本文主要是介绍AgentQ,超越人类的人工智能代理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MultiOn 宣布推出一款新代理AgentQ,这是一款令人惊叹的产品,它整合了我最近一直在讨论的大部分内容:将 LLM 与搜索相结合。
但这个经纪人很特殊。
与其他代理不同的是,由于巧妙地使用了对齐技术,该代理可以从好的和坏的决策中学习,从而使其能够自我纠正(或用他们的话来说,“自我修复”),成为第一个在网络导航任务中超越人类平均能力的代理(至少据我所知),在现实预订场景中,Llama 3 70B 模型的准确率从 18.6% 提高到 95%。
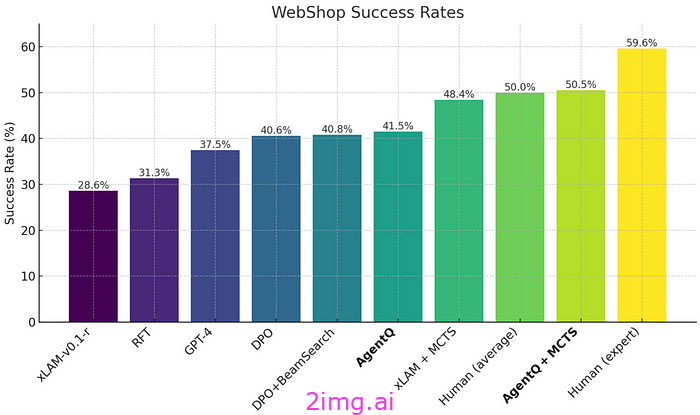
此外,他们还展示了一个令人着迷的训练流程,将 LLM、蒙特卡洛树搜索和与 DPO 的对齐训练相结合,创造出一种具有前所未见功能的独特 AI 产品。
但它是否能让我们更接近 AGI?
从 Move 37 到 Web 导航
当AlphaGo在一场五局三胜制的围棋比赛中击败世界冠军李世石时,这是人工智能历史上的一个决定性时刻。Google Deepmind通过蒙特卡洛树搜索 (MCTS) 算法训练模型实现了这一目标,该算法是我们今天所研究的代理的关键部分。
但是 MCTS 是什么?
MCTS 的工作原理
简而言之,MCTS 的工作原理是帮助模型在每个状态下做出最佳决策(在 AlphaGo 的例子中,该状态是当前棋盘状态)。
为此,它执行“蒙特卡罗模拟”或“推出”,其中算法通过模拟特定行动轨迹下的不同可能结果来“展望未来” 。
例如,在围棋中,AlphaGo(或更好的版本 AlphaZero)会模拟它选择的每一个可能动作将会发生哪些事件,直到达到最终状态(赢得游戏或输掉游戏)。
基于该模拟,它可以测量该部署的预期累积奖励(或沿着该路径为模型带来积极结果的可能性,即赢得游戏)。换句话说,该模型根据任何给定时间的最高预期累积奖励来选择其后续行动。
但 MCTS 之所以如此有效,是因为它还激励了探索。
换句话说,模型并不总是选择预期回报最高的决策,还会探索预期回报较小的行动,这些行动将来可能会通过揭示意想不到的新策略来获得更高的回报。
但是我们如何激励模型进行探索呢?
每当你面对一个神经网络时,你需要问自己以下问题:这个神经网络将学到什么?
LLM(或者任何神经网络)所学的内容很大程度上取决于任务和目标函数。
在这种情况下,虽然任务保持不变(下一个标记预测),但目标函数会计算模型的执行情况好坏,并将其作为反馈来指导模型应该学习或避免什么。
在这种情况下,使用的目标函数是MCTS UCB1,如下所示,其中:
- Q(ht,a)指的是基于当前环境和建议动作的 Q 函数。
此函数计算该操作的预期累积奖励。也就是说,如果模型选择该操作,那么沿着该操作轨迹它将获得的预期累积奖励是多少?
- 另一个项包括一个放大或最小化探索的常数 ( cexp ),乘以平方根项。
无需赘述,该术语通过为进入模型“访问量较少”状态的操作提供更高的分数来激励探索,因为 N(ht) 和 N(h+1) 均指特定节点(在本例中为网站上的特定页面)的访问频率。
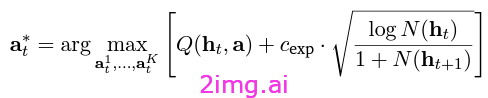
那么,代理通过这个目标函数学到了什么呢?它应该选择能够最大化良好结果可能性的行动,同时还要探索可能带来更好结果的未探索路径。
因此,一个动作可能具有非常高的预期回报但可能非常常见,而产生较少潜在回报的动作可能具有更大的探索激励。
这使得算法具有创造性和探索性,为了获得更显著的未来结果,选择看似更糟糕的行动,而不是每次都选择看似显而易见的选择,这可能会导致次优的训练。
探索带来了伟大的解放:创造力。
第一个创意模型
这种探索能力,加上它的推出模拟,使得 AlphaGo 完成了人工智能历史上最伟大的时刻之一:臭名昭著的“第 37 步”。
这个最初看似愚蠢的动作(低即时奖励)最终被证明对于赢得与当时最强人类的比赛至关重要。
如果您不知道围棋规则(像我一样),那么可以将其与国际象棋中的“第 37 步”进行比较,即 1851 年阿道夫·安德森 (Adolf Anderssen) 和基塞里茨基 (Kieseritzky) 之间的“不朽游戏”,当时安德森牺牲了后,这看似一个愚蠢的举动,结果几步之后就将对手将死了。
但是请稍等一下。如果 MCTS 这么好,为什么不是每个 LLM 都使用它呢?
MCTS 和一般的强化学习技术(通过衡量其行为的奖励来学习的模型)的问题在于,世界充满了稀疏的奖励。
通俗地说,当衡量机器人的行为是否良好并不明显时,很难实施 MCTS。如果不涉及机器人技术,衡量奖励本身已经成为一个人工智能领域(正如我所介绍的那样),衡量奖励有时是一个很大的主观性问题。
例如,考虑给定文本的两个摘要,这是法学硕士的普遍任务,我们如何选择哪一个最好?
这凸显了当今强化学习的最大问题:在像棋盘游戏这样有明确信号表明谁对谁错的受限环境之外,它几乎不起作用……
确实如此?因为 AgentQ 在 LLM 网络导航方面所做的正是如此。
自主网络导航
简而言之, AgentQ 融合了 LLM 和 MCTS (以及 DPO,稍后会详细介绍)的世界,以创建一个可以浏览网页并在其上执行操作的代理。
例如,在下图中,模型可以为用户预订餐桌,甚至可以在第一次搜索时犯错后进行纠正。
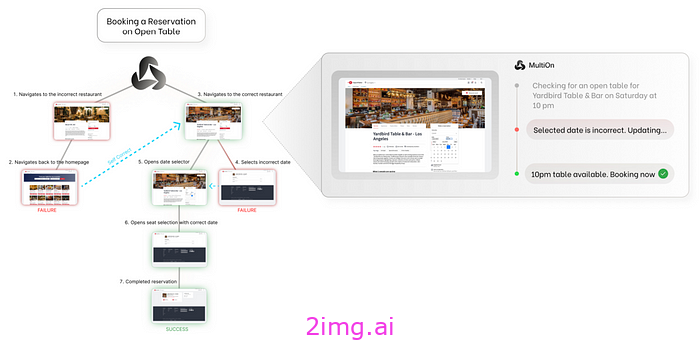
来源
从技术角度上讲,该模型执行以下操作:
- 通过访问过去的操作和当前网站状态(DOM)以及用户的请求,可以生成一组可能的操作(计划)。
- 然后,它会测量选择每个动作(我们之前提到的蒙特卡罗推出)所预期的累积奖励,平衡该轨迹是否已经被充分探索(它只探索尚未彻底探索的轨迹)。
- 然后,它执行所选的操作,
- 除了行动之外,它还解释了为什么它决定采取这样的行动,充当了一种“内心对话”,可以用来“推理”未来的预测。
但还有一个未解答的问题:在这种情况下,模型如何衡量回报?我们是不是处于难以衡量模型行为的情况之一?
是的,这让我们看到了 AgentQ 研究人员的最大贡献:“AI 评论家”。
将人工智能与推广相结合作为信号
为了处理网络导航中常见的开放式任务的不确定性,模型实际经历的过程如下:
- 当用户提出任务时,AgentQ 首先使用其 LLM 提出行动计划,
- 然后,它会用语言表达(即逐字写下)该计划背后的原因。换句话说,它会写下为什么要执行计划的每个步骤。
- 接下来,它会列出在给定步骤中可以执行的可能操作,并将它们发送给 AI 评论家(下图)。
- 然后,人工智能评论家会根据其认为最好的潜在结果重新排序操作(如下图所示)
- 然后,模型根据评论者的反馈和每次推出的预期奖励(我们之前讨论过的采取特定方向的预期奖励)的组合选择一个动作。
- 最后,模型用语言解释每个人选择该行动的原因,并在未来的行动中对其进行推理。
因此,原本高度复杂且难以衡量回报的问题可以通过额外的人工智能来解决,该人工智能可以相当准确地判断模型动作的结果,从而催生了 AgentQ。
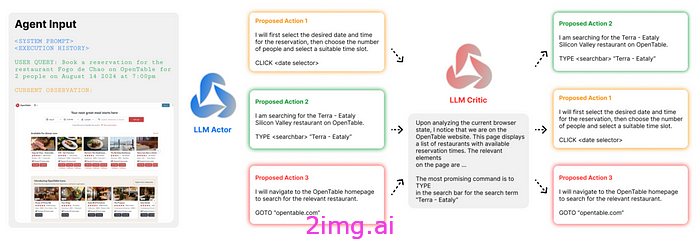
AI Critic 流程。来源
但是,我们如何考虑人工智能评论家的反馈呢?
如果我们回溯到之前看到的方程,Q 函数实际上分解为两个项,如下所示。
- 一是人工智能评论家的反馈,
- 另一个是模型在反向传播 rollout 之后获得的实际奖励(根据 rollout 是否以积极结果结束来计算每个状态的奖励)。
![]()
然后将该结果插入到我们之前看到的第一个方程中,以找出选择了哪个动作。
整个过程的一个重要方面是,与神经网络的标准优化程序不同,MCTS 是不可微的。这意味着,为了优化网络,我们不会像训练神经网络时通常那样计算梯度,而是更新两件事:
1. 模型计算轨迹预期奖励的能力如何(上式中的第一个 Q)
2. 节点上的访问频率。在此用例中,模型访问网站上特定页面的次数(我们在第一个等式中看到的 N(ht) 和 N(h+1) 项)。
由于我们无法通过梯度进行优化,因此该方法需要在线交互,这意味着,为了学习,代理必须主动与网站交互。这似乎无伤大雅,但不可微方程的优化难度要大得多(而且成本要高得多)。
然而,为了在不受在线训练限制的情况下进一步增强代理的能力,研究人员增加了一个可以进一步提升代理能力的步骤:
DPO。
改善决策
最后一步,研究人员使用不同的探索轨迹构建偏好数据集,以训练直接偏好优化(DPO)模型来改善决策(可区分的目标)。
但是 DPO 是什么?
DPO 是一种非常流行的对齐方法,可以增强模型的决策能力,在 LLM 训练中非常常用,作为人类反馈强化学习(RLHF) 的替代方案,以将模型对齐到特定行为(提高其决策能力)。
不同之处在于,DPO 优化了最大化奖励(确保最佳结果)的策略,而无需将奖励具体化,假设通过直接找到最优策略,我们就可以间接地优化奖励。
由于不必计算偏好一致的奖励,从而避免了奖励模型,DPO 比 RLHF 便宜得多,因此在开源工作中更为常见(尽管将两者结合起来也是已经做过的事情,例如 Meta 的 Llama 模型)。
考虑到 DPO,用于训练 AgentQ 的实际管道比您期望的代理训练更复杂,但却非常有效,很快就会成为标准。
- MCTS 的初始在线培训:
- 预先训练的 LLM 作为基础模型:为了避免从头开始训练基础模型,他们使用了预先训练的模型 Llama 3 70B。
- 用于探索的 MCTS: MCTS 帮助模型探索各种可能的动作和结果,特别是在动作序列对最终结果有显著影响的环境中(例如,网络导航或类似游戏的场景)。
- 在线交互:在此阶段,模型直接与环境交互(在线训练)。MCTS 算法有助于平衡探索(尝试新动作)和利用(使用已知的良好动作),以收集多样化的轨迹,同时提高模型有效导航的能力(选择更好的轨迹)
2.在离线设置中使用 DPO 进行进一步微调:
- 离线数据:经过初始的在线训练,模型已经积累了一套轨迹(成功和不成功的轨迹),这些轨迹是离线微调的基础。
- DPO 用于策略细化: DPO 通过比较轨迹对并根据偏好(例如,哪条轨迹导致更好的结果)优化策略来对收集到的离线数据进行操作。此步骤可细化模型的决策过程,而无需进一步的在线交互,而这既昂贵又难以优化,正如我们之前提到的。
尽管总体上很复杂,但 AgentQ 的令人印象深刻的结果表明它非常值得。但是这个代理是否能让我们更接近人们如此渴望的“神级 AGI”呢?
当然不是,但是它使我们更接近自主狭义代理,这本身就是一项了不起的成就。
这是一种进步……但进步幅度很小
我无法掩饰我对此的兴奋之情。
很长一段时间以来,我一直在我的新闻通讯中谈论 LLMs+search,将其视为新一代、超强大的 AI 模型,因此,我们终于看到了它们的必然出现,这真是太好了。然而,无论 AgentQ 多么令人印象深刻,它仍然有局限性。
尽管看到法学硕士在需要大量规划、推理和搜索的网络导航等复杂任务中取得超越人类的成果令人震惊,但我们正在讨论的是一个针对特定用例进行了优化的模型。
简而言之,这种方法与传统 RL 方法的唯一区别在于,这一次,我们可以利用 LLM 更好的“智能”将诸如网络导航之类的开放式任务转变为可优化的问题。
换句话说,这是一个净改进,但这并没有让我们接近 AGI,因为最重要的未解决问题仍然存在:
- 我们如何使用 RL 训练 LLM 来优化数百个任务,而不仅仅是一个任务?
然而,再次看到基础模型的局限性限制了 AgentQ 的功能,更好的 LLM 模型(例如 GPT-5 或 Grok-3)是否会成为我们正在等待的解锁器?
你怎么认为?
这篇关于AgentQ,超越人类的人工智能代理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[Day 73] 區塊鏈與人工智能的聯動應用:理論、技術與實踐](/front/images/it_default.gif)

