本文主要是介绍论文笔记 Fast R-CNN细节,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当我决心认真地看Faster R-CNN代码的时候,我就觉得有必要把 Fast R-CNN的论文的细节再从新完整地看一遍了。对,是细节,如何实现的部分,于是有了此篇博客。请注意是 Fast R-CNN笔记。
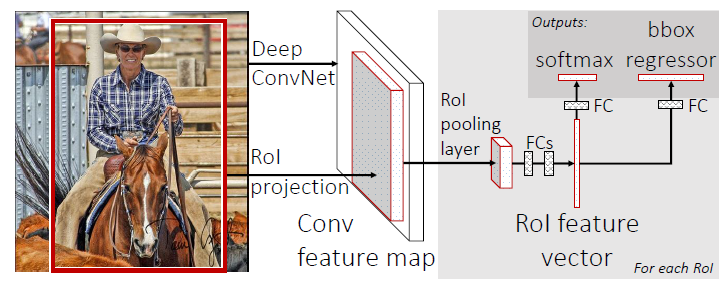
其网络结构流程如上图,将整个图片输入卷积层和pooling层,得到卷积层特征图。然后针对每一个proposal带来的感兴趣区域RoI,通过RoI pooling layer得到在特征图中RoI区域部分,通过全连接层得到特征向量。
网络结构与训练
RoI pooling layer:
该层主要将感兴趣区域提取出来单独进行max pooling操作得到一个H*W(如7*7)的固定大小的小的特征图。文章中的RoI主要是卷积层特征图中的一个矩形窗口。每一个RoI用四维量表示(r,c,h,w),(r,c)是top-left点坐标,(h,w)是RoI的高和宽。因此,该层的操作主要是将h*w大小的RoI通过池化操作,变成一个H*W大小的特征图。
预训练模型初始化:
主要实验了三种情况,每次都是使用5个max pooling 层和3-5层卷积层。第一种直接将最后一个max pooling层变成RoI pooling层,第二种网络最后的全连接层和softmax层替换成上图中的结构,第三种修改网络使其分别输入图像和RoI两种数据。
Fine-tuning for detection:
本文的重点部分。在训练部分采用分层次的SGD(随机梯度下降)方法:先对N张图像进行采样,然后对每张图像中的R/N个RoI区域进行采样。同一张图中的RoI共享前后向传播中的计算和内存。这里N的值比较小,从而可以使得计算量下降。例如,使用N=2,R=128,提出的想法即比对一个RoI在不同的128张图中采样快64倍(R-CNN和SPPnet中的策略)。
对于分层次采样,Fast R-CNN使用一个流水地训练过程,同时加入fine-tunning方法加入softmax分类器和bounding box回归,而不是说直接训练一个softmax分类器啊,SVM啊回归啊等等,这样使得整个过程的计算机大大减少。
(1)Multi-task loss:
对于Fast R-CNN输出的两个姊妹输出层,第一个输出每一个RoI对于K+1类别的离散概率分布p=(p0,...,pk),其中,p通过全连接层K+1个输出后的softmax层计算得到。第二个输出bounding box回归补偿每一个类别k下的补偿t=(tx,ty,tw,th)。
因此,对于每一个训练RoI,都得到一个ground truth类别u和bounding box回归坐标v。作者使用一个多任务的loss来结合训练的类别和bounding box回归loss如下:
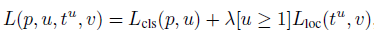
其中,前部分为class的loss:
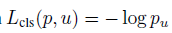
后部分为ground truth的bounding box坐标和预测坐标的loss,其中当u大于等于1时均取1:
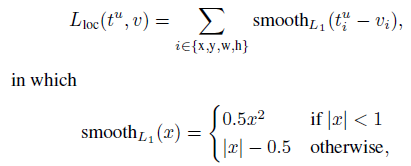
(2)Mini-batch sampling:
在fine-tuning过程中,每一个SGD mini-batch都在N=2张影像上进行实施,同时R=128,在每张影像上采样64个RoI。类似R-CNN,从proposal中与ground truth 的IoU大于0.5的,作为部分RoI,这部分RoI占完整RoI的25%。其由类别标签u大于1的组成(前景目标)。其他的RoI从proposal和gt的IoU在[0.1 0.5)中选择,类似SPPnet情况,这里最小的阈值0.1作为类似hard example mining的探索,训练时图像被水平旋转作为数据变换。
(3)Back-propagation through RoI pooling layers:
RoI pooling layers的反向传播部分,主要通过其得到的特征图回传找出每个pooling后特征图中像素位于哪些RoI区域,找到对应的RoI区域中的max pooling取到的点,进行loss的叠加计算,具体公式如下:
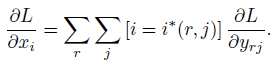
等于每一个mini-batch的RoI:r ,和其pooling后的输出单元:yrj,找到其max pooling中实际取到的最大值的点,进行loss的叠加。
Scale invariance:
两种多尺度方法:(1)通过训练本身学习到训练数据的多尺度(2)通过影像金字塔提供多尺度的结果。
Detection部分
Truncated SVD for faster detection:
检测部分主要通过网络的前向部分传播即可实现,同时作者提出了用缩短的SVD(奇异值分解)加速的方法。
对于近一半的计算全连接层部分的时间消耗,作者提出truncated SVD方法解决。具体公式:


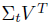 ,第二个计算U,来完成整个W的计算。在RoI很大时候,这样计算可以大大加快速度。
,第二个计算U,来完成整个W的计算。在RoI很大时候,这样计算可以大大加快速度。
这篇关于论文笔记 Fast R-CNN细节的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




