本文主要是介绍Python进阶(十一)】—— Pandas和Seaborn可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
- 1 Pandas和Seaborn可视化
- 2 Pandas可视化
- 3 Seaborn可视化
- 3.1 折线图
- 3.2 核密度图
- 3.3 散点图矩阵
- 3.4 联合分布图
- 3.5 直方图
【Python进阶(十一)】—— Pandas和Seaborn可视化,建议收藏!
该篇文章主要讲解了Python的Pandas和Seaborn可视化,通过实例演示对Pandas和Seaborn绘图方法进行熟悉,演示了常见绘图图形:折线图、核密度图等,同时部分图形进行美化。
1 Pandas和Seaborn可视化
上一节我们演示了Matplotlib基础可视化,这一节,我们将进一步探索Python中另外两个强大的可视化工具:Pandas和Seaborn,它们各自在数据处理和美化图表方面有着独特的优势。
Pandas绘图的优势:
- 集成性:Pandas的绘图功能紧密集成在其DataFrame和Series对象上,使得数据分析和可视化可以无缝衔接。用户可以直接在数据处理后,利用Pandas的绘图函数快速生成图表,无需将数据转换到其他可视化库中。
- 便捷性:Pandas提供了多种快速生成图表的函数,如
.plot(),.hist(),.boxplot()等,这些函数默认参数就能满足大部分基础需求,同时也支持高度自定义,以满足复杂的数据可视化需求。 - 灵活性:Pandas的绘图功能基于matplotlib构建,因此用户可以轻松地将matplotlib的样式和功能应用到Pandas生成的图表上,实现图表的美化和功能的扩展。
- 数据驱动的绘图:Pandas的绘图功能是基于数据的,它会自动处理数据索引、标签等,使得绘图过程更加直观和方便。用户无需手动设置图表的x轴、y轴标签等,这些都会根据DataFrame或Series的索引和列名自动生成。
Seaborn绘图的优势:
- 统计绘图:Seaborn是一个基于matplotlib的高级绘图库,它提供了更多面向统计学的绘图功能,如分布图、关系图、时间序列图等。这些功能使得Seaborn特别适合用于数据分析和统计建模的可视化。
- 美化效果:Seaborn通过提供丰富的样式和颜色主题,以及自动调整图表的美学参数(如字体大小、颜色搭配等),使得生成的图表更加美观和具有吸引力。这有助于在报告和演示中更好地展示数据。
- 集成性:尽管Seaborn是基于matplotlib构建的,但它提供了更高级别的接口,使得用户可以用更少的代码实现更复杂的数据可视化。同时,Seaborn也支持与Pandas的DataFrame对象直接交互,进一步增强了其集成性和便捷性。
- 数据探索:Seaborn的绘图功能特别适合用于数据探索,它可以帮助用户快速发现数据中的模式和关系。通过生成各种统计图表,用户可以直观地了解数据的分布情况、相关性等,从而为后续的数据分析和建模提供有力支持。
综上所述,Pandas和Seaborn在绘图方面各有优势,Pandas更适合于快速生成基础图表和数据处理后的即时可视化,而Seaborn则更适合于统计绘图、数据探索和生成美观的图表。在实际应用中,用户可以根据具体需求选择适合的库进行可视化操作。
2 Pandas可视化
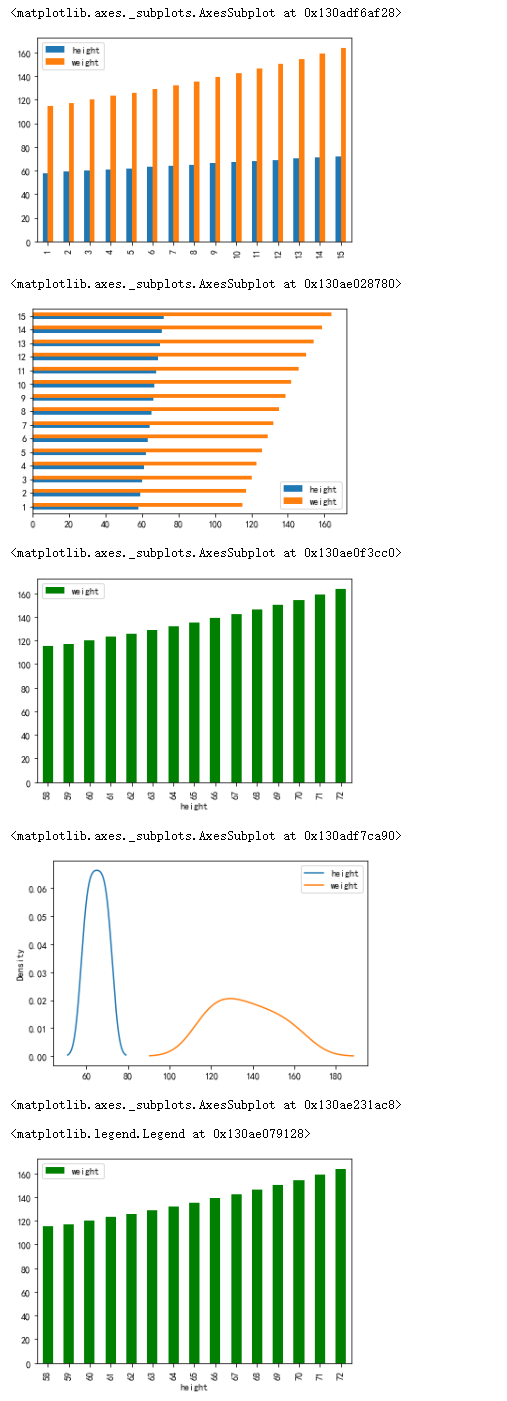
运行程序:
import pandas as pd
women = pd.read_csv('women.csv',index_col =0)
women.plot(kind="bar")#柱状图
plt.show()women.plot(kind="barh") #横向柱状图
plt.show() women.plot(kind="bar",x="height",y="weight",color="g") #横轴为身高,纵轴为体重,颜色为g
plt.show()women.plot(kind="kde")#核密度估计曲线
plt.show()women.plot(kind="bar",x="height",y="weight",color="g")
plt.legend(loc="best")#图例位置为“最优”
plt.show()
运行结果:
3 Seaborn可视化
3.1 折线图
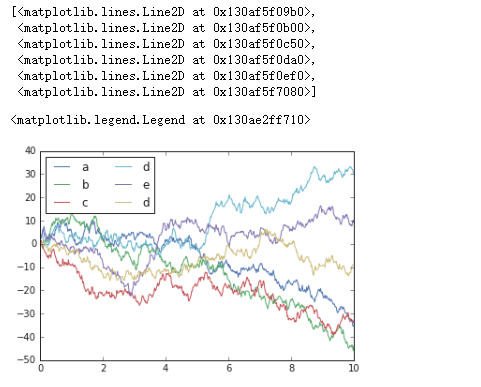
运行程序:
#导入包
import matplotlib.pyplot as plt
plt.style.use("classic")
%matplotlib inline#数据准备
import numpy as np
import pandas as pd
rng= np.random.RandomState(0)
x=np.linspace(0,10,500)
y=np.cumsum(rng.randn(500,6),0) #计算各行数组累加值
plt.plot(x,y)
plt.legend("abcded",ncol=2,loc="upper left")
运行结果:
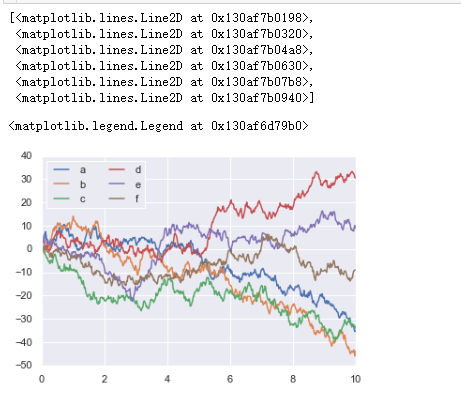
运行程序:
import seaborn as sns#seaborn绘图更加美观
sns.set()
plt.plot(x,y)
plt.legend("abcdef",ncol=2,loc="upper left")#设置图例参数;ncol:图例列数
运行结果:
3.2 核密度图
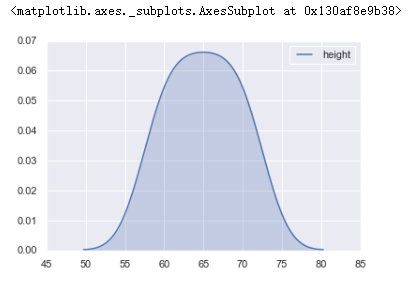
运行程序:
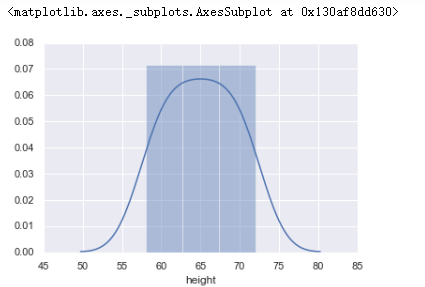
sns.kdeplot(women.height, shade=True) #核密度估计图
运行结果:
运行程序:
sns.distplot(women.height)#displot图:直方图+kdeplot图
运行结果:
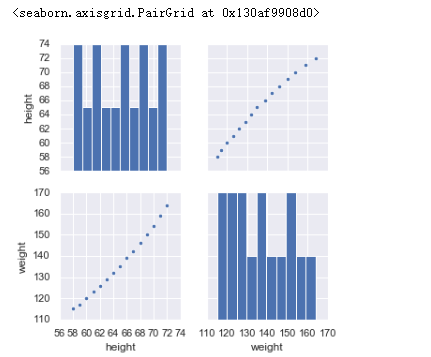
3.3 散点图矩阵
运行程序:
sns.pairplot(women) #绘制散点图矩阵
运行结果:
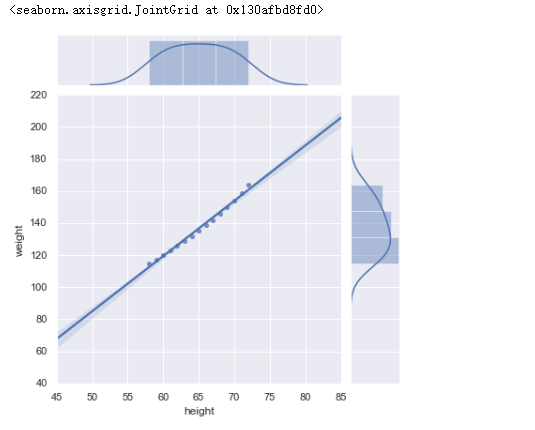
3.4 联合分布图
运行程序:
sns.jointplot(women.height,women.weight,kind="reg")#联合分布图
运行结果:
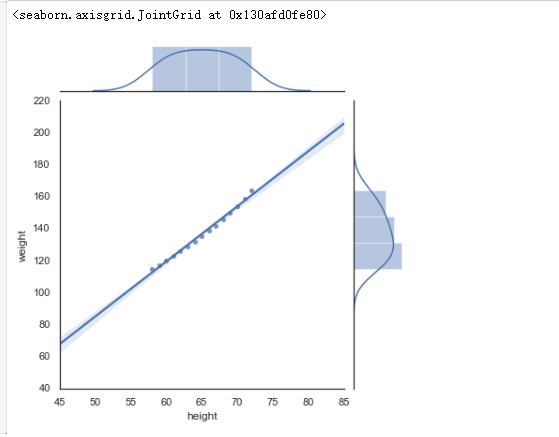
运行程序:
with sns.axes_style("white"):sns.jointplot(women.height,women.weight,kind="reg")#加入with语句,使设置更美观
运行结果:
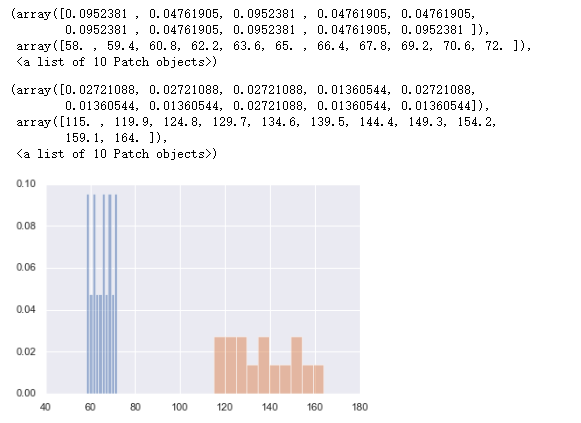
3.5 直方图
运行程序:
for x in ["height","weight"]:plt.hist(women[x],normed=True,alpha=0.5)#利用循环绘制直方图
运行结果:
这篇关于Python进阶(十一)】—— Pandas和Seaborn可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





