本文主要是介绍elephant-bird的使用示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
elephant-bird的使用示例
一、简要概述
在近期项目的开发中,由于处理数据量巨大,为了减少HDFS的存储压力以及提高MapReduce的运算效率,故采用了protoc buffer序列化和lzo压缩机制。在项目中采用了这两种机制后,整个集群的存储压力及运算效率得到了明显的改善。但在开发中,我们需要分别根据protobuf的配置文件xxx.proto所定义的消息结构(也就是数据类型)来自己手动实现Hadoop org.apache.hadoop.io.WritableComparable,以及InputFormat和OutputFormat.,同时也要手动加入lzo压缩处理,这样一来,工作量就会变得非常巨大,但elephant-bird很好的替代了这方面的工作。它能基于protocol buffer的proto文件,以及thrift的thrift文件生成对应的Writable,InputFormat以及OutputFormat.需要lzo压缩以及64位编码也没关系,照样都支持.如此省去了你自己去写这些代码的麻烦,而且写这些代码都是机械性的,所以也就有了elephant-bird的存在性。
如果,大家对protobuf、thrift、lzo有不了解的话,可以参看本人的博客,进入对应的博客分类里面,即可查看到。
二、环境搭建
1.环境说明:
在如下的使用示例中,需要你的机器上安装ant以及protocol buffer(本例中Thrift暂不使用)。如果,大家没安装的话,可以参看本人的博客把环境搭建好。
对于使用elephant-bird,我们只需要使用elephant-bird提供的可执行jar包即可根据要求生产自己想要的代码。
2.下载elephant-bird相关jar包
(1).可以通过git从git clone git://github.com/kevinweil/elephant-bird.git clone一份工程
(2).下载本人的连接:
1.创建工程,结构如下:
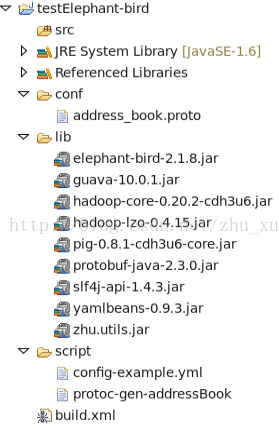
1.将上图展示的各种jar放入工程。
2.新建address_book.proto文件,内容如下:
package org.zhu.elephantBird.proto;option java_outer_classname = "AddressBookProtos";message Person {required string name = 1;required int32 id = 2;optional string email = 3;enum PhoneType {MOBILE = 0;HOME = 1;WORK = 2;}message PhoneNumber {required string number = 1;optional PhoneType type = 2 [default = HOME];}repeated PhoneNumber phone = 4;
}message AddressBook {repeated Person person = 1;
}<!--默认执行target2:generate-protobufANDelephant-bird-->
<project name="elephant-bird-study" basedir="." default="generate-protobufANDelephant-bird"><property name="src.proto.dir" location="./conf" /><property name="src.gen.java.dir" location="${src.dir}/gen-java" /><!--target 1:只生成protobuf代码--><target name="generate-protobuf"><delete dir="${src.gen.java.dir}" /><mkdir dir="${src.gen.java.dir}" /><apply executable="protoc" failοnerrοr="true" skipemptyfilesets="true" verbose="true"><arg value="--proto_path=${src.proto.dir}" /><arg value="--java_out=${src.gen.java.dir}" /><fileset dir="${src.proto.dir}" includes="addressBook.proto" /></apply></target><!--target 2:生成protobuf代码和elephant-bird代码--><!--增加了<env key="PATH" path="${env.PATH}:${basedir}/script" />,表示将刚才新建的$YOUR_PROJECT_HOME/script下的文件放入path中 增加了参数<arg value="- -example_out=${src.gen.java.dir}" />,这里elephant-bird有个奇怪的规则,参数名为- -example_out,其中example存在规则,他将跟protoc-gen-组成protoc-gen-example做为Protocol Buffer调用elephant-bird的脚本文件名. --><target name="generate-protobufANDelephant-bird" ><delete dir="${src.gen.java.dir}"/><mkdir dir="${src.gen.java.dir}"/><apply executable="protoc" failοnerrοr="true" skipemptyfilesets="true" verbose="true" ><env key="PATH" path="${env.PATH}:${basedir}/script" /><arg value="--proto_path=${src.proto.dir}" /><arg value="--java_out=${src.gen.java.dir}" /><!--注意:下面的“- -addressBook_out”中的“addressBook”部分的名称要和script目录下的"protoc-gen-addressBoo的中"addressBook"部分保持一致,否则会报找不到脚本错误--><arg value="--addressBook_out=${src.gen.java.dir}" /><fileset dir="${src.proto.dir}" includes="address_book.proto" /></apply></target></project>4.编写config-example.yml文件:
#通过指定代码生成器类型(具体的生成代码的类)配置elephant-bird生成的代码类型
#注意下面的"address_book"标识要和conf目录下的address_book.proto的名称(不包括后缀名.proto)保持一致
#否则会报配置文件(即此文件,config-example.yml)和xxx.proto文件不匹配错误
#如下配置将生成mapreduce、pig相关的实现代码
address_book:- com.twitter.elephantbird.proto.codegen.DeprecatedLzoProtobufBlockInputFormatGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufB64LineInputFormatGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufB64LineOutputFormatGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufBlockInputFormatGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufBlockOutputFormatGenerator- com.twitter.elephantbird.proto.codegen.ProtobufWritableGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufB64LinePigLoaderGenerator- com.twitter.elephantbird.proto.codegen.LzoProtobufBlockPigLoaderGenerator
# - com.twitter.elephantbird.proto.codegen.LzoProtobufHiveSerdeGenerator- com.twitter.elephantbird.proto.codegen.ProtobufBytesToPigTupleGenerator5.编写protoc-gen-addressBook脚本文件:
#!/bin/bash
#调用java命令执行elephant-bird的代码生成引擎(com.twitter.elephantbird.proto.HadoopProtoCodeGenerator)
#按照配置文件config-example.yml来生成制定类型的代码/usr/bin/java -cp ./lib/*: com.twitter.elephantbird.proto.HadoopProtoCodeGenerator ./script/config-example.yml -编写以上配置文件的注意事项:
(1).请保证build.xml文件中的<arg value="--addressBook_out=${src.gen.java.dir}" />中的“addressBook”部分的名称要和script目录下的"protoc-gen- addressBoo的中"addressBook"部分保持一致,否则会报找不到脚本错误
(2).请保证config-example.yml文件中的"address_book"标识要和conf目录下的address_book.proto的名称(不包括后缀名.proto)保持一致
否则会报配置文件(即此文件,config-example.yml)和xxx.proto文件不匹配错误
6.通过ant生成代码:
可以通过执行ant命令(需要进入当前工程的工作目录)或者在eclipse中,在built.xml页面中右击鼠标,点击"run as ant"来运行程序生成代码。
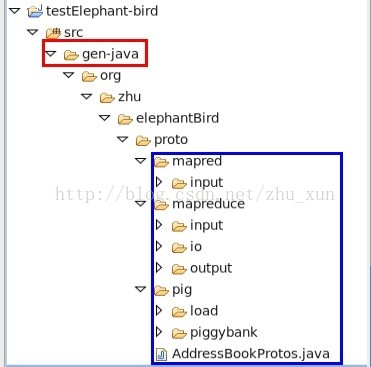
如无意外的话,你的工程下的src包下会生成如下一坨代码
这篇关于elephant-bird的使用示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





