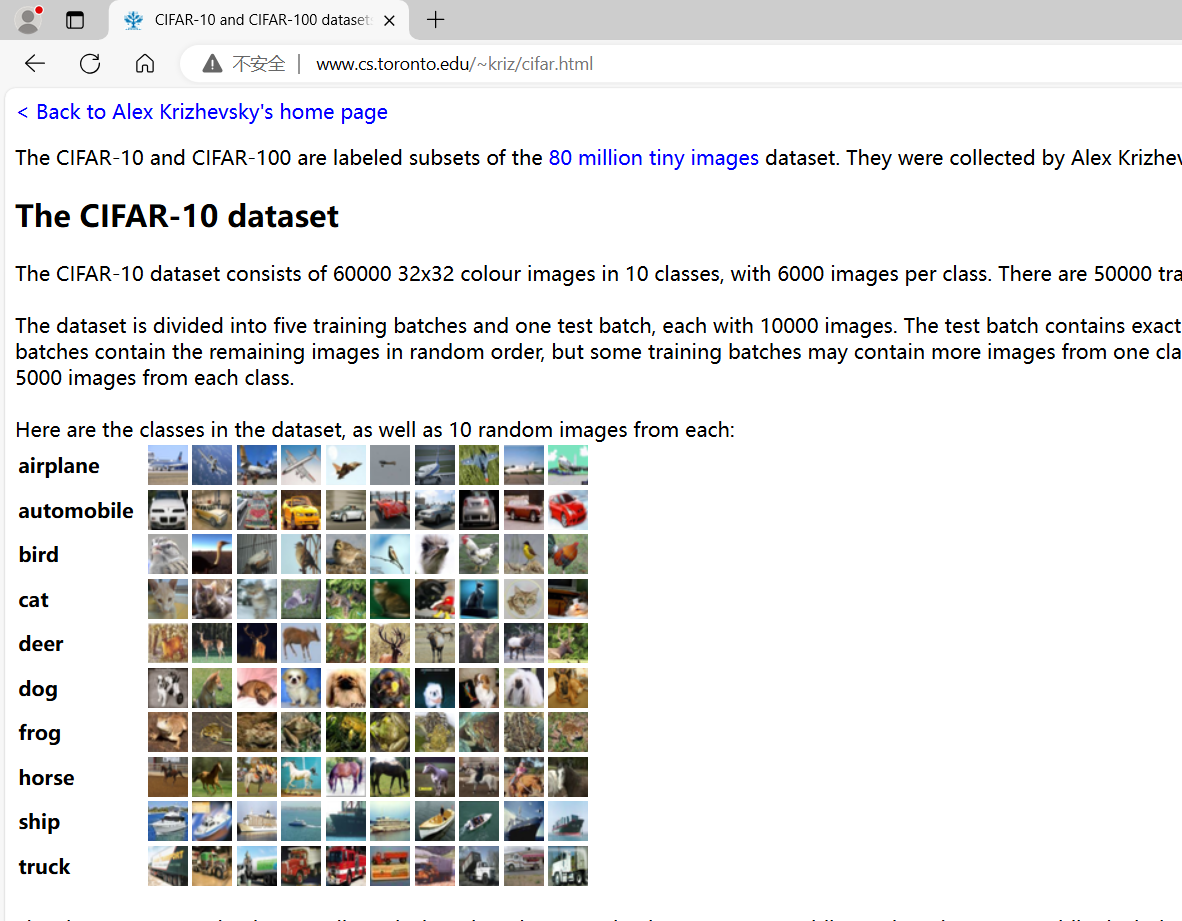
CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片。
如何把数据集(多张图片)和 transforms 结合在一起
CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
transforms 更多地是用在 datasets 里 transform 的选项中
import torchvision
from torch.utils.tensorboard import SummaryWriter#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)# print(test_set[0])writer = SummaryWriter("p10")
#显示测试数据集中的前10张图片
for i in range(10):img,target = test_set[i]writer.add_image("test_set",img,i) # img已经转成了tensor类型writer.close()
运行后在 terminal 里输入
tensorboard --logdir="p10"
可以看到tensorboard中显示了测试数据集中的前10张图片
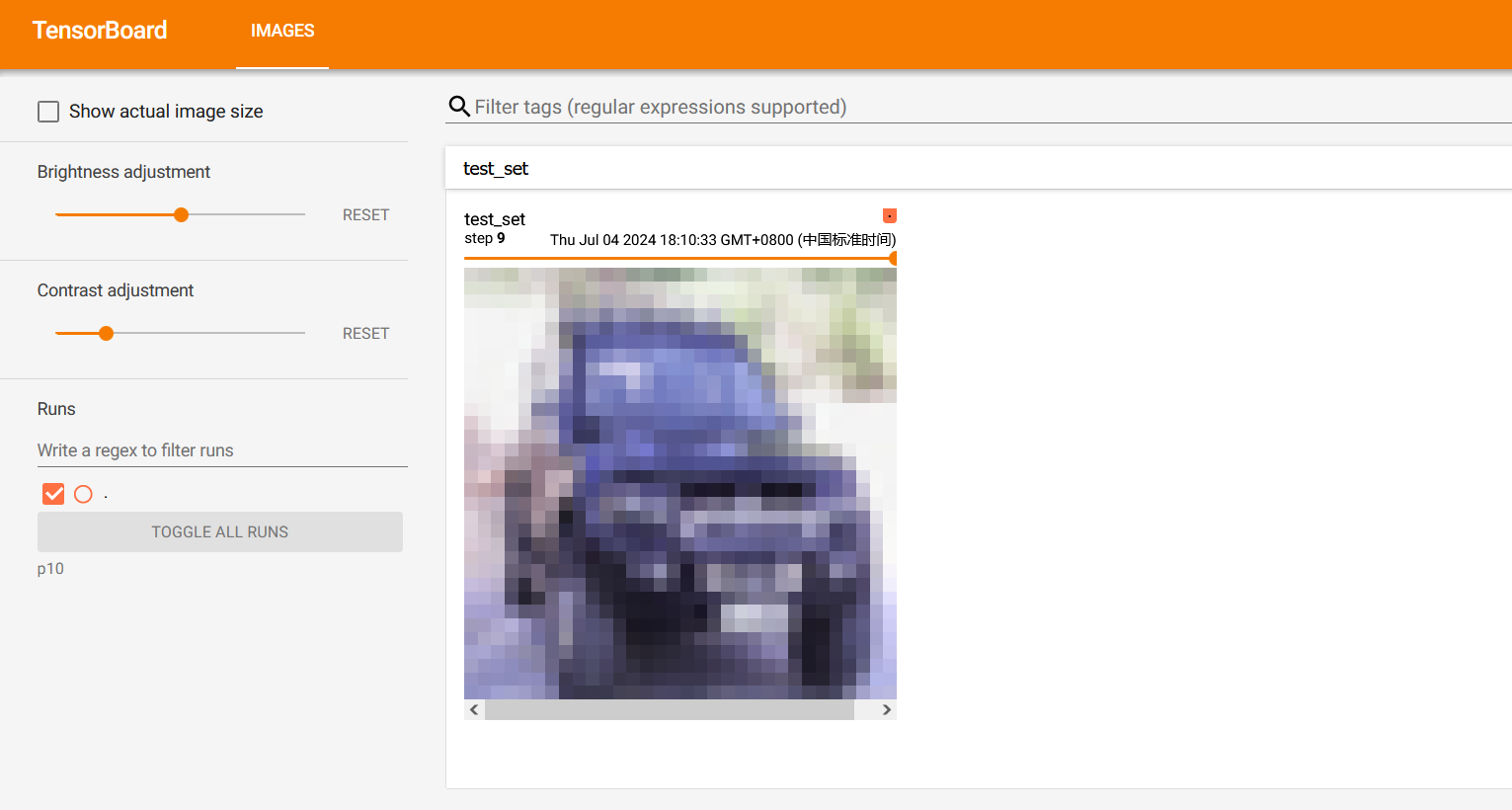
`
运行后在 terminal 里输入
tensorboard --logdir="p10"
可以看到tensorboard中显示了测试数据集中的前10张图片
[外链图片转存中…(img-3xIOAPLq-1724861342898)]
这篇关于12.torchvision中的数据集使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




