本文主要是介绍全球陆地蒸散量数据集(1980-2022年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
定位分析多源集合陆地蒸散量数据集(1980-2022年)
数据介绍
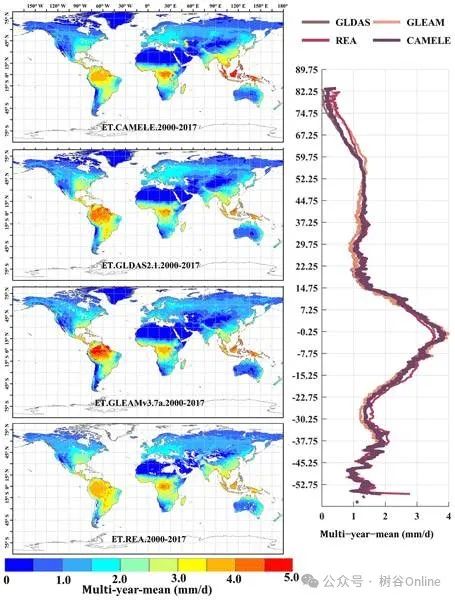
陆地蒸散发(ET)在地球的水碳循环中起着至关重要的作用,准确估算全球陆地蒸散发对于促进我们对陆地-大气相互作用的理解至关重要。尽管近几十年来开发了许多蒸散发产品,但由于使用了不同的强迫输入和不完善的模型参数,广泛使用的产品仍然存在固有的不确定性。此外,由于缺乏足够的全球原位观测数据,直接评估蒸散发产品并不现实,从而阻碍了这些产品的利用和同化。因此,建立可靠的全球基准数据集和探索蒸散发产品的评估方法至关重要。
本研究旨在通过以下方法应对这些挑战:(1)提出一种基于对位的方法,该方法考虑了多源数据合并时的非零误差交叉相关性;(2)采用这种合并方法生成分辨率为 0.1°(2000-2020 年)和 0.25°(1980-2022 年)的长期全球每日蒸散发产品,并纳入 ERA5L、FluxCom、PMLv2、GLDAS 和 GLEAM 的输入。由此产生的产品是定位分析多源集合陆地蒸散量数据(CAMELE)。
| 采集时间 | 1980/01/01 - 2022/12/31 |
|---|---|
| 采集地点 | 全球 |
| 数据量 | 37.9 GiB |
| 数据格式 | nc |
| 数据空间分辨率(/米) | 0.1度,0.25度 |
| 数据时间分辨率 | 年 |
| 坐标系 |
数据源描述:
ERA5-Land:https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-land?tab=overview
GLDAS:https://disc.gsfc.nasa.gov/datasets?keywords=GLDAS
Global Land Evaporation Amsterdam Model 3.7 (GLEAM-3.7):https://www.gleam.eu/
Penman–Monteith–Leuning version 2 global evaporation model (PMLv2):https://developers.google.com/earth-engine/datasets/catalog/CAS_IGSNRR_PML_V2_v017
FluxCom:http://fluxcom.org/
Global in situ observation: FluxNet
数据加工方法:
本研究对产物的融合包括三个步骤:
(1)采用配准法(IVD和EIVD)计算所选输入产物的随机误差方差,确定区域最优产品,并设置误差阈值;
(2)以最小均方误差(MSE)为目标,计算各网格上不同产品的权重;
(3)根据权重融合产品,得到长序列蒸散量产品。由于 IVD 和 EIVD 是通过结合工具变量回归和扩展定位系统开发的,因此还包括对 TC 和 EC 算法的描述。
数据质量描述:
CAMELE 在各种植被覆盖类型中表现出良好的性能,并与现场观测数据进行了验证。评估过程得出的皮尔逊相关系数(R)分别为 0.63 和 0.65。此外,比较结果表明,CAMELE 能够有效描述蒸散发的多年线性趋势、平均值和极端值。但是,它有高估季节性的倾向。总之,我们提出了一套可靠的蒸散发数据,有助于理解水循环的变化,并有可能作为各种应用的基准。
作者简介
数据贡献者:杨汉波
元数据作者:杨汉波
数据管理者:杨汉波
数据下载
数据分享:全球陆地蒸散量数据集(1980-2022年)
这篇关于全球陆地蒸散量数据集(1980-2022年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






