本文主要是介绍在NextChat中接入SiliconCloud API 体验不同的开源先进大语言模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NextChat介绍
One-Click to get a well-designed cross-platform ChatGPT web UI, with GPT3, GPT4 & Gemini Pro support.
一键免费部署你的跨平台私人 ChatGPT 应用, 支持 GPT3, GPT4 & Gemini Pro 模型。
主要功能
- 在 1 分钟内使用 Vercel 免费一键部署
- 提供体积极小(~5MB)的跨平台客户端(Linux/Windows/MacOS), 下载地址
- 完整的 Markdown 支持:LaTex 公式、Mermaid 流程图、代码高亮等等
- 精心设计的 UI,响应式设计,支持深色模式,支持 PWA
- 极快的首屏加载速度(~100kb),支持流式响应
- 隐私安全,所有数据保存在用户浏览器本地
- 预制角色功能(面具),方便地创建、分享和调试你的个性化对话
- 海量的内置 prompt 列表,来自中文和英文
- 自动压缩上下文聊天记录,在节省 Token 的同时支持超长对话
- 多国语言支持:English, 简体中文, 繁体中文, 日本語, Español, Italiano, Türkçe, Deutsch, Tiếng Việt, Русский, Čeština, 한국어, Indonesia
- 拥有自己的域名?好上加好,绑定后即可在任何地方无障碍快速访问

GitHub地址:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web
SiliconCloud介绍
SiliconCloud 基于优秀的开源基础模型,提供高性价比的 GenAI 服务。
不同于多数大模型云服务平台只提供自家大模型 API,SiliconCloud上架了包括 Qwen、DeepSeek、GLM、Yi、Mistral、LLaMA 3、SDXL、InstantID 在内的多种开源大语言模型及图片生成模型,用户可自由切换适合不同应用场景的模型。
更重要的是,SiliconCloud 提供开箱即用的大模型推理加速服务,为您的 GenAI 应用带来更高效的用户体验。
对开发者来说,通过 SiliconCloud 即可一键接入顶级开源大模型。拥有更好应用开发速度和体验的同时,显著降低应用开发的试错成本。
官网地址:https://siliconflow.cn/zh-cn/siliconcloud
在NextChat中接入SiliconCloud API
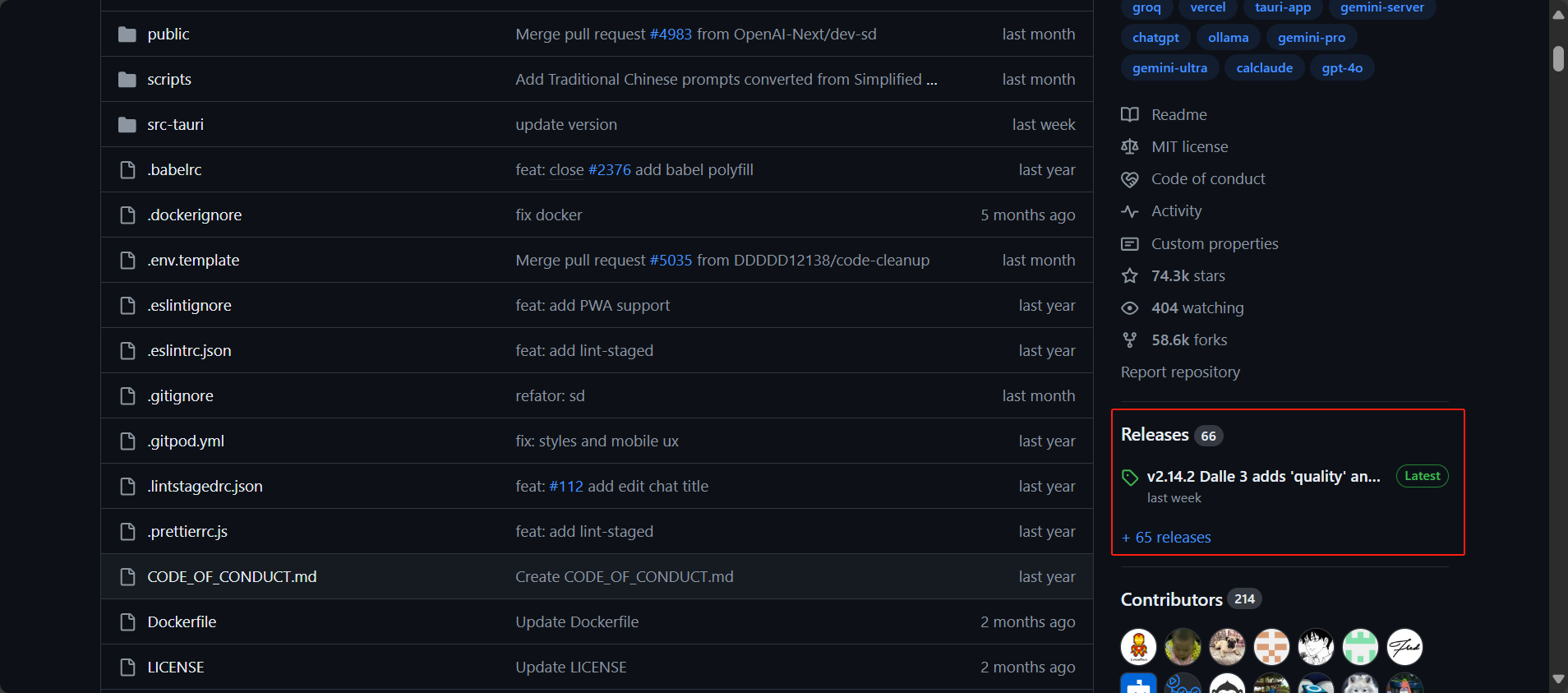
点击Releases:
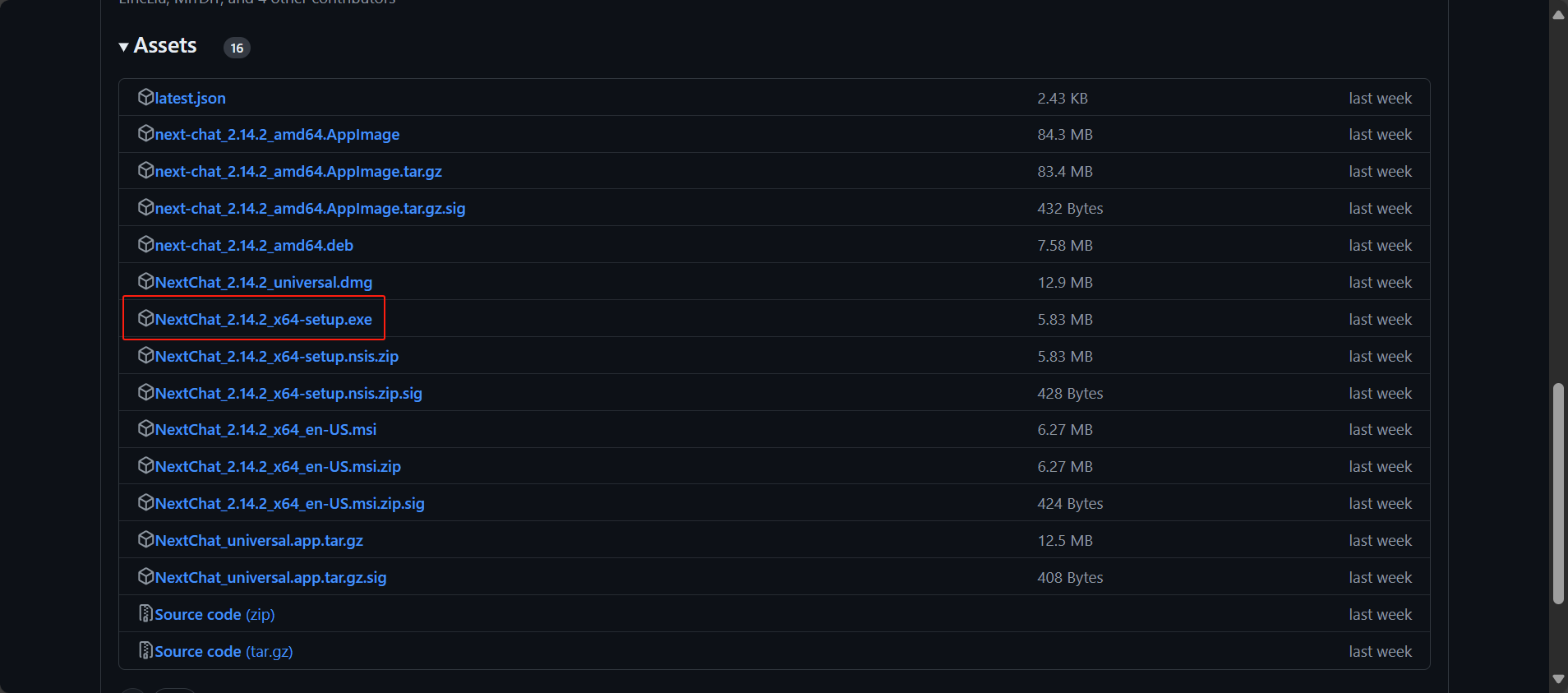
选择对应操作系统的安装包:
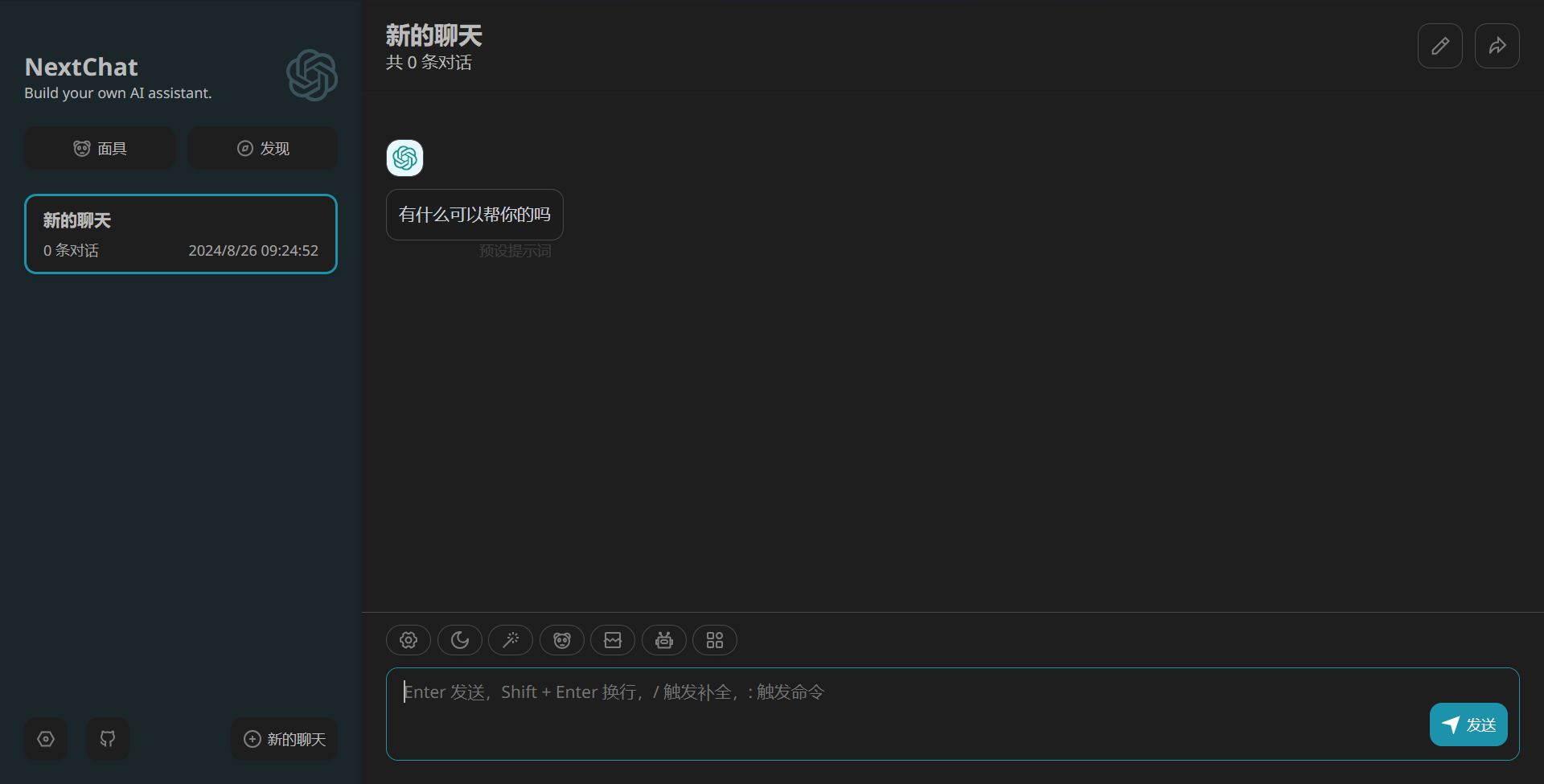
安装完成,打开界面如下所示:
点击设置,进行如下设置:
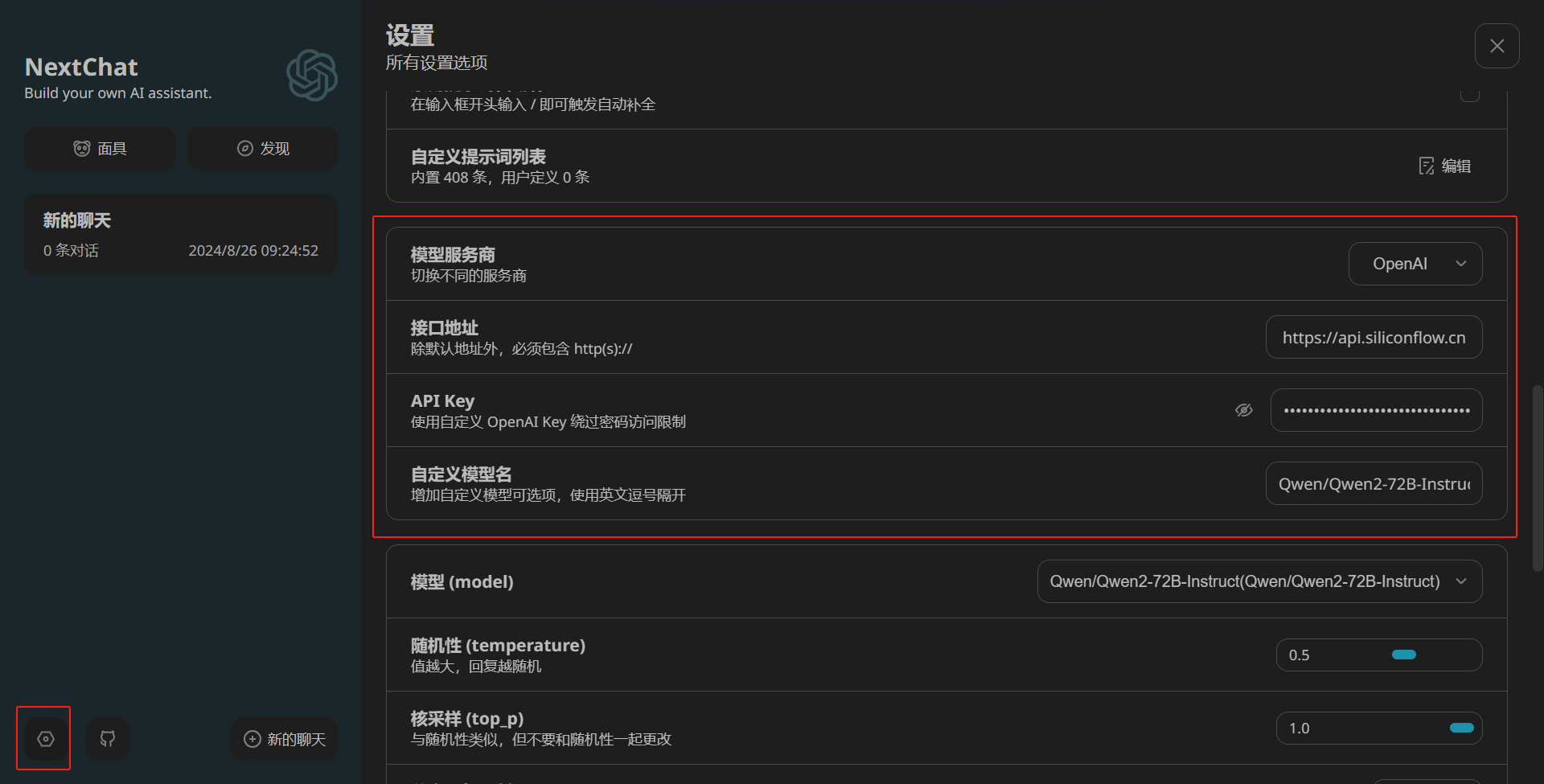
由于SiliconCloud提供的API服务已经兼容了OpenAI的格式,因此模型服务商可以不改,就把接口地址改成https://api.siliconflow.cn,填入API Key,填入模型名称即可。
模型名称可在SiliconCloud的文档中查看怎么写:
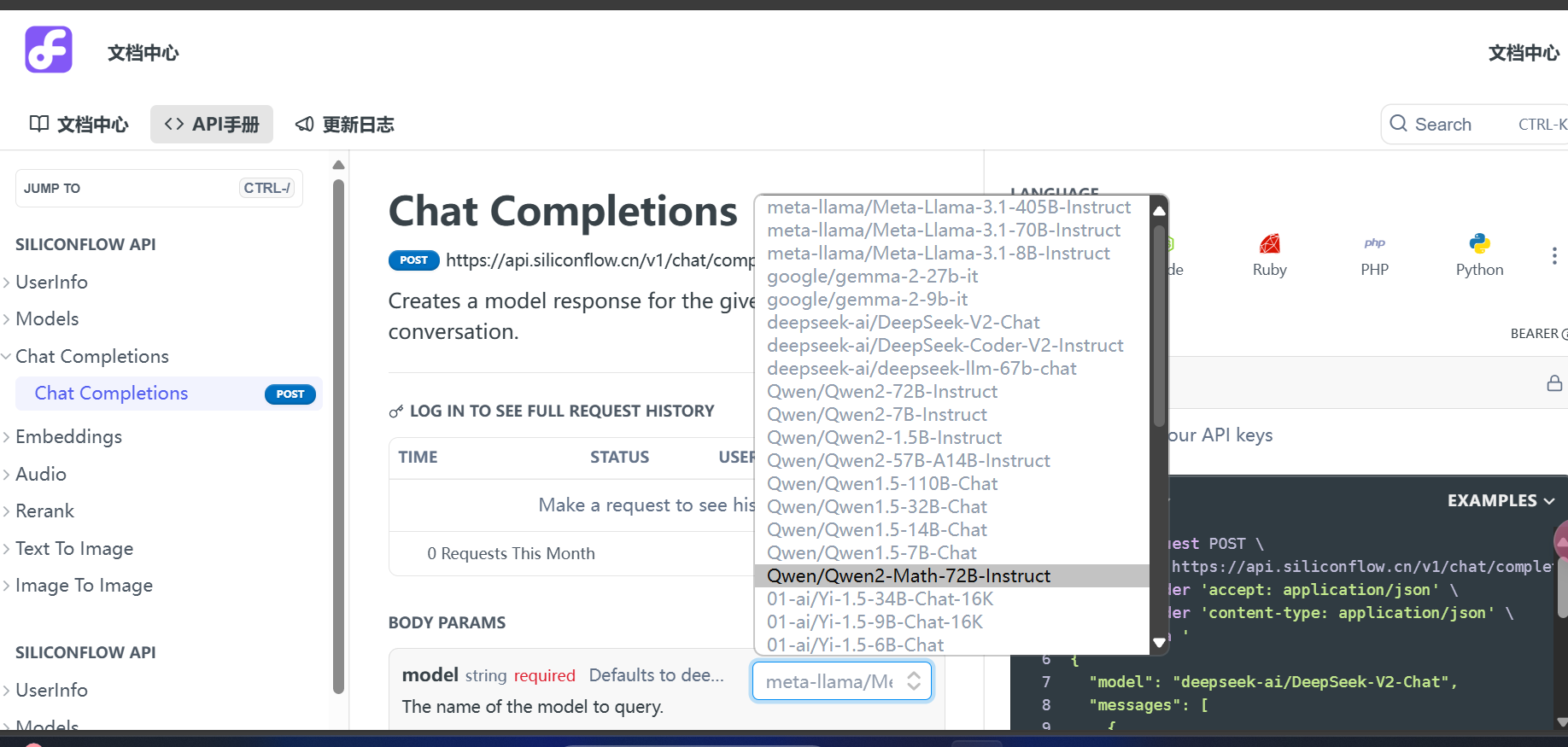
地址:https://docs.siliconflow.cn/reference/chat-completions-3
进行对话测试是否配置成功:
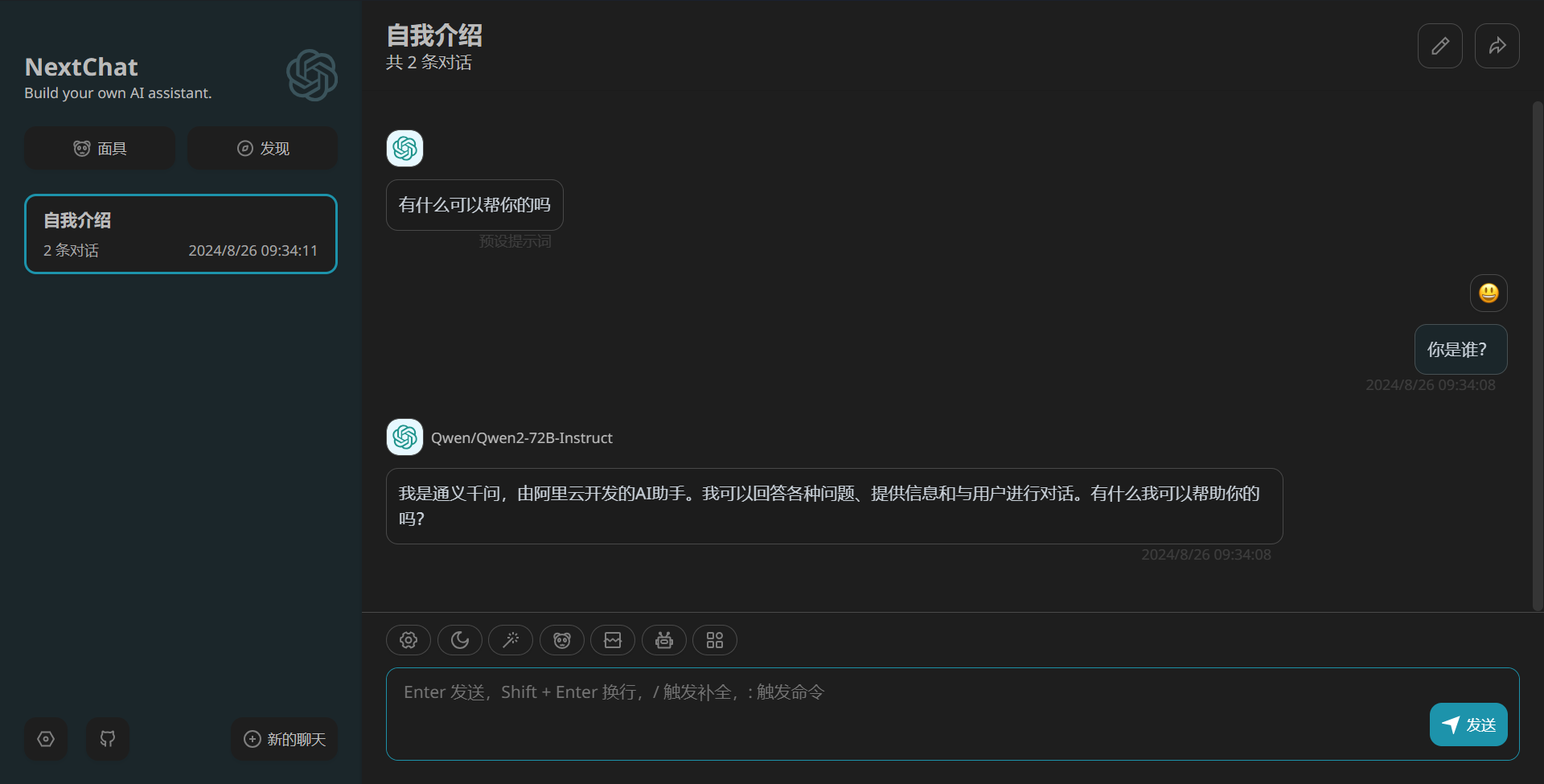
配置已经成功。
SiliconCloud的好处就是提供了不同的先进开源大语言模型,针对一个特定的任务,或许收费低的模型与收费高的模型都能很好的完成,这时候换成收费低的模型,这样就可以节省成本了。
接入SiliconCloud的API可以轻松地体验不同的先进开源大语言模型。
比如我想使用meta-llama/Meta-Llama-3.1-405B-Instruct这个先进的开源模型,我只需更改一下模型名:
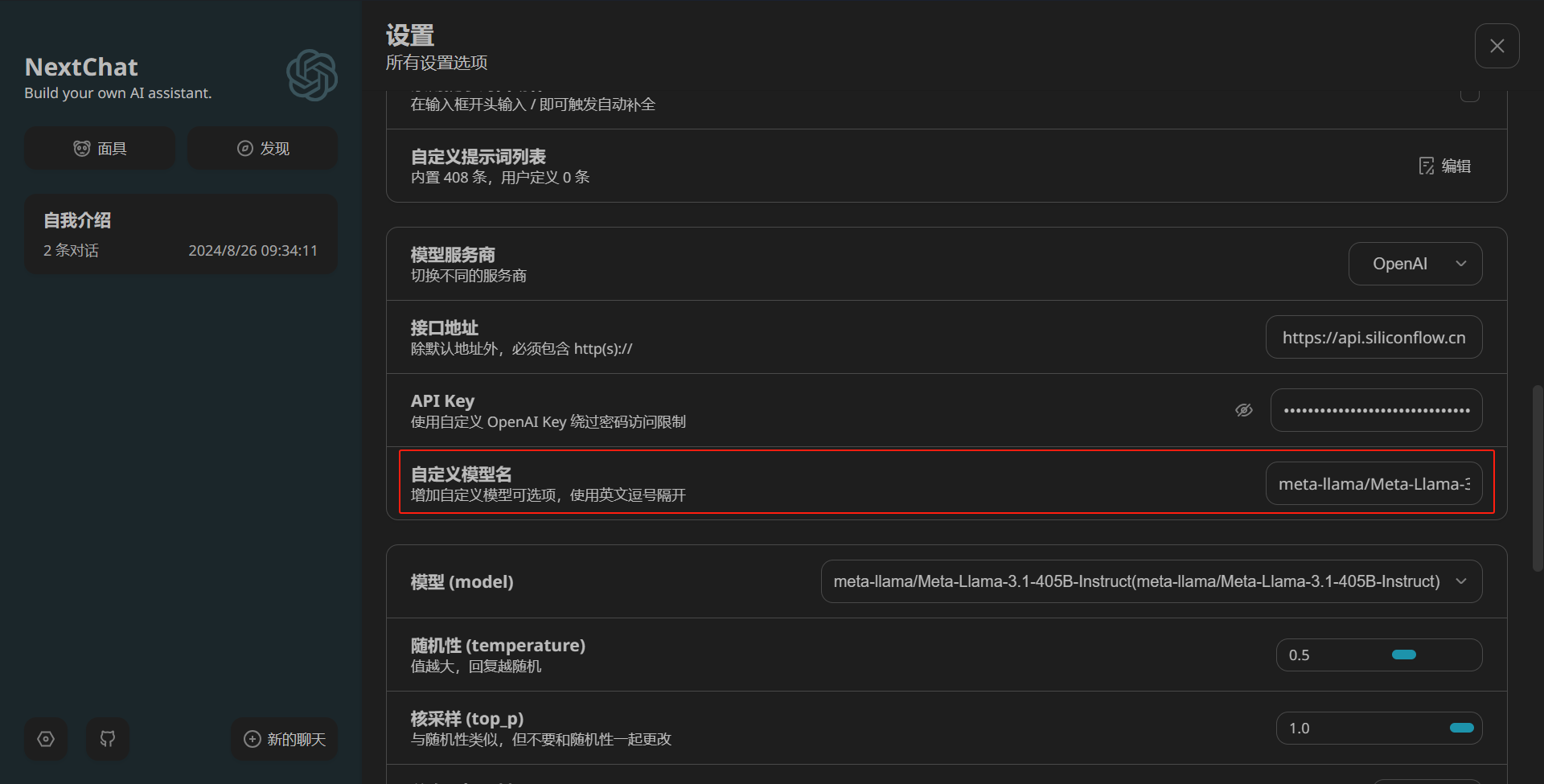
体验meta-llama/Meta-Llama-3.1-405B-Instruct的回答效果:
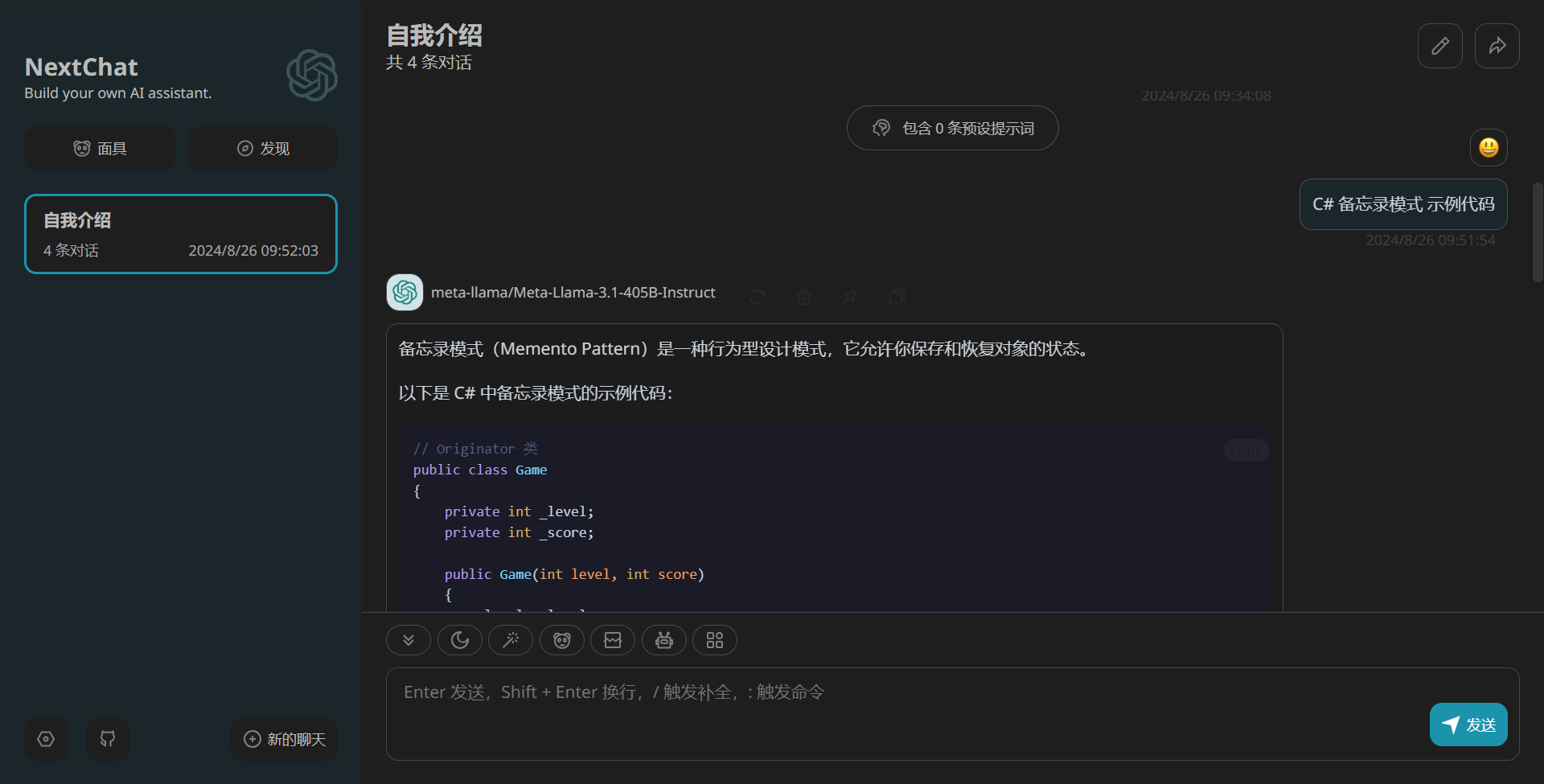
通过以上简单的几个步骤,就实现在NextChat中接入SiliconCloud API了,接入之后,就可以开始体验不同的开源先进大语言模型的回答效果了。
这篇关于在NextChat中接入SiliconCloud API 体验不同的开源先进大语言模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








