本文主要是介绍大模型备案全网最详细流程解读(附附件+重点解读),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
一、语料安全评估
二、黑盒测试
三、模型安全措施评估
四、性能评估
五、性能评估
六、安全性评估
七、可解释性评估
八、法律和合规性评估
九、应急管理措施
十、材料准备
十一、【线下流程】大模型备案线下详细步骤说明
十二、【线上流程】算法备案填报流程及重难点分析
十三、大模型备案时间成本对比
十四、备案建议
附录、过程性材料

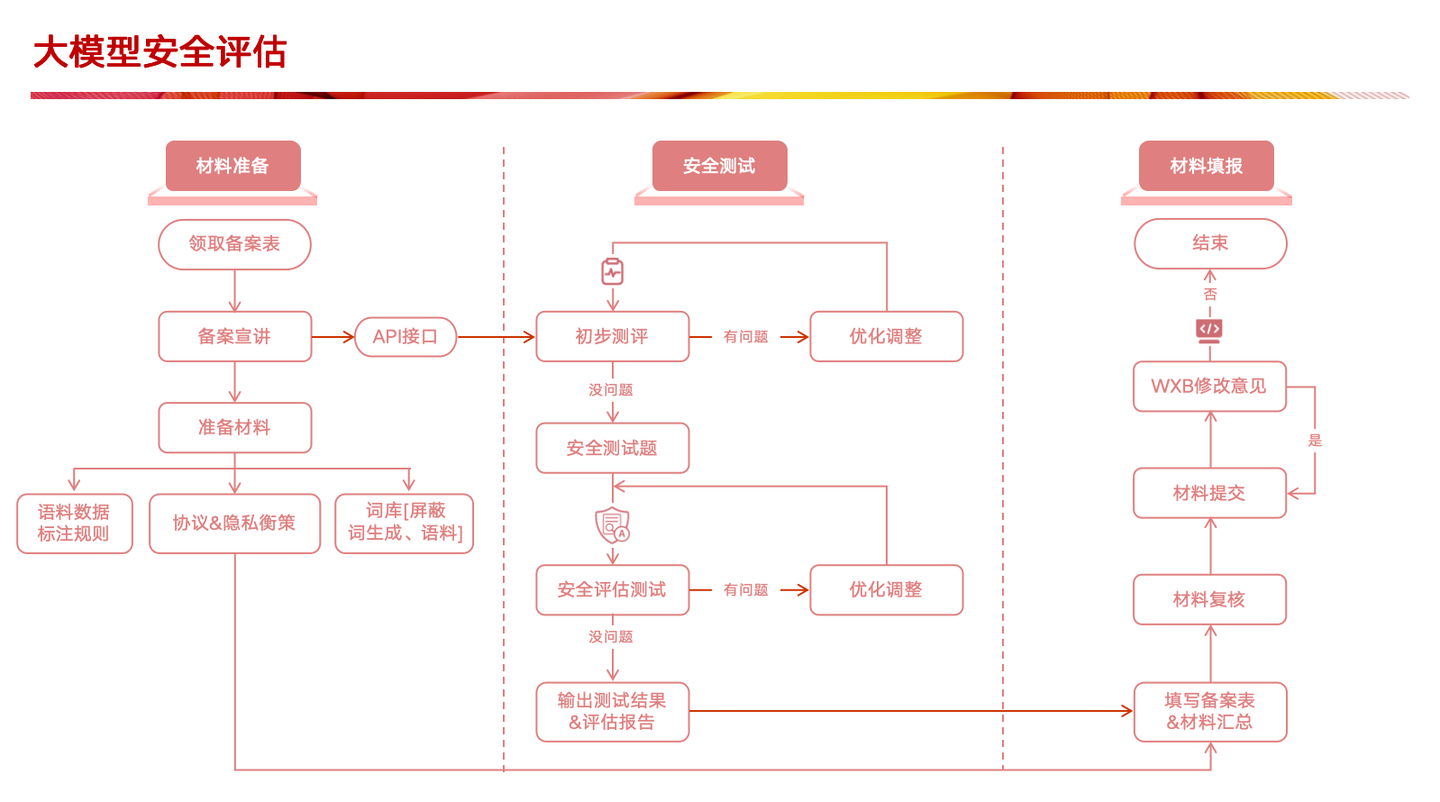
大模型评估流程图
一、语料安全评估:
(一)评估内容
(1)文本训练语料规模 训练语料存储规模,按文本格式存储时的语料大小。 训练语料数量,按词元 (Token) 计数。
(2)各类型语料规模 训练语料中的中文文本、英文文本、代码、图片、音频、 视频及其他语料的规模。
(3)训练语料来源 训练语料来源的组成情况,按照开源语料、自采语料、商业语料进行分类。 境外开源网站语料内中文文本、英文文本、代码、图片、音频、视频及其他语料的规模。 自采语料内中文文本、英文文本、代码、图片、音频、视频及其他语料的规模。 商业语料内中文文本、英文文本、代码、图片、音频、视频及其他语料的规模。
(4)语料标注数量 语料标注的数量,仅限文本和图片,按标注单元计数, 通常按条数、张数。
(5)标注人员情况 标注人员的数量,标注人员的类型,通常包括内部、外包。 标注人员培训时间、培训数量等情况。
(6)标注规则 按照《生成式人工智能服务管理暂行办法》第四条要求制定的标注规则。
(7)标注内容准确性核验 标注内容准确性人工核验比例。
(8)语料合法性 语料来源合法性情况。 语料是否包含侵害他人知识产权内容。 语料是否包含违法违规的个人信息内容。
(二)评估结论
评估结论应包括以下内容:
(1)语料是否符合《生成式人工智能服务管理暂行办法》相关规定,是否含有违反我国法律法规明确禁止的内容。
(2)语料中包含个人信息语料的数量、种类,是否符合《生成式人工智能服务管理暂行办法》规定。
(3)因语料产生知识产权纠纷的风险分析。
(4)防范语料安全风险的措施和建议。
二、黑盒测试
1)功能需求验证: 确保模型能够按照预期执行任务,对各种类型的输入产生正确和合理的输出。
2)用户界面测试: 针对用户界面的测试,确保界面的易用性和一致性。
3)输出验证: 检查模型的输出是否符合预期,是否满足业务需求
*确保模型在不同输入情况下能够按预期执行任务,输出准确、符合预期。包括功能需求的验证,测试模型的各个功能点是否符合设计要求。
三、模型安全措施评估
(1)模型适用人群、场合、用途 服务的适用人群,是否适用未成年人、学生等。 适用场合,是否适用关键信息基础设施、自动控制、医疗信息服务、心理咨询等。 服务范围,是否限定或未限定特定领域。
(2)服务过程中收集保存个人信息情况 服务过程中收集保存个人信息情况,包括个人信息的类型、数量、用途以及保存期限。
(3)收集个人信息征得个人同意情况 收集个人信息征得个人同意的方式。
(4)受理处理使用者查阅、复制、更正、补充、删除个人信息请求的情况 受理处理的条件以及途径方法。
(5)图片、视频标识情况 标识的样式,按1:1 比例贴入。 标识在图片、视频中的具体位置。 标识频度,如每帧、跳帧等。
(6)接受公众或使用者投诉举报情况 接受公众或使用者投诉举报的途径及反馈方式。
(7)服务协议情况 上述1至6内容是否已经写入模型服务协议。
(8)非法内容拦截措施 监看人员的数量。 预置关键词拦截情况,并提供预置关键词拦截列表。 分类模型的检测情况,说明分类模型研制情况和准确性。
(9)拒答率 拒绝回答或者以简单模板回答数量占总测试数量的比率。
(10)模型更新、升级 在何种情况下重新进行预训练,如较频繁发现生成非法
四、性能评估
1)响应时间: 测试模型在不同负载下的响应时间,确保在合理时间内完成任务。
2)资源消耗: 评估模型对内存、计算资源等的消耗情况,确保资源利用合理。 *测试模型的性能,包括响应时间、内存消耗、计算资源占用等。确保模型能够在可接受的时间范围内完成任务,并且对资源的利用合理。
五、稳定性评估
1)长时间运行: 测试模型在持续运行下的稳定性,避免内存泄漏、性能下降等问题。
2)大规模数据输入: 模拟大规模数据输入,检验模型对此的稳定性和性能。
六、安全性评估
1)隐私保护: 确保模型的输出不会侵犯用户隐私,对个人敏感信息进行隐私保护。
2)防止攻击: 测试模型对恶意攻击或异常输入的鲁棒性,确保模型不易受到攻击。
七、可解释性评估
1)对模型的输出进行解释和验证,确保模型的决策是可解释和可信的,避免模型黑盒化带来的问题。
八、法律和合规性评估
1)隐私法规遵守: 确保模型遵循隐私法规,不违反用户隐私和数据使用规定。
2)合规性检查: 确保模型在使用中符合相关行业法规和标准,避免违规操作。 *参考《生成式人工智能服务暂行管理办法》
九、应急管理措施
1)采取防范计算机病毒、网络攻击、网络入侵等技术措施。
2)制定网络安全应急处置预案并且开展应急演练,保存演练记录材料。
3)警用接口建设。
十、材料准备
安全评估报告
模型服务协议
语料标准规则
拦截关键词列表
评估测试题库
拒答测试题库
网络安全管理制度及操作规程
应急处置预案和记录材料
用户投诉举报处理 用户管理制度
个人信息安全保护
安全培训制度
网络安全负责人任命书
十一、【线下流程】大模型备案线下详细步骤说明
第一步:企业向当地网信办申请大模型备案,先确认模型是否需要进行备案(有些只是用开源做微调的,这种小模型一般做算法备案就好,算法备案也简单,具体情况跟网信办确认,不同地区的网信办要求也会有差异)
第二步:填写《生成式人工智能上线备案表》,准备自评估报告材料,评估点参考表格里面提到的6个点进行撰写,每个点进行评估的方法、风险点及应急策略,报告尽量详细点
第三步:当地网信会将报告递交中央网信技术管理局进行审核
第四步:网安多个支队对工作流程及大模型进行上门检查。检查点非常多很多企业被卡主在这 第
五步:等结果
重点内容讲解
自评估和准备材料
1、语料安全评估
(1)评估文本训练语料规模(存储大小、词元计数等)。
(2)明确各类型语料规模(不同语言文本、代码、多媒体等) 。
(3)梳理训练语料来源(开源、自采、商业等分类及来源地等)。
(4)统计语料标注数量(文本和图片标注等)。
(5)明确标注人员情况(数量、类型、培训等)。
(6)制定和检查标注规则(是否符合相关办法要求)。
(7)核验标注内容准确性。
(8)分析语料合法性(有无侵权、违法违规信息等)。
2、模型安全评估:
(1)语料内容评估(人工、关键词、分类模型抽检及合格率等)。
(2)生成内容评估(类似抽检及合格率等)。
(3)涉知识产权、商业秘密等方面的评估(方法、标准、结果)。
(4)涉民族、信仰、性别等方面的评估。
(5)涉透明性、准确性、可靠性等的评估。
3、安全措施评估:
(1)明确模型适用人群(如是否适用未成年人等)、场合(关键信息基础设施等相关敏感场合)、用途(限定领域与否)。
(2)梳理服务过程中收集保存个人信息情况(类型、数量、用途、保存期限)。
(3)确定收集个人信息征得个人同意情况(方式)。
(4)明确受理处理使用者查阅、复制、更正、补充、删除个人信息请求的情况(条件和途径方法)。
(5)规划好图片、视频标识情况(样式、位置、频度等)。
(6)建立接受公众或使用者投诉举报情况(途径及反馈方式)。
(7)完善服务协议(将上述多方面内容写入)。
(8)建立非法内容拦截措施(监看人员数量、预置关键词拦截列表、分类模型检测及准确性等)。
(9)统计拒答率(拒绝回答等数量占比)。
(10)规划模型更新、升级条件(如发现频繁非法等情况时)。
4、材料准备(以下是常见材料举例):
(1)《算法备案承诺书》 。
(2)《落实算法安全主体责任基本情况》 。
(3)《算法安全自评估报告》(较复杂且重要,100页左右,包含附录各种证明材料等;需明确算法原理和逻辑、数据来源合规性、算法透明度和可解释性、安全漏洞检测与应对等)。

安全评估报告摸板
(4)《拟公示内容》。
(5)大模型上线备案表:

大模型上线备案表
基本情况:模型名称、主要功能、适用人群、服务范围等。
模型研制:模型备案情况、训练算力资源(自研模型)、训练语料和标注语料来源与规模、语料合法性、算法模型的架构和训练框架等。
服务与安全防范:推理算力资源、服务方式及对象等、非法内容拦截措施、模型更新升级信息等。
安全评估:基本情况、评估情况。
自愿承诺:承诺所填信息真实性,并签字确认。
附件及备注:附件包括安全评估报告、模型服务协议、语料标注规则、拦截关键词列表、评估测试题。
(6)安全评估报告(涵盖语料安全评估、模型安全评估以及安全措施评估,并形成整体评估结论)。
(7)模型服务协议(包含产品及服务的各项规则及隐私条款等,需协同法务共同制定提交)。
(8)语料标注规则(包括标注团队介绍、功能性及安全性标注细则,标注流程等)。
(9)拦截关键词列表(总规模不宜少于10000个,应至少覆盖《生成式人工智能服务安全基本要求》a.1以及a.2中17种安全风险,a.1中每一种安全风险的关键词均不宜少于200个,a.2中每一种安全风险的关键词均不宜少于100个)。

部分拦截词实例
(10)评估测试题集:

评估测试题部分实例
包括生成内容测试题库、拒答内容测试题库、非拒答测试题库。
要严格覆盖TC260的5大类,31小类。
十二、【线上流程】算法备案填报流程及重难点分析
1、填报入口 登陆互联网信息服务算法备案系统(以下简称备案系统)进行填报, 系统首页如图 1 所示。

图 1 备案系统首页(示意图)
2、填报流程 填报人员需首先注册并登陆备案系统,具体步骤可参考该系 统信息公告中的《互联网信息服务算法备案系统使用手册》。登 录后的主页面如图 2 所示。
图 2 主页面(示意图)
深度合成备案填报包括三个步骤:一是填报主体信息;二是填报算法信息;三是关联产品及功能信息或填报技术服务方式;四是线下审核。 “深度合成服务提供者”(以下简称“服务提供者”)角色 的填报人员需关联产品及功能信息,“深度合成服务技术支持者” (以下简称“服务技术支持者”)角色的填报人员需填报技术服务方式。其中,“服务提供者”是指提供深度合成服务的组织、 个人;“服务技术支持者”是指为深度合成服务提供技术支持的 组织、个人。填报流程如图 3 所示。
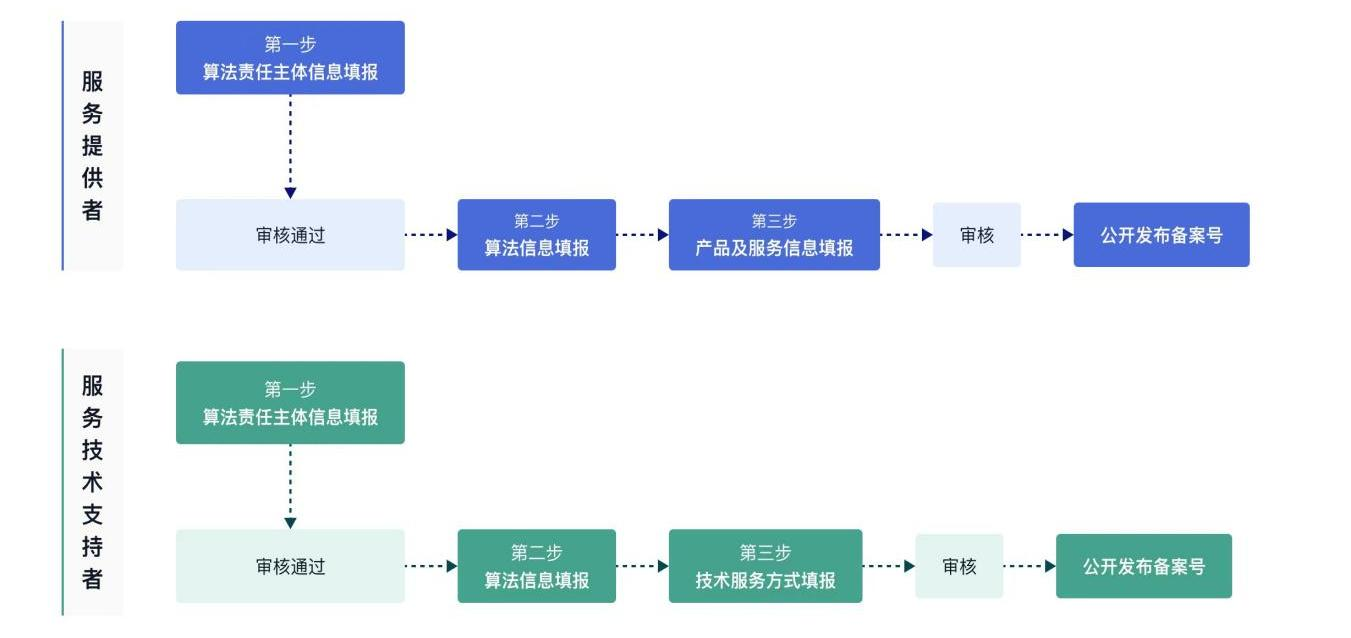
图 3 填报流程(示意图)
(一)主体信息填报 填报人员可点击主页的“主体信息”进行主体信息填报,按 照备案主体的实际情况如实填写主体的基本信息、证件信息、法定代表人信息、算法安全责任人信息等内容,并下载附件模板,严格按照模板要求填写并上传《算法备案承诺书》和《落实算法安全主体责任基本情况》附件。主体信息填报页面如图 4 所示。

图 4 主体信息填报页面(示意图)
(二)算法信息填报 填报人员可点击主页的“备案信息”进行算法信息填报。算 法信息填报包括两个步骤:一是填写算法基础属性信息;二是填写算法详细属性信息。
(1)填写算法基础属性信息 填报人员需选择“生成合成(深度合成)”算法类型,根据实际情况选择“服务提供者”或“服务技术支持者”填报角色。 填报人员需下载页面中的模板,按照模板内容填写并上传《算法安全自评估报告》《拟公示内容》等附件。算法基础属性信息填报页面如图 5 所示。

图 5 算法基础属性信息填报页面(示意图)
(2) 填写算法详细属性信息 填报人员可参考当前填报页面右方的说明文字,根据实际情况填写算法数据、算法模型、算法策略和算法风险与防范机制等信息。填报时,如需中途退出,可点击页面下方的“保存至草稿箱”,保存当前已填写的内容,便于后续继续填写。算法详细属性信息填报页面如图 6 所示。

图 6 算法详细属性信息填报页面(示意图)
(三)产品及功能信息或技术服务信息填报 在关联产品及功能信息或填报技术服务方式时,“服务提供者”角色的填报人员需关联产品及功能信息,“服务技术支持者” 角色的填报人员需填报技术服务方式。
(1)关联产品及功能信息 “服务提供者”角色的填报人员需根据实际情况勾选应用当前备案算法的产品及功能。需要注意的是,若勾选产品,则表示当前备案算法应用于该产品下所有功能;若勾选功能访问路径,则表示当前备案算法应用于该路径下所有功能;若勾选特定功能,则表示当前备案算法仅应用于被勾选的功能。勾选产品页面如图 7 所示。
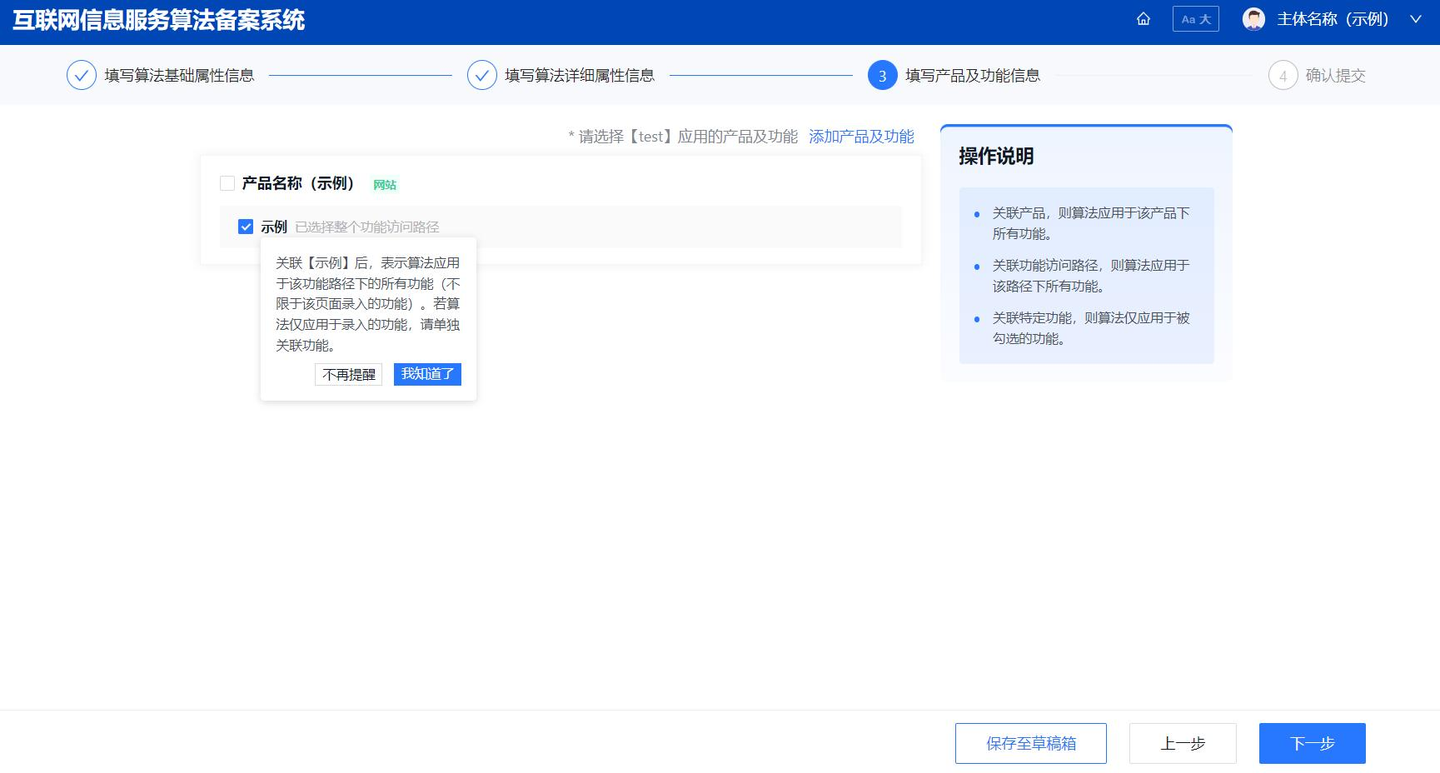
图 7 勾选产品页面(示意图)
若当前产品及功能信息不完善,即产品及功能不能覆盖当前备案算法的关联范围,填报人员可点击该界面下方的“保存至草 稿箱”按钮,返回主页并点击主页的“产品及功能信息”完善相应的产品及功能信息。产品及功能信息填报页面如图 8 所示。
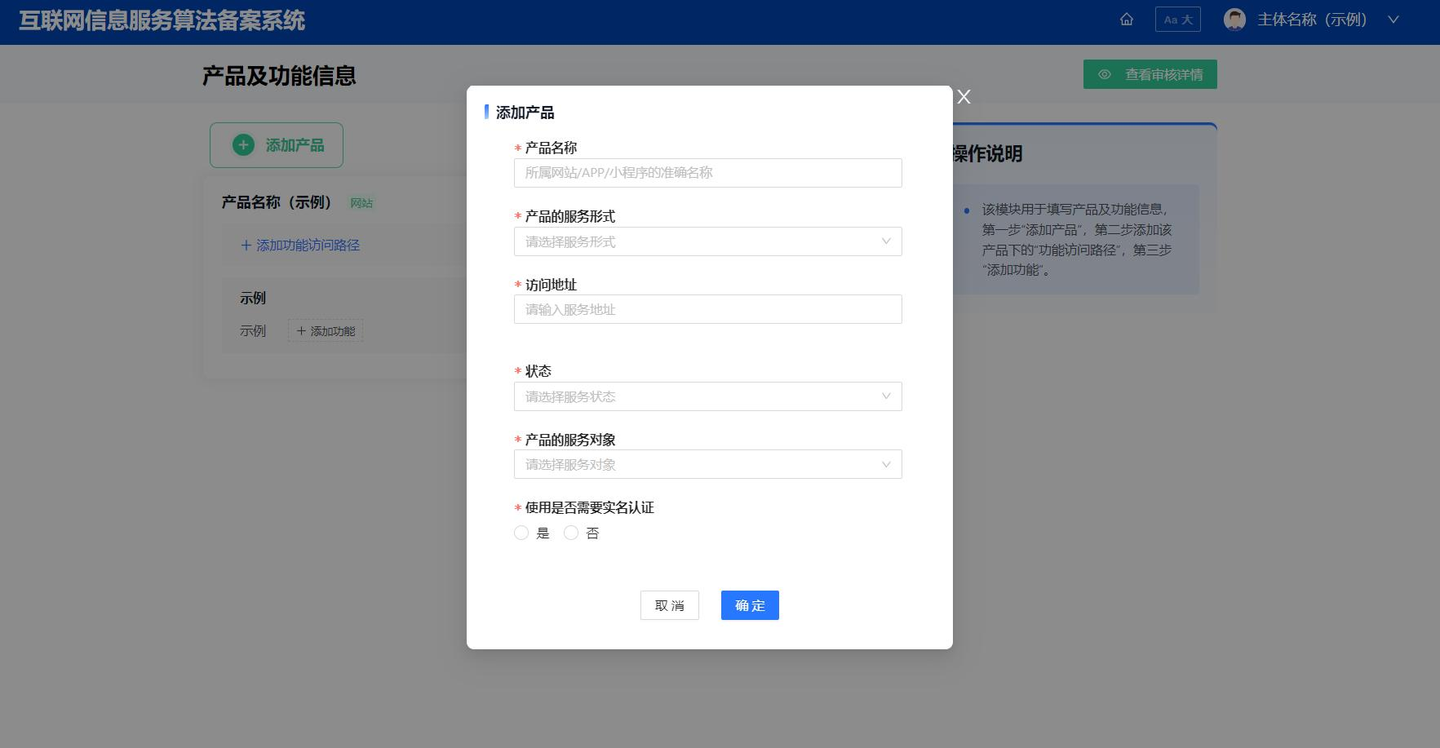
图 8 产品及功能信息填报页面(示意图)
待产品及功能信息完善后,算法备案填报人员可通过草稿箱返回至“备案信息”页面继续进行算法信息填报。其中,草稿箱的进入方式有两种:一是点击主页右上角用户昵称,在下拉菜单中选择“草稿箱”;二是点击主页“备案信息”按钮,从备案信息界面中进入“草稿箱”。
(2)填报技术服务方式 “服务技术支持者”角色的填报人员需根据实际情况填写当前备案算法的技术服务方式信息,包括技术服务名称、技术访问方式、技术服务对象、技术服务频度等。填报技术服务方式页面如图 9 所示。
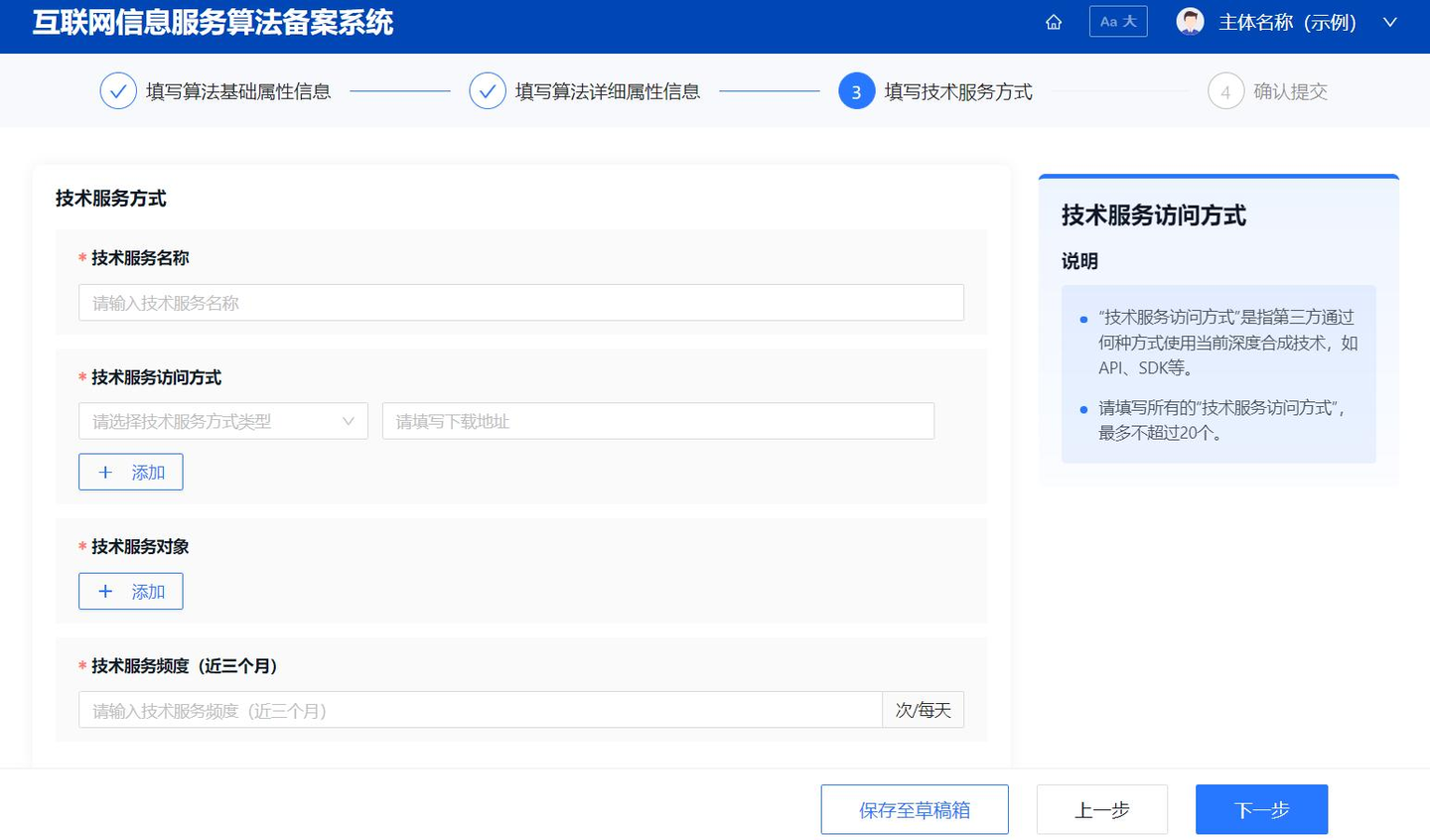
图 9 填报技术服务方式页面(示意图)
(四)提交备案信息 算法备案填报人员在确认填报信息无误后,应勾选页面下方的“我承诺上述填报信息真实有效”,并点击提交按钮,完成算法备案申报。确认信息页面如图 10 所示。
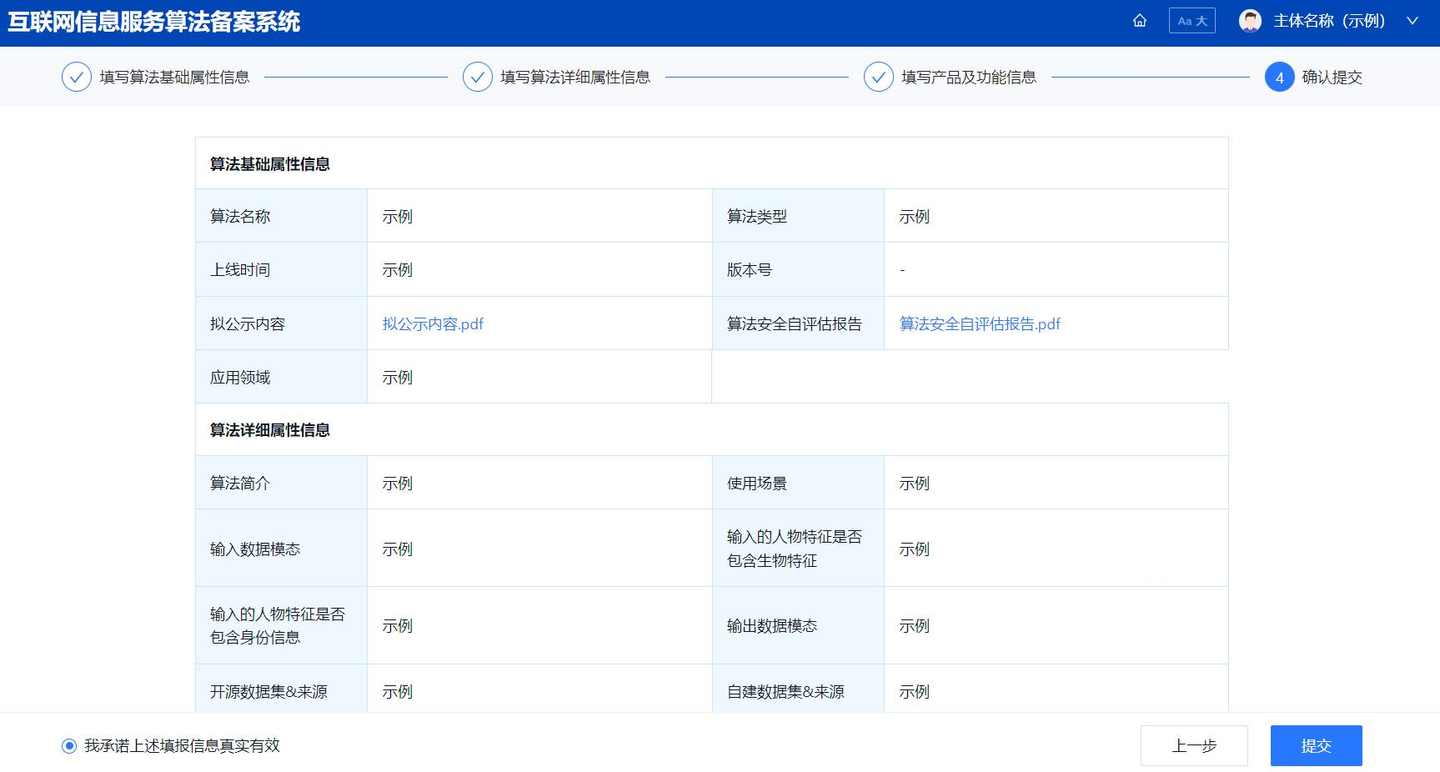
图 10 确认信息页面(示意图)
十三、大模型备案时间成本对比
| 自己写 | 提供备案服务 | |
| 时间成本 | 不确定。涉及学习时间和反复修改时间。学习难度大,需要从头学习并理解相关法规和要求,揣度得分要点。审核流程不够透明,需要反复试错,自己备案没有经验。自己写的话,备案通过平均6个月以上,驳回一次又要等一段时间,可能会影响产品上线。 | 快的话3个月拿到备案号 |
| 人力成本 | 需要同时具备算法研发、AI、安全、法务专业经验的人员。需要组织跨部门联合小组共同推进。 | 只需要少量算法技术配合 |
| 通过率 | 不确定,可能会影响产品上线 | 只要产品、数据合规基本都没问题 |
| 花费 | N个月*M个人*每月人力成本 | 远低于自己探索的成本 |
十四、备案建议
1、是否需要专业指导
在详细了解算法备案申报要求和规则基础上,可选择自己做,如果不了解,会造成申报材料反复出错被打回,增加试错的时间成本,严重延缓获得备案号的时间。
2、提升通过率
没有绝对的通过率高低之分,备案取决于模型和数据是否合规合法,只要申报材料能完整、如实描述,有完整的制度、策略、流程规避安全风险,理论上都是可以通过的。区别在于一次性快速通过,还是多次修改最终通过。
附录、过程性材料


这篇关于大模型备案全网最详细流程解读(附附件+重点解读)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







