本文主要是介绍代码随想录算法训练营day30 | 贪心算法 | 452.用最少数量的箭引爆气球、435.无重叠区间、763.划分字母区间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 452.用最少数量的箭引爆气球
- 思路
- 435.无重叠区间
- 思路
- 763.划分字母区间
- 思路
- 问题的转化
- 总结
今天是贪心算法专题的第四天,今天的三道题目,都算是 重叠区间 问题,大家可以好好感受一下。 都属于那种看起来好复杂, 但一看贪心解法,惊呼:这么巧妙!
这种题还是属于那种,做过了也就会了,没做过就很难想出来
不过大家把如下三题做了之后, 重叠区间 基本上差不多了
452.用最少数量的箭引爆气球
题目链接:452. 用最少数量的箭引爆气球 - 力扣(LeetCode)
思路
每一个重叠区间共用一个箭(局部最优),才能做到用最少的箭引爆气球(全局最优),因此我们要让各个气球的区间尽可能重叠,如果气球重叠了,重叠气球中右边界的最小值 之前的区间一定需要一个弓箭,实际上,有多少个不重叠的区间,就需要多少个箭,因此选择右边界排序,统计不重叠区间的个数
以题目示例: [[10,16],[2,8],[1,6],[7,12]],排序后:
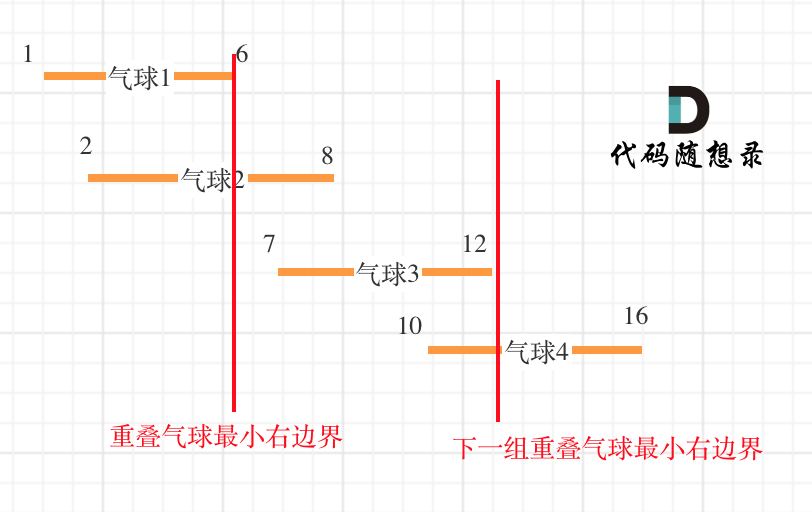
可以看到,第一组重叠区间,pos = 6,需要一个箭,气球3的 左边界 > pos,气球3不在第一组重叠区间内,要更新pos = 7,即第二组重叠区间的最小右边界,arrow++,需要一个箭
代码实现:
class Solution {
public:static bool cmp(const vector<int>& a, const vector<int>& b){return a[1] < b[1];}int findMinArrowShots(vector<vector<int>>& points) {if(points.empty()){return 0;}sort(points.begin(), points.end(), cmp);int arrow = 1;int pos = points[0][1]; // 初始pos为第一个区间的右边界for(int i=1; i<points.size(); ++i){if(pos >= points[i][0]) // 重叠区间,共用一支箭{continue;}pos = points[i][1]; // 将pos更新为下一个边界的右区间arrow++;}return arrow;}
};
435.无重叠区间
题目链接:435. 无重叠区间 - 力扣(LeetCode)
思路
这道题与 452.用最少数量的箭引爆气球 很类似,452.用最少数量的箭引爆气球 中寻找重叠区间的个数,这道题需要寻找不重叠区间的个数,思想是一致的——先将数组按照有边界排序,然后遍历数组,令end = 当前重叠区间的最小右边界,然后比较end 与 intervals[i] [0]的大小,由于要寻找不重叠区间的个数,我们要在end <= intervals[i] [0]时将count++,同时更新end = intervals[i] [1],即下一个重叠区间的最小右边界
代码如下:
class Solution {
public:// 按照区间右边界排序static bool cmp (const vector<int>& a, const vector<int>& b) {return a[1] < b[1];}int eraseOverlapIntervals(vector<vector<int>>& intervals) {if (intervals.size() == 0) return 0;sort(intervals.begin(), intervals.end(), cmp);int count = 1; // 记录非交叉区间的个数int end = intervals[0][1]; // 记录区间分割点for (int i = 1; i < intervals.size(); i++) {if (end <= intervals[i][0]) {end = intervals[i][1];count++;}}return intervals.size() - count;}
};
或者左边界排序,直接求要移除的区间个数:
class Solution {
public:static bool cmp (const vector<int>& a, const vector<int>& b) {return a[0] < b[0]; // 改为左边界排序}int eraseOverlapIntervals(vector<vector<int>>& intervals) {if (intervals.size() == 0) return 0;sort(intervals.begin(), intervals.end(), cmp);int count = 0; // 注意这里从0开始,因为是记录重叠区间for (int i = 1; i < intervals.size(); i++) {if (intervals[i][0] < intervals[i - 1][1]) { //重叠情况intervals[i][1] = min(intervals[i - 1][1], intervals[i][1]); // 这里用的是min,这是为了尽量减少后续的重叠,选择移除右边界较大的区间(即 end 更新为两个重叠区间中右边界较小的那个),并不是统计重叠区间的个数count++;}}return count;}
};
763.划分字母区间
题目链接:763. 划分字母区间 - 力扣(LeetCode)
思路
问题的转化
可以将这道题转化为重叠区间问题。我们首先统计每个字母出现的起始位置,获得appearIntervals,它记录了s中每个字符的[start, end]
题目要求每个字母至多在一个片段中出现,片段尽量多,因此每个片段对应一个重叠区间,片段的分割点就是重叠区间的右边界,我们使用左边界排序,记录每个重叠区间的start和end,重叠区间的长度就是end - start + 1
代码如下:
class Solution {
public:static bool cmp(const vector<int>& a, const vector<int>& b){return a[0] < b[0];}vector<vector<int>> CountIntervals(string s){vector<vector<int>> intervals(26, vector<int>(2,-1));vector<vector<int>> appearIntervals;// 首先统计每个字符出现的区间for(int i=0; i<s.size(); ++i){int index = s[i] - 'a';if(intervals[index][0] == -1){intervals[index][0] = i;}intervals[index][1] = i;}// 筛选出现过的字符区间for(int i=0; i<intervals.size(); ++i){if(intervals[i][1] != -1){appearIntervals.push_back(intervals[i]);}}return appearIntervals;}vector<int> partitionLabels(string s) {vector<vector<int>> appearIntervals = CountIntervals(s);// 寻找重叠区间,记录每个重叠区间的最大右边界,即为断点sort(appearIntervals.begin(), appearIntervals.end(), cmp);int end = appearIntervals[0][1]; // 记录每个重叠区间的终止位置int start = appearIntervals[0][0];vector<int> result;for(int i=1; i<appearIntervals.size(); ++i){if(end > appearIntervals[i][0]){end = max(end, appearIntervals[i][1]);}else{result.push_back(end - start + 1);end = appearIntervals[i][1]; start = appearIntervals[i][0];}}result.push_back(end - start + 1); // 最后一个重叠区间return result;}
};
总结
对于重叠区间问题:有两种排序方法:按照左边界(起始位置)排序 和 按照右边界(终止位置)排序
-
按照左边界排序,用于统计重叠区间的个数:
排序:
- 首先,代码将区间按照左边界进行排序,使得左边界较小的区间排在前面。
初始化:
count初始化为 0,表示当前还没有发现重叠的区间。end初始化为第一个区间的右边界,表示当前正在处理的区间的右边界。
遍历区间:
- 对于每个区间,判断它的左边界是否小于当前记录的
end。 - 重叠情况:如果当前区间的左边界小于
end,表示当前区间与之前的区间有重叠,count增加 1,表示发现了一个重叠区间,同时更新end为当前区间和前一个区间的右边界的最大值。 - 无重叠情况:如果当前区间的左边界大于等于
end,表示当前区间与之前的区间没有重叠,直接更新end为当前区间的右边界。
返回结果:
- 最终
count的值就是统计到的重叠区间的个数。
class Solution { public:static bool cmp (const vector<int>& a, const vector<int>& b) {return a[0] < b[0]; // 左边界排序}int findIntervals(vector<vector<int>>& intervals) {if (intervals.size() == 0) return 0;sort(intervals.begin(), intervals.end(), cmp);int count = 0; // 注意这里从0开始int end = intervals[0][1]; // 第一个重叠区间的右边界for (int i = 1; i < intervals.size(); i++) {//重叠情况if (end > intervals[i][0]) { count++;end = max(end, intervals[i][1]); // 更新当前重叠区间的终止位置}else{end = intervals[i][1];}}return count;} };
以[[1,2],[2,3],[3,4],[1,3]]为例,重叠区间的个数为2:
[1,2] 和 [1,3] 是重叠的,因为 [1,2] 和 [1,3] 之间有交集 [1,2]。
[2,3] 和 [1,3] 也是重叠的。
[3,4] 和其他区间没有重叠
-
按照右边界排序,用于统计不重叠区间的个数:
排序:
- 代码首先将区间按右边界进行排序,使得右边界较小的区间排在前面。
初始化:
count初始化为 1,表示第一个区间已经被选中,因此至少有一个非重叠区间。end初始化为第一个区间的右边界,表示当前选中区间的右边界。
遍历区间:
- 对于每个区间,判断当前区间是否与前一个选中的非重叠区间重叠。
- 无重叠情况:如果当前区间的左边界大于或等于
end,表示当前区间与之前的选中区间没有重叠,将end更新为当前区间的右边界,并将count加 1,表示找到了一个新的非重叠区间。 - 重叠情况:如果当前区间的左边界小于
end,表示当前区间与之前的区间有重叠,但不执行任何操作,继续寻找下一个区间。
class Solution { public:// 按照区间右边界排序static bool cmp (const vector<int>& a, const vector<int>& b) {return a[1] < b[1];}int findIntervals(vector<vector<int>>& intervals) {if (intervals.size() == 0) return 0;sort(intervals.begin(), intervals.end(), cmp);int count = 1; // 记录非交叉区间的个数int end = intervals[0][1]; // 记录区间分割点for (int i = 1; i < intervals.size(); i++) {// 不重叠情况if (end <= intervals[i][0]) {end = intervals[i][1];count++;}}return count;} };
这篇关于代码随想录算法训练营day30 | 贪心算法 | 452.用最少数量的箭引爆气球、435.无重叠区间、763.划分字母区间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





