本文主要是介绍手动下载Sentinel-1卫星精密轨道数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
轨道信息对于InSAR(干涉合成孔径雷达)数据处理至关重要,因为它影响从初始图像配准到最终形变图像生成的整个过程。不准确的轨道信息会导致基线误差,这些误差会以残差条纹的形式出现在干涉图中。为了消除由轨道误差引起的系统性误差,使用高精度的卫星轨道数据进行校正是非常必要的。在使用Sentinel-1数据进行InSAR处理时,推荐在数据导入阶段就使用精密轨道文件。
Sentinel-1数据提供了两种类型的轨道数据:
-
POD Precise Orbit Ephemerides(POD精密定轨星历数据):
-
这是最精确的轨道数据类型。
-
数据发布通常在GNSS(全球导航卫星系统)数据下传后大约21天。
-
每天会生成一个文件,每个文件覆盖26小时的时间范围(包括当天的24小时以及前一天和后一天各一个小时)。
-
定位精度优于5厘米。
-
-
POD Restituted Orbit(POD回归轨道数据):
-
相较之下,这是一种较为精确的轨道数据类型。
-
文件在接收GNSS数据后的3小时内生成。
-
覆盖一个完整的卫星轨道周期,从升交点(Ascending Node)前593个OSV(Orbit State Vector)时间点开始。
-
定位精度优于10厘米。
-
在欧空局网站下载轨道参数,地址是Copernicus Browser
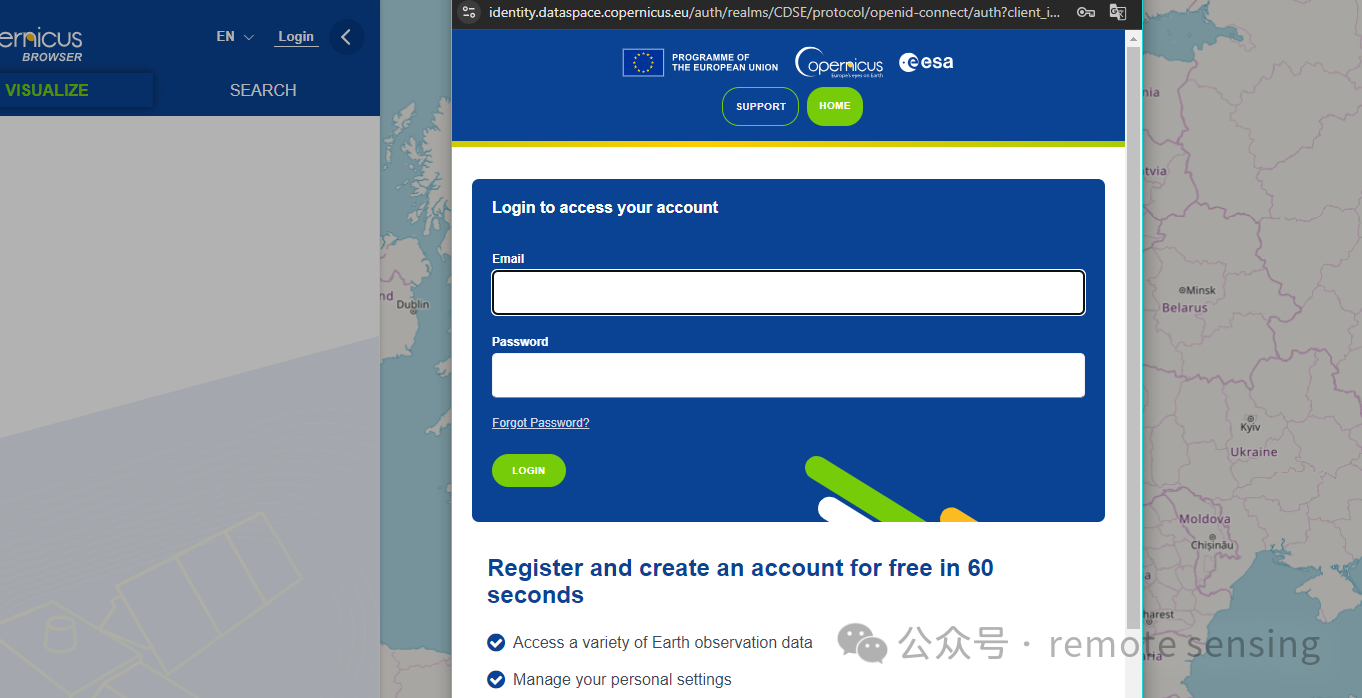
登录后,在左上方点击SEARCH按钮
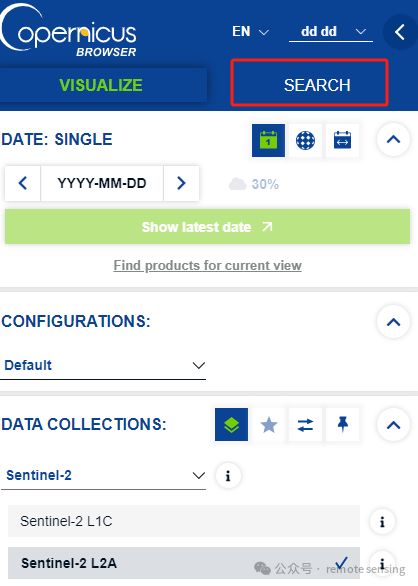
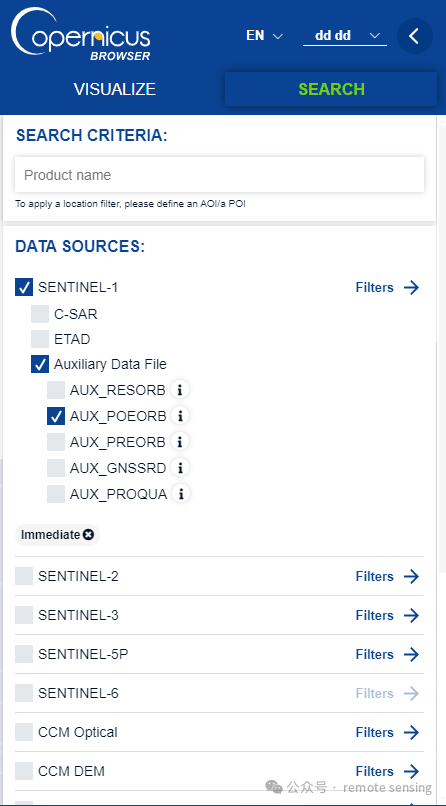
勾选SENTINEL-1
勾选Auxiliary Data File
勾选AUX_POEORB
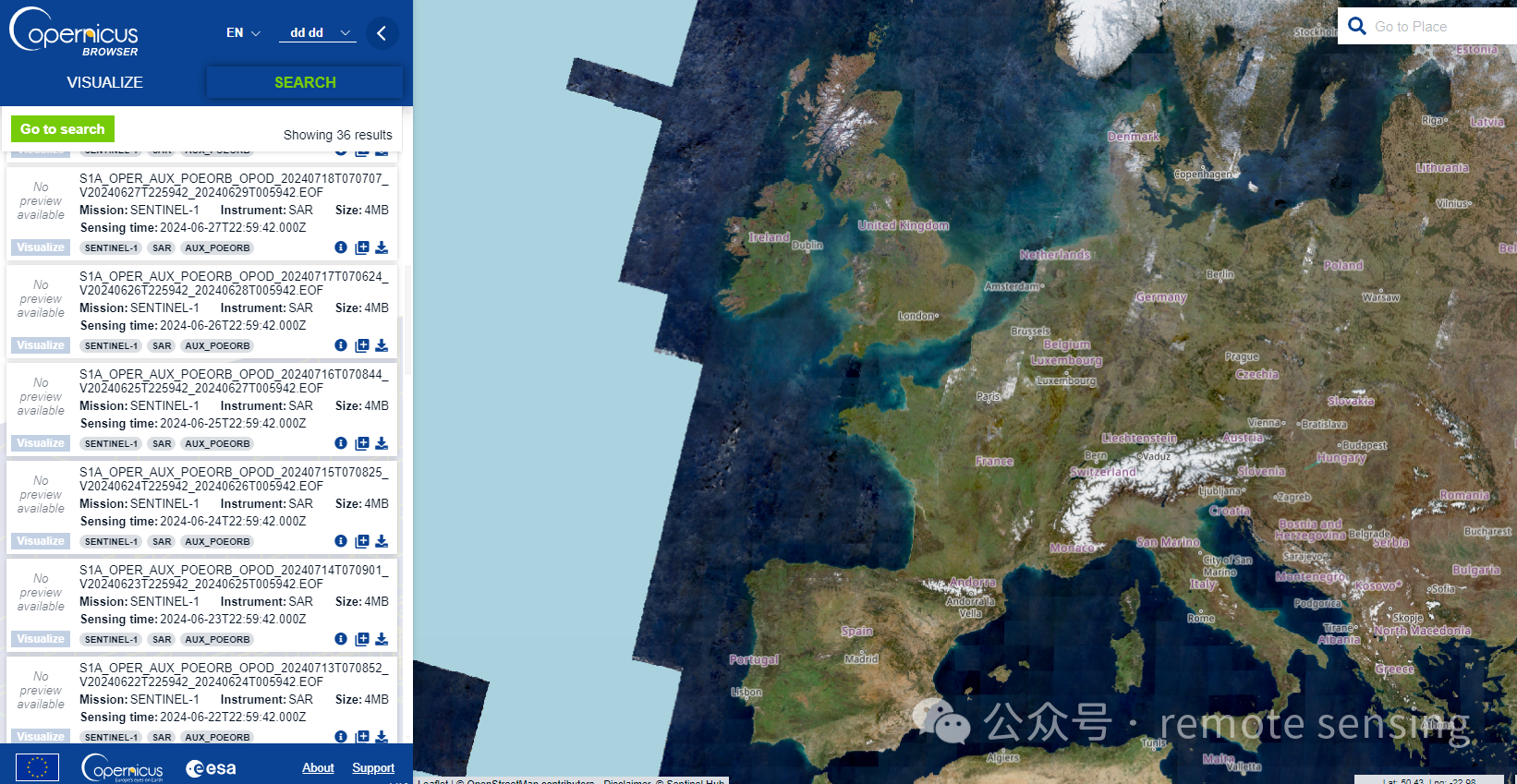
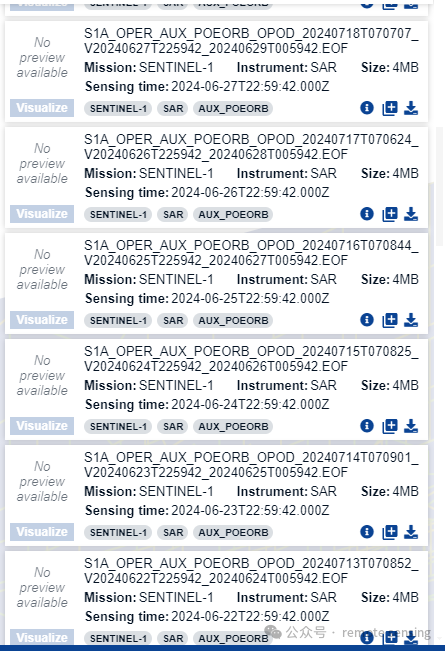
把下拉条拉到最后,选择轨道数据的时间范围,然后点击Search按钮
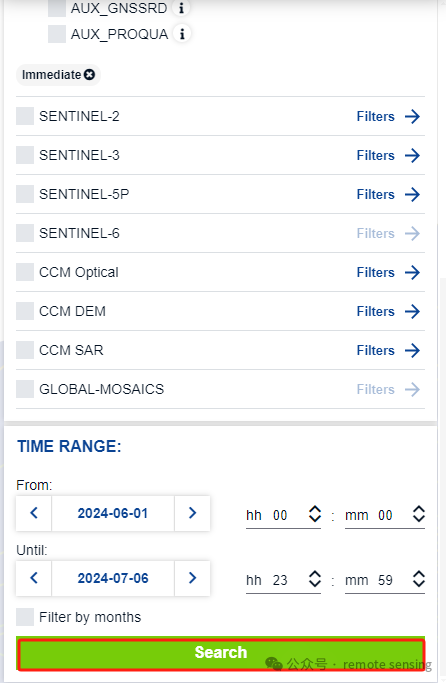
此时,出现很多轨道数据,按照规则选中我们需要的轨道数据进行下载。
这篇关于手动下载Sentinel-1卫星精密轨道数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






