本文主要是介绍代码与原理:混合精度训练详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

浮点数的表示
计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示,分别是:
- sign 表示正负,1表示正数,0表示负数
- exponent 用来确定数字的范围,这一部分有 k 个bit来表示二进制,所以 k 越大,浮点数能表示的范围就越大
- fraction 部分用来确定精度,也是位数越多,能表示的精度就越高
比如:
- BF16 一共 16bit,sign 占 1 bit,exponent 占8 bit,fraction占7bit
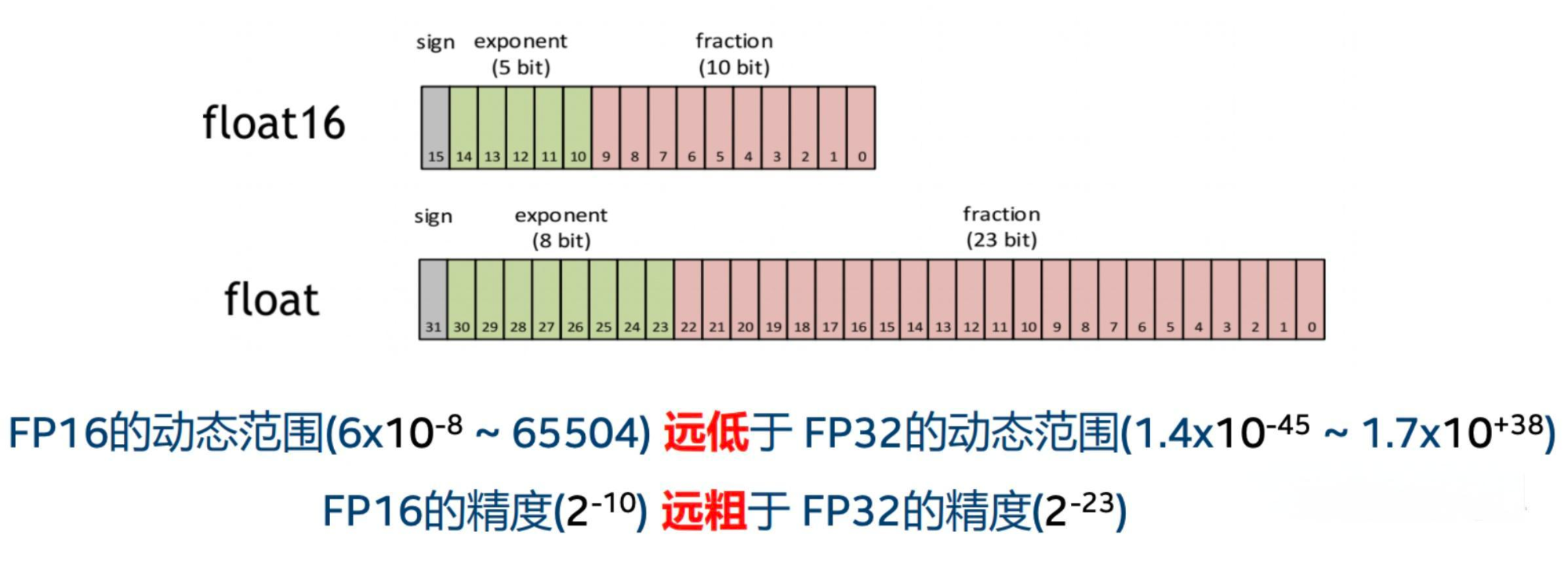
- FP16 一共16bit,sign 占 1 bit,exponent 占5bit, fraction占10bit
BF16能表示的数字范围更大,但是表示的精度更低。FP16 表示的数字范围更小,但是表示的精度更高深度学习中长期使用的标准格式是FP32,因为它能平衡数值范围和精度,同时也有较好的硬件支持。
- FP32一共32bit,sign 占 1 bit,exponent 占8 bit,fraction占23 bit
FP16存在的问题
float16和float32相比内存占用更少**,**通用的模型 fp16 占用的内存只需原来的一半,就意味着训练的时候可以用更大的batchsize,且在多卡训练时数据通信量大幅减少等待时间,还能加快计算节省模型的训练时间。但在模型的训练过程中,训练的稳定性很重要,如果用 FP16会出现如下问题:
- 数据溢出(范围):在反向传播中,需要计算网络模型中权重的梯度(一阶导数),因此在加权后值会更小。由上图可知FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况,实际中更容易出现下溢情况
- 舍入误差(精度):是指当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入产生误差
混合精度训练原理
为了想让深度学习训练可以使用FP16的好处,又要避免精度溢出和舍入误差。于是可以通过FP16和FP32的混合精度训练(Mixed-Precision),混合精度训练过程中可以引入权重备份(Weight Backup)、损失放大(Loss Scaling)、精度累加(Precision Accumulated)三种相关的技术。
权重备份(Weight Backup)
权重备份主要用于解决舍入误差的问题。其主要思路是把神经网络训练过程中产生的激活activations、梯度 gradients、中间变量等数据,在训练中都利用FP16来存储,同时复制一份FP32的权重参数weights,用于训练时候的更新。
权重用FP32格式备份一次,那岂不是使得内存占用反而更高了呢?是的,额外拷贝一份权重的确增加了训练时候内存的占用。但是实际上,在训练过程中内存中分为动态内存和静态内容,其中动态内存是静态内存的3-4倍,主要是中间变量值和激活activations的值。而这里备份的权重增加的主要是静态内存。只要动态内存的值基本都是使用FP16来进行存储,则最终模型与整网使用FP32进行训练相比起来, 内存占用也基本能够减半。
损失缩放(Loss Scaling)
因为梯度值太小,使用FP16表示有时会造成数据下溢出的问题,导致模型不收敛。为了解决梯度过小数据下溢的问题,对前向计算出来的Loss值进行放大操作,也就是把FP32的参数乘以某一个因子系数后,把可能溢出的小数位数据往前移,平移到FP16能表示的数据范围内。根据链式求导法则,放大Loss后会作用在反向传播的每一层梯度,这样比在每一层梯度上进行放大更加高效。损失放大是需要结合混合精度实现的,其主要的主要思路是:
- Scale up阶段:网络模型前向计算后在反响传播前,将得到的损失变化值Loss增大2^K倍
- Scale down阶段:反向传播后,将权重梯度缩2^K倍,恢复FP32值进行存储
精度累加(Precision Accumulated)
在混合精度的模型训练过程中,使用FP16进行矩阵乘法运算,利用FP32来进行矩阵乘法中间的累加(accumulated),然后再将FP32的值转化为FP16进行存储。简单而言,就是利用FP16进行矩阵相乘,利用FP32来进行加法计算弥补丢失的精度。这样可以有效减少计算过程中的舍入误差,尽量减缓精度损失的问题。
混合精度训练代码
下面是一个使用PyTorch进行混合精度训练的例子:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.cuda.amp import autocast, GradScalerclass SimpleMLP(nn.Module):def __init__(self):super(SimpleMLP, self).__init__()self.fc1 = nn.Linear(10, 5)self.fc2 = nn.Linear(5, 2)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x
启用混合精度:
model = SimpleMLP().cuda()
model.train()
scaler = GradScaler()for epoch in range(num_epochs):for batch in data_loader:x, y = batchx, y = x.cuda(), y.cuda()with autocast():outputs = model(x)loss = criterion(outputs, y)# 反向传播和权重更新# 放大梯度scaler.scale(loss).backward() # 应用缩放后的梯度进行权重更新scaler.step(optimizer)# 更新缩放因子scaler.update()
在这个例子中,autocast()将模型的前向传播和损失计算转换为FP16格式。然而,反向传播仍然是在FP32精度下进行的,这是为了保持数值稳定性。
由于FP16的数值范围较小,可能会导致梯度下溢出,所以GradScaler()在反向传播之前将梯度的值放大,然后在权重更新之后将放大的梯度缩放回来,在计算梯度后,使用scaler.step(optimizer)来应用缩放后的梯度,从而避免了数值下溢的问题。
torch.save(model.state_dict(), 'model.pth')
model.load_state_dict(torch.load('model.pth'))
在混合精度训练中,虽然模型的权重在训练过程中可能会被转换为 FP16 格式以节省内存和加速计算,但在保存模型时,我们通常会将权重转换回 FP32 格式。这是因为 FP32 提供了更高的数值精度和更广泛的硬件支持(FP16需要有Tensor Core的GPU),这使得模型在不同环境中的兼容性和可靠性更好。
混合精度训练有很多有意思的地方,目前使用动态混合精度的方法来充分利用GPU,以达到计算和内存的高效运行比是一个较为前沿的研究方向。
这篇关于代码与原理:混合精度训练详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






