本文主要是介绍关于synchronized与volatile的一点认识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
贪婪是一种原罪,不要再追求性能的路上离正确越来越远。
- 内存模型
- java内存模型
- 重排序
- 锁synchronized
- 什么是锁
- 独占锁
- 分拆锁
- 分离锁
- 分布式锁
- volatile
内存模型
java内存模型
提到同步、锁,就必须提到java的内存模型,为了提高程序的执行效率,java也吸收了传统应用程序的多级缓存体系。
在共享内存的多处理器体系架构中,每个处理器都拥有自己的缓存,并且定期地与主内存进行协调。在不同的处理器架构中提供了不同级别的缓存一致性(Cache Coherence),其中一部分只提供最小的保证,即允许不同的处理器在任意时刻从同一个存储位置上看到不同的值。操作系统、编译器以及运行时(有时甚至包括应用程序)需要弥合这种在硬件能力与线程安全之间的差异。

要想确保每个处理器都能在任意时刻知道其他处理器正在进行的工作,将需要非常大的开销。在大多数时间里,这种信息是不必要的。因此处理器会适当放宽存储一致性保证,以换取性能的提升。在架构定义的内存模型中将告诉应用程序可以从内存系统中获得怎样的保证,此外还定义了一些特殊的指令(称为内存栅栏),当需要共享数据时,这些指令就能实现额外的存储协调保证。为了使java开发人员无须关心不同架构内存模型之间的差异,Java还提供了自己的内存模型,并且JVM通过在适当的位置上插入内存栅栏来屏蔽在JVM与底层之平台内存模型之间的差异。
经过上面的讲解和上图,我们知道线程在运行时候有一块内存专用区域,Java程序会将变量同步到线程所在的内存。这时候会操作工作内存中的变量,而线程中的变量何时同步回到内存是不可预期的。但是java内存模型规定,通过关键词”synchronized“、”volatile“可以让java保证某些约束。
重排序
public class PossibleReordering {static int x = 0,y=0;static int a=0,b=0;public static void main(String[] args) throws InterruptedException {Thread one = new Thread(new Runnable() {@Overridepublic void run() {a = 1;x = b;}});Thread two = new Thread(new Runnable() {@Overridepublic void run() {b = 2;y = a;}});one.start();two.start();one.join();two.join();System.out.println("x:" + x+",y:"+y);}
}
重排序。如上图,执行结果,一般人可能认为是1,1;真正的执行结果可能每次都不一样。拜JMM重排序所赐,JMM使得不同线程的操作顺序是不同的,从而导致在缺乏同步的情况下,要推断操作的执行结果将变得更加复杂。各种使操作延迟或看似乱序执行的不同原因,都可以归为重排序。内存级的重排序会使程序的行为变得不可预测。如果没有同步,要推断出程序的执行顺序是非常困难的,而要确保在程序中正确的使用同步却是非常容易的。同步将限制编译器和硬件运行时对内存操作重排序的方式。
锁synchronized
锁实现了对临界资源的互斥访问,被synchronized修饰的代码只有一条线程可以通过,是严格的排它锁、互斥锁。没有获得对应锁对象监视器(monitor)的线程会进入等待队列,任何线程必须获得monitor的所有权才可以进入同步块,退出同步快或者遇到异常都要释放所有权,JVM规范通过两个内存屏障(memory barrier)命令来实现排它逻辑。内存屏障可以理解成顺序执行的一组CPU指令,完全无视指令重排序。
什么是锁
public class TestStatic {public syncronized static void write(boolean flag) {xxxxx}public synchronized static void read() {xxxxx}
}
线程1访问TestStatic.write()方法时,线程2能访问TestStatic.read()方法吗
线程1访问new TestStatic().write()方法时,线程2能访问new TestStatic().read()方法吗
线程1访问TestStatic.write()方法时,线程2能访问new TestStatic().read()方法吗
public class Test {public syncronized void write(boolean flag) {xxxxx}public synchronized void read() {xxxxx}
}
Test test = new Test();线程1访问test.write() 方法,线程2能否访问test.read()方法
Test a = new Test(); Test b = new Test();线程1访问a.write()访问,线程2能否访问b.read()方法
答案,java中每个对象都可以作为一个锁,而对象就决定了锁的粒度大小。
对于实例同步方法,锁是当前对象。
对于静态方法,锁是TestSTatic.class对象
对于同步代码块,锁是Synchronized括号里面配置的对象
TestStatic类,1问,作用范围全体class对象,线程1拿到,线程2就不能拿到
2问,3问同上
Test类,1问,不能,锁都是实例对象test,线程1拿到锁之后,线程2无法访问
2问,可以,线程1锁是实例a,线程2是实例b。
独占锁
如果你不敢确定该用什么锁,就用这个吧,在保证正确的前提下,后续在提高开发效率。
public class ServerStatus {public final Set<String> users;public final Set<String> quers;public synchronized void addUser(String u ) {users.add(u);}public synchronized void addQuery(String q ) {quers.add(q);}public synchronized void removeUser(String u) {users.remove(u);}public synchronized void removeQuery(String q) {quers.remove(q);}
}
分拆锁
如果在整个应用程序只有一个锁,而不是为每个对象分配一个独立的锁,那么所有同步代码块的执行就会变成串行化执行。由于很多线程都会竞争同一个全局锁,因此两个线程同时请求这个锁的概率将会剧增,从而导致更严重的竞争。所以如果将这些锁请求分到更多的锁上,就能有效降低锁竞争程度。由于等待而被阻塞的线程将更少,从而可伸缩性将提高。
上文中users、quers是两个相互独立的变量,可以将此分解为两个独立的锁,每个锁只保护一个变量,降低每个锁被请求的频率。
public class ServerStatus {public final Set<String> users;public final Set<String> quers;public void addUser(String u ) {synchronized(users) {users.add(u);}}public void addQuery(String q ) {synchronized(quers) {quers.add(q);}}public void removeUser(String u) {synchronized(users) {users.remove(u);}}public void removeQuery(String q) {synchronized(quers) {quers.remove(q);}}
}
分离锁
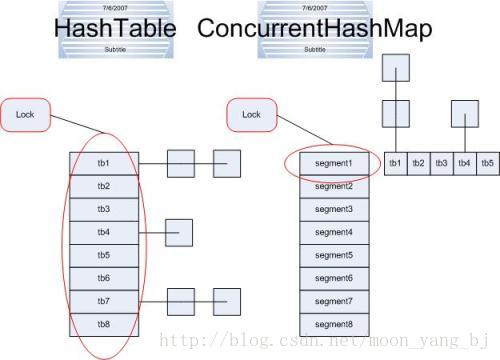
在某些情况下,可以将锁分解技术进一步扩展为对一组独立对象上的锁进行分解,这种情况称为锁分段。例如ConcurrencyHashMap是有一个包含16个锁的数组实现,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。假设所有关键字都时间均与分布,那么相当于把锁的请求减少到原来的1/16,可以支持多达16个的并发写入。
锁分段的劣势在于:与采用单个锁来实现独占访问相比,要获取多个锁来实现独占访问将更加困难并且开销更高,比如计算size、重hash。
分布式锁
zookeeper,判断临时节点是否存在,存在就说明已经有人争抢到锁;不存在就创建节点,表明拥有该锁。
记下,以后详细研究
https://github.com/qhwj2006/ZookeeperDistributedLock
https://github.com/s7/scale7-cages
volatile
volatile是比synchronized更轻量级的同步原语,volatile可以修饰实例变量、静态变量、以及数组变量(网上大牛说,维护的是引用,但是里面的对象。。。嘿嘿嘿)。被volatile修饰的变量,JVM规范规定,一个线程在修改完,另外的线程能读取最新的值。
但仅仅保证可见性,不保证原子性,所以volatile通常用来修饰boolean类型或者状态比较少的数据类型,而且不能用来更新依赖变量之前值的操作(例volatile++)。
volatile内部仅仅是对变量的操作多了一条cpu指令(lock#指令),它会强制写数据到缓存,如果缓存数据同时也在主存,会强制写数据更新到主存,并且使所有持有该主存数据地址的缓存统统失效,触发其他持有缓存数据的线程从主存获取最新数据,从而实现同步。
这篇关于关于synchronized与volatile的一点认识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






