本文主要是介绍【LeetCode】Palindrome Partitioning III,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Palindrome Partitioning
问题来源:Palindrome Partitioning
该问题简单来说就是给定一个字符串,将字符串分成多个部分,满足每一部分都是回文串,请输出所有可能的情况。
该问题的难度比较大,很可能第一次遇到没有思路,这很正常。下面我们一点点分析,逐步理清思路。先不考虑所有的情况,针对一个符合条件的划分,每一部分都是一个回文子串,而且各部分的长度不固定。也即每一部分都是原始字符串的一个子串,且满足回文条件。所有的划分都满足上述条件,所以这就启发我们首先判断原始字符串的任意子串是否为回文子串。判断一个字符串是否为回文串最简单的方法是对字符串进行遍历。得到回文子串的结果之后我们该如何利用去获得所有可能的划分呢?此时,该问题就变为一个典型的深搜问题,问题的解空间就是所有可能划分的划分树,我们只需要遍历所有的分支直到叶节点,即为一个可能的划分。按照这个思路完成的代码如下:
- public class Solution {
- public ArrayList<ArrayList<String>> partition(String s) {
- int[][] dp=new int[s.length()][s.length()];
- ArrayList<ArrayList<String>> result=new ArrayList<ArrayList<String>>();
- ArrayList<String> r=new ArrayList<String>();
- for(int i=0;i<s.length();i++)
- {
- for(int j=i;j<s.length();j++)
- {
- int k=0;
- for(;k<(j-i+1)/2;k++)
- {
- if(s.charAt(i+k)!=s.charAt(j-k)) break;
- }
- if(k==(j-i+1)/2)
- {
- dp[i][j]=1;
- }
- }
- }
- dfs(0,s,dp,r,result);
- return result;
- }
- void dfs(int i,String s,int[][] dp,ArrayList<String> r,ArrayList<ArrayList<String>> result)
- {
- if(i==s.length())
- {
- ArrayList<String> t=new ArrayList<String>(r);
- Collections.reverse(t);
- result.add(t);
- return;
- }
- for(int j=i;j<s.length();j++)
- {
- if(dp[i][j]==1)
- {
- r.add(0,s.substring(i,j+1));
- dfs(j+1,s,dp,r,result);
- r.remove(0);
- }
- }
- }
- }
上述代码看似比较复杂,但其实就两个简单的部分:判断子串是否为回文串,然后深搜遍历所有的划分。判断子串是否为回文串采用了最朴素的循环遍历,在该题通过了测试,但是在第二题中将会超时,后面还会提到。深搜函数最重要的参数是第一个i,用来表示从字符串的i位置开始求划分,如果i已经超过了字符串的长度就说明完成了划分,保存一个可能的结果。如果i没有到字符串末尾,则判断从i开始到哪些位置是回文串,保存该回文串,然后从下一个位置继续深搜。如此就可以获得所有的划分。
2 Palindrome Partitioning II
问题来源:Palindrome Partitioning II
该问题是问题I的变种,现在不求所有的划分,而只求分组个数最小的划分。
2.1 深搜
该问题一开始的思路肯定是直接照搬问题I的方法,采用DFS去求解。如果我们按照这个思路去实现,提交的时候会发现算法超时,即使进行了一系列的调优也不行。下面是采用DFS的最原始代码:
- void dfs(int i,int parts,int len,int[][] dp)
- {
- if(i==len)
- {
- if(parts<minParts)
- {
- minParts=parts;
- }
- return;
- }
- for(int j=i;j<len;j++)
- {
- if(dp[i][j]==1)
- {
- dfs(j+1,parts+1,len,dp);
- }
- }
- }
代码是一个典型的深搜,符合深搜的基本框架,但是当输入字符串是“ababababababababababababcbabababababababababababa”,算法超时。实际上这个字符串还是很短的,超时说明算法复杂度太高,或者可能需要对解空间进行剪枝,这就启发我首先试试剪枝是否有效。最容易想到的剪枝策略是:如果当前的分割的个数已经大于当前最优解,则我们停止对该路径的深搜,需要的修改是对深搜的判断条件进行修改,修改之后为:
- void dfs(int i,int parts,int len,int[][] dp)
- {
- if(i==len)
- {
- if(parts<minParts)
- {
- minParts=parts;
- }
- return;
- }
- for(int j=i;j<len;j++)
- {
- if(dp[i][j]==1&&parts<minParts)
- {
- dfs(j+1,parts+1,len,dp);
- }
- }
- }
但是这样还是超时,当字符串为:“fifgbeajcacehiicccfecbfhhgfiiecdcjjffbghdidbhbdbfbfjccgbbdcjheccfbhafehieabbdfeigbiaggchaeghaijfbjhi”时,算法超时。
我还是不死心,感觉肯定是深搜的思路不对,导致对算法的剪枝力度不够,通过修改应该是可以通过的。后来一想,问题要求最短的分割,我们肯定需要首先考虑最长的回文子串,而之前的遍历都是从最短的回文子串开始遍历,可能这个是导致剪枝能力差的原因。按照这个思路修改代码,只需要将遍历回文子串的顺序修改一下即可:
- void dfs(int i,int parts,int len,int[][] dp)
- {
- if(i==len)
- {
- if(parts<minParts)
- {
- minParts=parts;
- }
- return;
- }
- for(int j=len-1;j>=i;j--)
- {
- if(dp[i][j]==1&&parts<minParts)
- {
- dfs(j+1,parts+1,len,dp);
- }
- }
- }
代码与上面的不同是修改了for循环的遍历次序,先从最长的回文子串开始遍历。但是结果令人失望,还是超时!当字符串是:
重新思考算法,DFS超时一般的原因都是由于递归过程中的重复子问题导致重复计算,最典型的例子是斐波那契数列的计算,递归和非递归算法的运行效率完全是两个概念,貌似这个问题和斐波那契数列问题类似。
重新审视上面的DFS代码,我们会发现变量只有前两个,后两个都是常量,这样深搜的过程中可能就会存在重复子问题。对字符串“ababa”运行算法I,可以得到该字符串的所有可能回文子串划分为:
| a b a b a |
| a b aba |
| a bab a |
| aba b a |
| ababa |
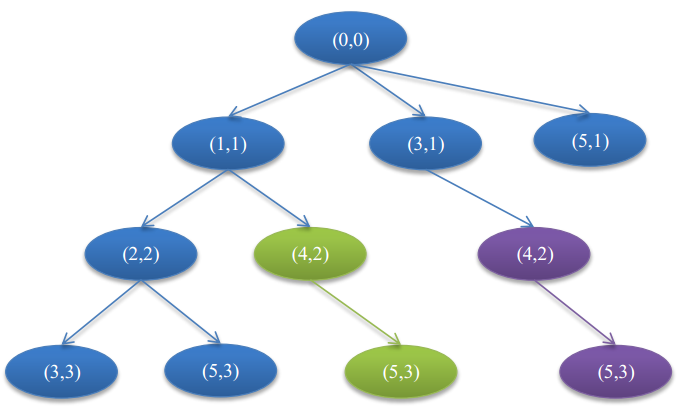
通过上面的调用树,我们可以知道上面的深搜确实存在重复计算的问题。但是为什么算法I就可以采用深搜完成呢?这是因为算法I要获得所有的划分,因而针对算法二是重复子问题的时候,它们在算法I中对应的是不同的划分,因而不会存在重复子问题。事实上,算法I的输入由于遍历整个解空间,给定的字符串都很短,最长的串也只是“eegiicgaeadbcfacfhifdbiehbgejcaeggcgbahfcajfhjjdgj”,深搜足以应对。
但是在算法II中,由于只计算一个最短划分,所以本来属于不同划分的结果在求划分数时其实是一样的,这就会导致重复子问题。搞明白超时的来源,代码修改就很容易了,解决重复子问题的方法主要有两种:备忘录或者DP。采用备忘录的方法时,代码还是采用深搜,但是通过保存之前已经计算过的值来避免重复计算,代码如下:- void dfs(int i,int parts,int len,int[][] dp,int[][] count)
- {
- if(count[i][parts]==1) return;
- if(i==len)
- {
- if(parts<minParts)
- {
- minParts=parts;
- }
- return;
- }
- count[i][parts]=1;
- for(int j=len-1;j>=i;j--)
- {
- if(dp[i][j]==1&&parts<minParts)
- {
- dfs(j+1,parts+1,len,dp,count);
- }
- }
- }
上述代码通过创建一个count数组用来表示之前的子问题是否已经计算过,如果计算过就不必再去深搜。但是很遗憾,上述代码居然还超时!!!当字符串为
“aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa”时,算法超时。不过让人欣慰的一点是,在上一次优化中超时的字符串在备忘录方法中没有超时,很快就可以得到结果。针对上面的长字符串,也可以较快得到结果。但是还超时,就说明一开始的判断任意子串是否为回文子串的复杂度太高。这个问题不能通过单纯地修改深搜为DP解决。
算法II判断字符串从i到j的子串是否为回文串时用了算法I中最朴素的蛮力方法,也即通过遍历的方法判断从i到j的子串是否为回文串,这种方法的复杂度为O(n3)。这是因为总共有n2个子串,每个子串判断是否为回文串的复杂度最大为O(n),因而整个判断的复杂度为O(n3),这个可以通过公式简单推导。由于深搜部分采用了备忘录方法,算法复杂度实际为O(n2),现在算法还超时只能说明判断子串是否为回文串的朴素方法太慢,需要修改。事实上,该部分确实有更优的算法,朴素方法太慢的原因是我们没有考虑相邻子串之间的相关性。假设现在我们已经知道S(i,j)是回文串,则我们可以在O(1)的时间内知道S(i-1,j+1)是否是回文串。这是因为字符串S(i-1,j+1)是在字符串S(i,j)的两头各添加一个字符构成的新串,如果现在满足S(i-1)等于S(j+1),则说明S(i-1,j+1)是回文串,否则就不是回文串。这表明我们可以利用子串之间的相关性来快速判断一个子串是否是回文串。该问题也是一个DP问题,算法复杂度只有为O(n2),相比朴素的算法,复杂度降低了一个数量级。定义P[i][j]表示字符串从i到j的子串是否为回文串,则P[i][j]满足公式:P[i][j] = (str[i] == str[j] && P[i+1][j-1])。
获得公式之后,DP算法面临的下一个问题是 计算顺序和初始化的问题。P[i][j]依赖于P[i+1][j-1],表示我们必须要从最后一行开始从左到右计算一个上对角矩阵。元素的初始化就是对最左侧的两条斜对角线进行初始化,如下图所示: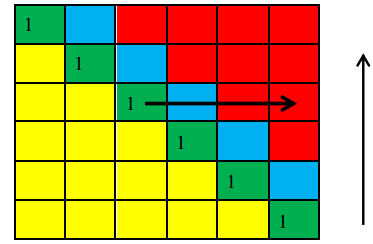
上图黄色部分是没有意义的部分,因为i到j的子串中i必须小于等于j。绿色部分表示单个字符的子串,肯定都是回文串。蓝色部分也是需要初始化的部分,因为它依赖于黄色没有意义的部分,该部分的初始化只需要判断两个字符是否相等。
综合上面的分析,我们得出第一个可以AC的代码:- public class Solution {
- int minParts;
- public int minCut(String s) {
- int[][] dp=new int[s.length()][s.length()];
- int[][] count=new int[s.length()+1][s.length()+1];
- minParts=Integer.MAX_VALUE;
- for(int i=s.length()-1;i>=0;i--)
- {
- for(int j=i;j<s.length();j++)
- {
- if(s.charAt(i)==s.charAt(j)&&(j-i<2||dp[i+1][j-1]==1))
- {
- dp[i][j]=1;
- }
- }
- }
- dfs(0,0,s.length(),dp,count);
- return minParts-1;
- }
- void dfs(int i,int parts,int len,int[][] dp,int[][] count)
- {
- if(count[i][parts]==1) return;
- if(i==len)
- {
- if(parts<minParts)
- {
- minParts=parts;
- }
- return;
- }
- count[i][parts]=1;
- for(int j=len-1;j>=i;j--)
- {
- if(dp[i][j]==1&&parts<minParts)
- {
- dfs(j+1,parts+1,len,dp,count);
- }
- }
- }
- }
2.2 DP
上述代码首先利用DP算法判断字符串的任意子串是否为回文串,然后利用备忘录形式的深搜去寻找最小划分。我们都知道,深搜的一大缺陷是递归的过程中可能会栈溢出,例如Surrounded Regions问题广搜可以通过,但是深搜就会溢出。此外,采用备忘录形式的深搜一般都可以通过DP来解决。上述深搜代码通过count矩阵来备忘,我们可以去除递归,直接通过DP循环的形式来计算count矩阵。但是直接利用count数组来DP求解将会导致算法复杂度为O(n3),这是因为总共有n2个元素,每个元素求解都需要O(n)的复杂度。
原问题的目的是求一个最小的划分,如果利用count矩阵则会求从位置i开始的每一个可能划分,实际上这是在做无用功。原因就在于count矩阵的第二维为划分个数,这一维对求最小值问题没有意义,我们可以去掉。所以我们重新定义一个新的一维count数组,用来表示从位置i开始到最后的最小划分个数。这时有公式: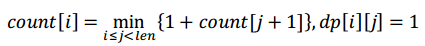
公式的含义是,从i开始的字符串的最小划分为:如果从位置i到位置j的子串是回文串,则从i开始的划分可以通过将i到j的子串看作划分的一部分,然后加上从j+1位置开始的子串最小划分,并选择可能情况中的最小值即为从i开始的最小划分。
完成通项公式的构造,下一步是考虑计算顺序和初始化。由于count[i]依赖于比i更大的count元素,所以i循环应该倒序。j的取值范围从i到len-1,正序和倒序均可。需要初始化的元素为最后一个count元素,其满足count[len]=0。按照这个思路我们可以很快写出另一个AC代码:- public class Solution {
- public int minCut(String s) {
- int[][] dp=new int[s.length()][s.length()];
- for(int i=s.length()-1;i>=0;i--)
- {
- for(int j=i;j<s.length();j++)
- {
- if(s.charAt(i)==s.charAt(j)&&(j-i<2||dp[i+1][j-1]==1))
- {
- dp[i][j]=1;
- }
- }
- }
- int[] count=new int[s.length()+1];
- for(int i=s.length()-1;i>=0;i--)
- {
- count[i]=Integer.MAX_VALUE;
- for(int j=i;j<s.length();j++)
- {
- if(dp[i][j]==1)
- {
- count[i]=Math.min(1+count[j+1],count[i]);
- }
- }
- }
- return count[0]-1;
- }
- }
如果我们仔细研究前后两次的for循环就会发现,这两个for循环结构完全一致,这就启发我们可以将代码放在同一个for循环中完成。第一个for循环求dp,第二个for循环利用dp求count。如果第一个for循环的if语句满足,则第二个for循环的if语句也满足,因此可以将其放在同一个for循环中。此时就可以得到第三个AC的代码:
- public class Solution {
- public int minCut(String s) {
- int[][] dp=new int[s.length()][s.length()];
- int[] count=new int[s.length()+1];
- for(int i=s.length()-1;i>=0;i--)
- {
- count[i]=Integer.MAX_VALUE;
- for(int j=i;j<s.length();j++)
- {
- if(s.charAt(i)==s.charAt(j)&&(j-i<2||dp[i+1][j-1]==1))
- {
- dp[i][j]=1;
- count[i]=Math.min(1+count[j+1],count[i]);
- }
- }
- }
- return count[0]-1;
- }
- }
这时我们就得到一个非常简洁,同时效率非常高的DP代码。可能一开始看到该代码不知道其含义,但是通过我们层层的分析,我们就会发现代码背后深刻的思想。该题非常好,值得我们好好学习。
原文来源于: http://blog.csdn.net/yutianzuijin/article/details/16850031这篇关于【LeetCode】Palindrome Partitioning III的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






