本文主要是介绍Redis内存淘汰,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Redis内存淘汰
Redis可以存储多少数据
maxmemory配置,默认是注释掉的。
#maxmemory <bytes>
我们可以主动配置maxmemory,maxmemory支持各种单位,默认是字节
maxmemory 1024
maxmemory 1024KB
maxmemory 1024MB
maxmemory 1024GB
当Redis存储超过这个值,就会触发内存淘汰。
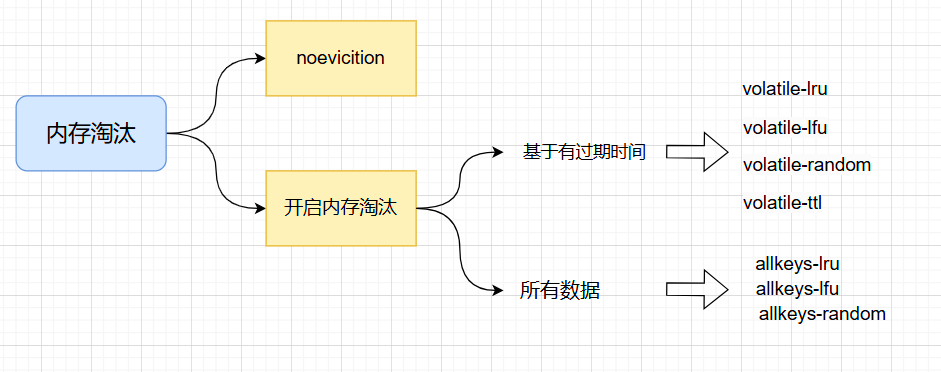
淘汰策略
有两个方向,一个是noevicition,默认就是这种策略,如果内存达到maxmemory,则写入操作失败,但不会淘汰原有数据;另一个是多种淘汰策略,主要是LRU、LFU、RANDOM、TTL。
LRU(Least recently used,最近最少使用):尝试回收最长时间未使用的。
LFU(Least Frequently Use,最近最少频率使用):尝试回收最不常用的键。
Random:随机回收键。
TTL:回收过期集合的键,并且优先回收存活时间较短(TTL)的键。
一般四种策略又分为volatile,设置了过期时间的Key;或是allkeys,全部的Key。
选择哪种淘汰算法
一般根据业务需求决定,缓存场景下一般使用的是LRU或LFU。
LRU
什么是LRU
最近最久未使用,即记录每个Key的最近访问时间,维护一个访问时间的数据
Redis的近似LRU
为什么不直接使用LRU
因为对所有数据用一个双向链表维护就是一个巨大的成本,Redis本身就是使用内存的,而内存是又少又珍贵的资源,所以Redis选择实现一个近似LRU。
近似的LRU
LRU模式中,RedisObject中lru字段存储的是被访问时的时间,每次该key被访问就会更新这个字段。
llru字段表示的时间戳越小,代表key空闲的时间越长,越应该被淘汰
为了保证高性能,Redis还缓存了Unix操作系统的时钟。
近似的LRU算法中,在内存不足时就会,进行全局随机采样,来筛选准备淘汰的元素。
步骤为:
1.随机采样n个key,n默认为5
2.根据时间戳淘汰最旧的key
3.判断内存是否不足,不足循环步骤1;反之,退出淘汰
之前说的全局随机采样,也是一个范围性的选择。也就是之前提过的,allkeys或者volatile
淘汰池的优化
近似LRU,最大的优点就是节约了内存。但是它的缺点是,淘汰的key是随机采样的结果,并不是真正的全局最久未访问。
在Redis3.0中,对近似LRU进行了优化:加入淘汰池。
优化后的LRU会维护一个大小为16的候选池,池中的数据按时间进行排序。
步骤:
1.第一次是随机挑选的16个,第一次以后就是随机挑选的一个
2.按访问时间进行排序,并且淘汰最久未访问的(一次只淘汰一个,剩下的都在池中)
3.判断是否继续
LRU优化后的对比
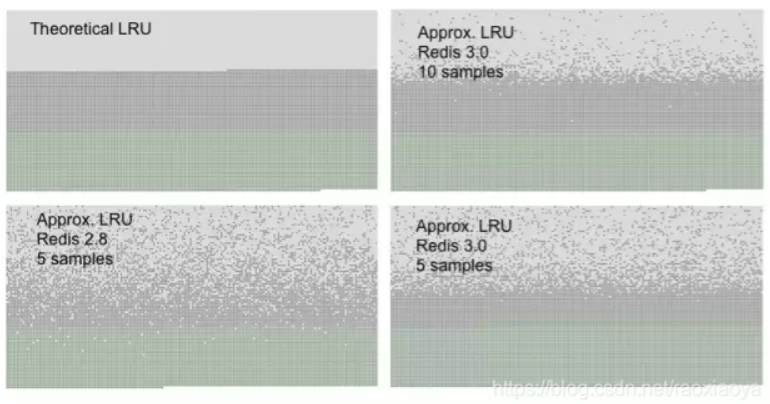
浅灰色是被淘汰的数据
灰色是没有被淘汰的老数据
绿色是新加入的数据
我们几乎可以认为Redis的近似LRU已经达到正常LRU的水准了。
LFU
什么是LFU
最不频繁淘汰算法,优先淘汰活跃最低,使用频率最低的。
为什么引入LFU
Redis在4.0版本后引入了LFU算法,为什么?
因为在部分场景下,只根据最近访问,不谈频率得不到我们希望的结果。
比如,有两个键key1、key2,之前9次一直在访问key1,第10次访问了key2,第10次后触发了内存淘汰,那你觉得该淘汰key1还是key2?
如果我们使用LRU,那就是淘汰key1;如果我们使用LFU,那就是淘汰key2。
但是这种场景下,一般我们会期望按频率来进行淘汰,于是就有了LFU
Redis的LFU
策略
我们之前提供Redis的RedisObject中有个字段是lru,其实LFU也是用这个字段来实现的。
LFU和LRU两种策略是一种互斥关系,是不会同时开启的。LFU将这个字段(lru字段24位)拆分为两部分,高16位存储ldt,也就是Last Decrement Time,低8位存储logc logistic Counter。

一个key是否活跃是根据这两个字段决定的。如果一个key,原来访问计数是255,但是一年没访问就会变成0(举例,并不一定是这样);如果一个key,频频被访问,它的访问计数会逐渐变大。
源码中,有部分代码证明了LFU和LRU是共用lru字段的。
#define LFU_INIT_VAL 5
robj *createObject(int type, void *ptr) {robj *o = zmalloc(sizeof(*o));//...//o的初始化//...if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {o->lru = (LFUGetTimeMinutex()<<8) | LFU_INIT_VAL;} else {o->lru = LRU_CLOCK();}return o'
}
代码中也说了,如果达到maxmemory,并且策略为LFU,前16位设置时间戳,后8位设置访问频率;否则设置lru当前时间戳。
访问频率衰减
redis.conf文件中,有一项配置为lfu_decay_time,默认值为1,表示每一分钟衰减一次。也就是上一次访问时间距离当前时间的分钟数。
lfu_decay_time 1
频率更新
访问计数的频率是一定概率增加的,次数不到5次,一定增加;如果大于5,小于255,一定概率增加;次数越大,越困难。
当然这也是有配置项的,lfu_log_factor被设置的越大,增加难度就越大,配置为0,每次会必然加1,上限为255(8位)。
void updateLFU(robj *val) {unsigned long counter = LFUDecrAndReturn(val);counter = LFULogIncr(counter);val->lru = (LFUGetTimeMinutes()<<8) | counter;
}
时间更新到高16位,次数更新到低8位。
这篇关于Redis内存淘汰的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




